一文搞懂DeepSeek-V3_MLA注意力机制
DeepSeek-V3:多头潜在注意力(MLA)
MLA是DeepSeek-V2 和 DeepSeek-V3 背后的关键架构创新,可实现更快的推理。
DeepSeek-V3 的主要架构创新,包括 MLA(多头潜在注意力)、DeepSeekMoE、辅助无损负载均衡(auxiliary-loss-free load balancing)和多标记预测训练(multi-token prediction training)。
本文讲解的MLA技术,在 DeepSeek-V2 的开发中被提出,后来也被用于 DeepSeek-V3 中。
论文地址: DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
为了搞懂MLA,我们从标准的 MHA 开始,解释为什么我们在推理阶段需要 Key-Value 缓存,MQA 和 GQA 如何尝试优化它,以及 RoPE 是如何工作的,等等。然后,深入介绍 MLA,包括其动机、为什么需要解耦 RoPE 及其性能。
DeepSeek-V3介绍¶
DeepSeek-V3 的模型结构与 DeepSeek-V2 一致,采用了 MLA + DeepSeekMoE,总参数 671B,激活参数 37B。总共 61 层,Hidden 维度为 7168
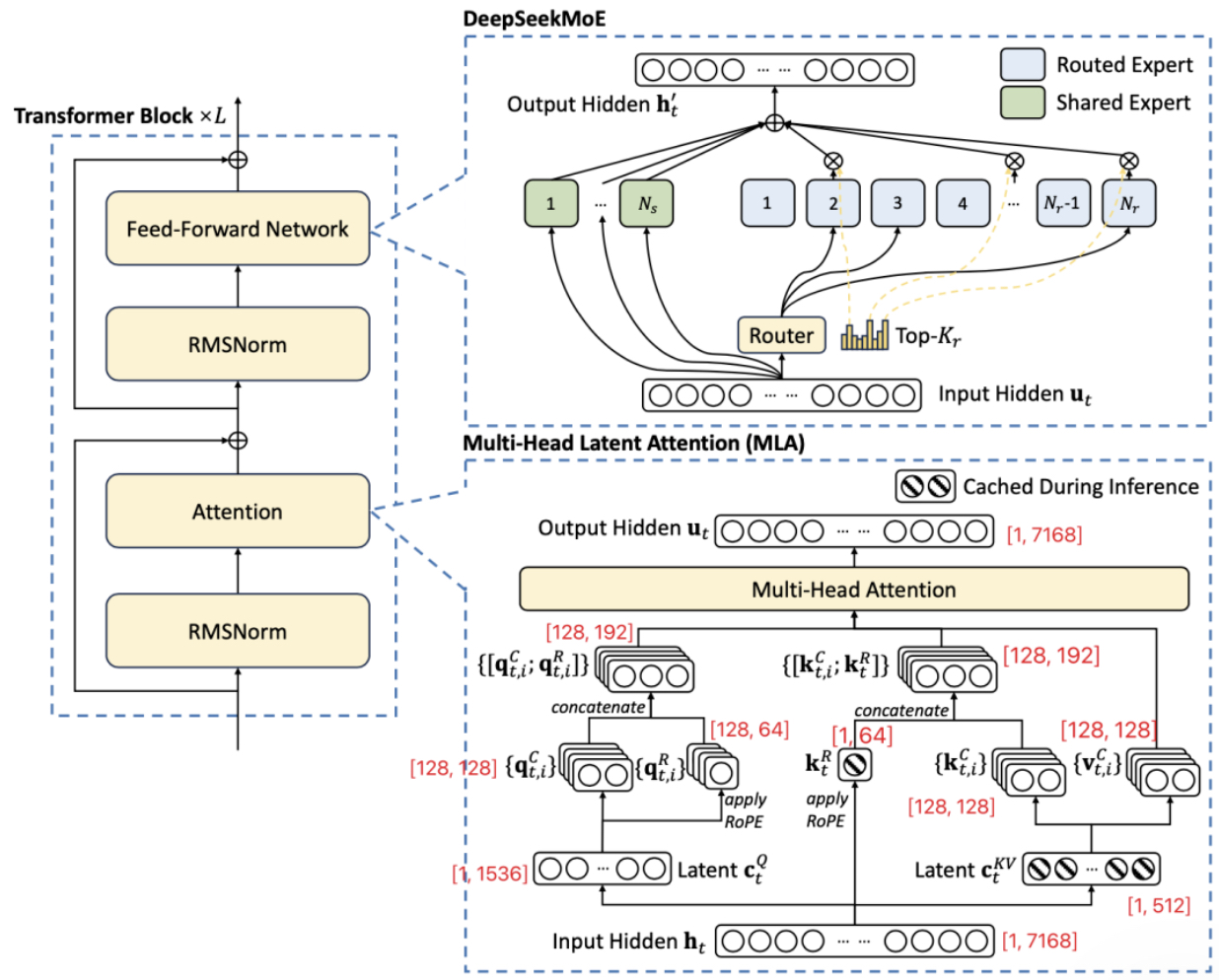
- Attention Head 个数 n_h:128
- 每个 Head 的维度 d_h:128(非 MLA 时,n_h * d_h = Hidden 维度;而 MLA 中,d_h 大于 Hidden 维度 / n_h,比如图中的 128 > 7168/128 = 56)
- KV 压缩维度 (c_t^{KV}):512
- Q 压缩维度(c_t^Q):1536
- 解耦的 Q 和 K(RoPE)的维度:64
背景知识¶
Transformers解码器中的MHA¶
MLA 的开发是为了加快自回归文本生成的推理速度,因此我们在此上下文中讨论的 MHA 仅适用于 Transformer Decoder(解码器)。
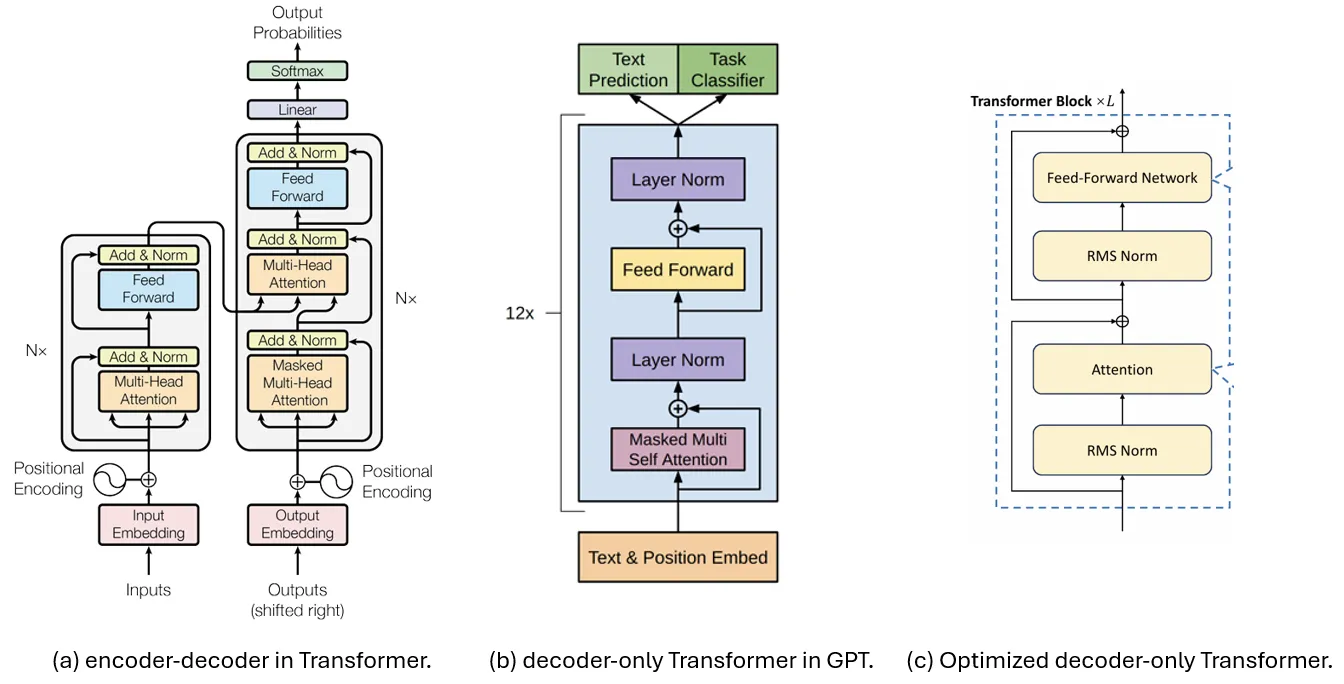
下图比较了用于解码的三种 Transformer 架构,其中 (a) 显示了原始论文“Attention is All You Need”中提出的编码器和解码器。然后通过简化其解码器部分,从而得到 (b) 所示的仅解码器的 Transformer 模型,该模型后来被用于许多生成模型,如 GPT。
如今,LLM 更普遍地选择 (c) 中所示的结构以获得更稳定的训练,对输入而不是输出进行归一化,并将 LayerNorm 升级到 RMS Norm。这将作为我们将在本文中讨论的基准架构。
在这种情况下,MHA 计算主要遵循中的过程,如下图所示:
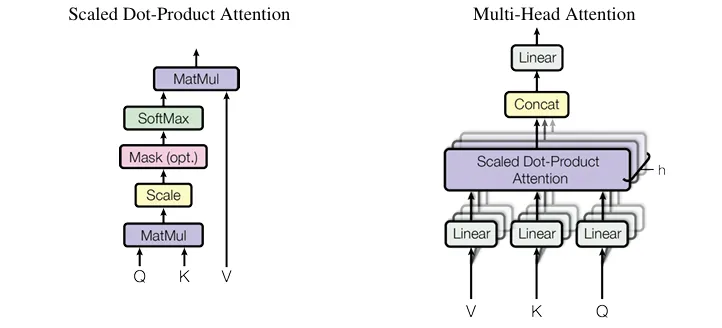
假设我们有 n_h 个注意头,并且每个注意头的维度都表示为 d_h,因此连接的维度将为 (n_h ·d_h)。
给定一个具有 l 层的模型,如果我们将该层中第 t 个标记(token)的输入表示为 维数为 d 的 h_t ,则需要使用线性映射矩阵将 h_t 的维数从 d 映射到 (n_h ·d_h)。如下图方程所示:
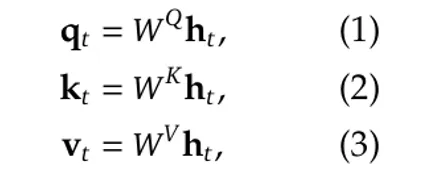
其中 W^Q、W^K 和 W^V 是线性映射矩阵。
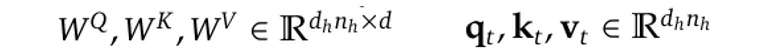
在这样的映射之后,q_t、k_t 和 v_t 将被分成 n_h 个头来计算缩放的点积注意力:
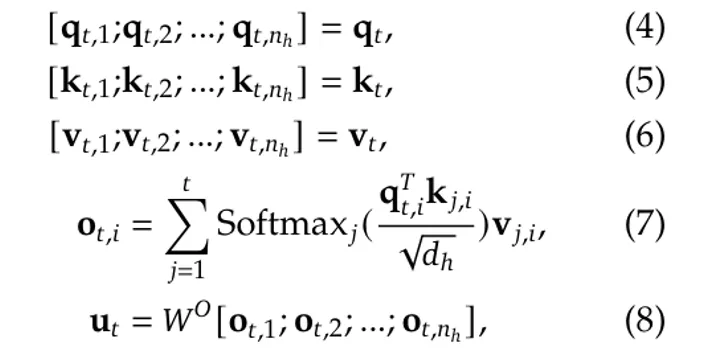
其中 W^O 是另一个投影矩阵,用于从 (n_h ·d_h)至 d 的映射。
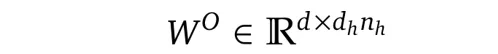
请注意,上述方程 (1) 至 (8) 描述的过程仅适用于单个token。在推理过程中,我们需要对每个新生成的 Token 重复这个过程,这涉及到大量的重复计算。这导致了一种称为 Key-Value 缓存的技术。
Key-Value 缓存¶
Key-Value cache 是一种旨在通过缓存和重用以前的 key 和 values 来加速自回归过程的技术,而不需要在每个解码步骤中重新计算它们。KV 缓存通常仅在推理阶段使用,用于加速推理,因为在训练中,我们仍然需要并行处理整个输入序列。
KV 缓存通常通过rolling buffer实现。在每个解码步骤中,只计算新的查询 Q,而存储在缓存中的 K 和 V 将被重用,因此将使用新的 Q 和缓存的 K、V 来计算注意力。同时,新 Token 的 K 和 V 也会被追加到缓存中,供以后使用。
然而,KV 缓存实现的加速是以内存为代价的,因为 KV 缓存的大小和 批处理大小×序列长度×hidden数×head数(batch size × sequence length × hidden size × number of heads) 息息相关,当我们拥有更大的批处理大小或更长的序列时,会导致内存瓶颈。
为了解决这个问题,推出了两种旨在解决此限制的技术:Multi-Query Attention(MQA) 和 Grouped-Query Attention(GQA)。
多查询注意力机制 (MQA) vs 分组查询注意力机制 (GQA)¶
下图显示了原始 MHA、分组查询注意力 (GQA) 和多查询注意力 (MQA) 之间的比较。
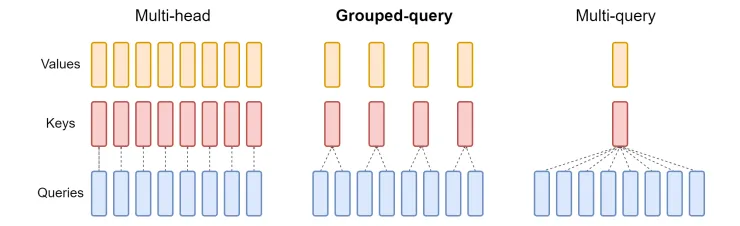
MQA 的基本思想是在所有查询头之间共享单个 key 和单个值头,这可以显著的减少内存使用,但也会影响 attention 的准确性。
GQA 可以看作是 MHA 和 MQA 之间的一种插值方法,其中一对键和值头将仅由一组查询头共享,而不是由所有查询共享。但与 MHA 相比,这仍然会导致较差的结果。
然后就引入了,MLA技术如何设法在内存效率和模型准确率之间寻求平衡。
RoPE (Rotary Positional Embeddings) 旋转位置嵌入技术¶
我们需要提到的最后一点背景是 RoPE ,它通过使用正弦函数旋转多头注意力中的Query和Key向量,将位置信息直接编码到注意力机制中。
更具体地说,RoPE 将位置相关的旋转矩阵应用于每个Token处的Query和Key向量,并使用正弦和余弦函数作为其基础,以独特的方式应用它们来实现旋转。
下面用一个例子,来学习RoPE技术。
要了解是什么使它依赖于位置,请考虑一个只有 4 个元素的玩具嵌入向量(embedding vector),即 (x_1、x_2、x_3、x_4)。
为了应用 RoPE,我们首先将连续维度分组为一对数据:
- (x_1、x_2) -> 位置 1
- (x_3、x_4) -> 位置 2
然后,我们应用一个旋转矩阵来旋转每对数据,如下所示:
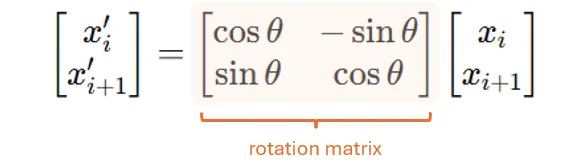
其中 θ=θ(p)=p⋅θ_0 ,θ_0 是基频。在我们的4维玩具示例中,这意味着 (x_1, x_2) 将旋转 θ_0,而 (x_3, x_4) 将旋转 2⋅θ_0。
这就是为什么我们称这个旋转矩阵为位置相关矩阵:在每个位置(或每对数据)处,我们将应用不同的旋转矩阵,其中旋转角度由位置决定。
RoPE 因其编码长序列的效率而广泛用于现代 LLM,但从上面的公式中我们可以看出,它对 Q 和 K 都对位置敏感,这使得它在某些方面与 MLA 不兼容。
Multi-head Latent Attention 多头潜在注意力机制¶
通过上面的背景知识介绍,我们可以继续讨论 MLA 部分。在本节中,我们将首先概述 MLA 的高级概念,然后更深入地探讨为什么它需要修改 RoPE。最后,我们介绍了 MLA 的详细算法及其性能。
MLA 技术思想¶
MLA 的基本思想是将注意力输入h_t压缩成维数为 d_c 的低维潜在向量,其中 d_c 远低于原始向量 (n_h ·d_h)。稍后当我们需要计算注意力时,我们可以将这个 latent vector 映射回高维空间,以恢复 key 和 value。因此,只需要存储 latent vector ,从而显著减少内存。
这个过程可以用以下方程式描述,其中 c^{KV}_t 是潜在向量,W^{DKV} h_t是从 (h_n ·d_h)到 d_c(此处上标中的 D 代表“向下投影”,意思是压缩维度),而 W^{UK} 和 W^{UV} 都是向上投影矩阵,它们将共享的潜在向量映射回高维空间。
这个过程可以用以下方程式更正式地描述,其中 c^{KV}_t 是潜在向量,W^{DKV} 是h_t从 (h_n ·d_h)到 d_c投影的压缩矩阵(此处上标中的 D 代表“向下投影”,意思是压缩维度),而 W^{UK} 和 W^{UV} 都是向上投影矩阵,它们将共享的潜在向量映射回高维空间。

同样,我们也可以将Query映射到一个潜在的低维向量,然后将其映射回原始的高维空间:

为什么需要解耦的RoPE¶
正如我们之前提到的, RoPE 是训练生成模型处理长序列的常见选择。如果我们直接应用上述 MLA 策略,那将与 RoPE 不兼容。
为了更清楚地看到这一点,请考虑一下当我们使用前面提到的方程(7)计算注意力时会发生什么:当我们将转置的 q 与 k 相乘时,矩阵 $ W^Q $ 和 $ W^{UK} $ 将出现在中间,它们的组合等价于从 d_c 到 d 的单个映射维度。
矩阵的转置计算:$$ (ABC…XYZ)^T = Z^{T} Y^{T} X^{T} … C^{T} B^{T} A^{T} $$
在原始论文 中,作者将其描述为 W^{UK} 可以被“吸收”到 W^Q 中,因此我们不需要将 W^{UK} 存储在缓存中,进一步减少了内存使用。
但是,当我们考虑上图中提到的旋转矩阵时,情况并非如此,因为 RoPE 将在 W^{UK} 的左侧应用旋转矩阵,并且该旋转矩阵最终将位于转置的 W^Q 和 W^{UK} 之间。
正如我们在背景部分所解释的那样,这个旋转矩阵是与位置相关的,这意味着每个位置的旋转矩阵都不同。因此,W^{UK} 不能再被 W^Q 吸收。
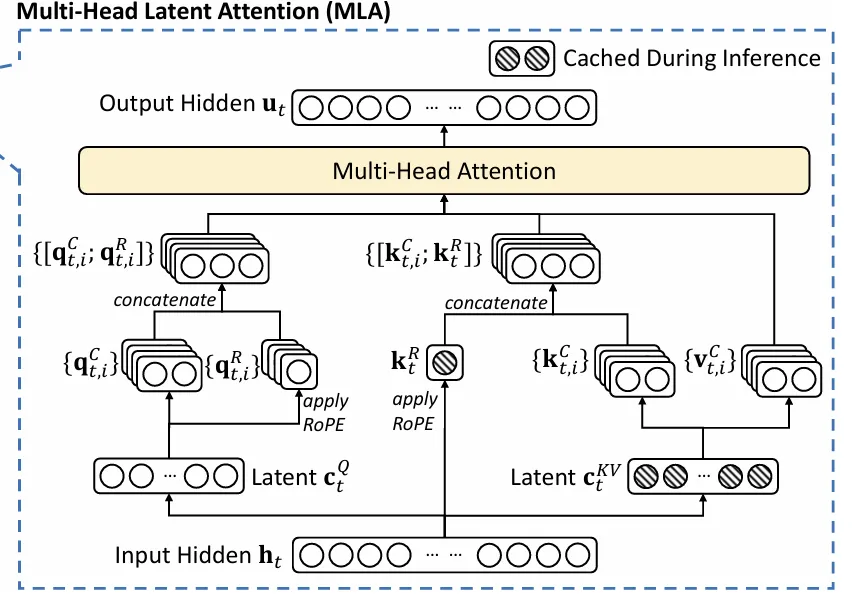
为了解决这一冲突,作者提出了他们所谓的“解耦 RoPE”,通过引入额外的query向量和共享的Key向量,并且仅在 RoPE 过程中使用这些额外的向量,同时保持原始Key与旋转矩阵隔离。
MLA 的整个过程可以总结如下:
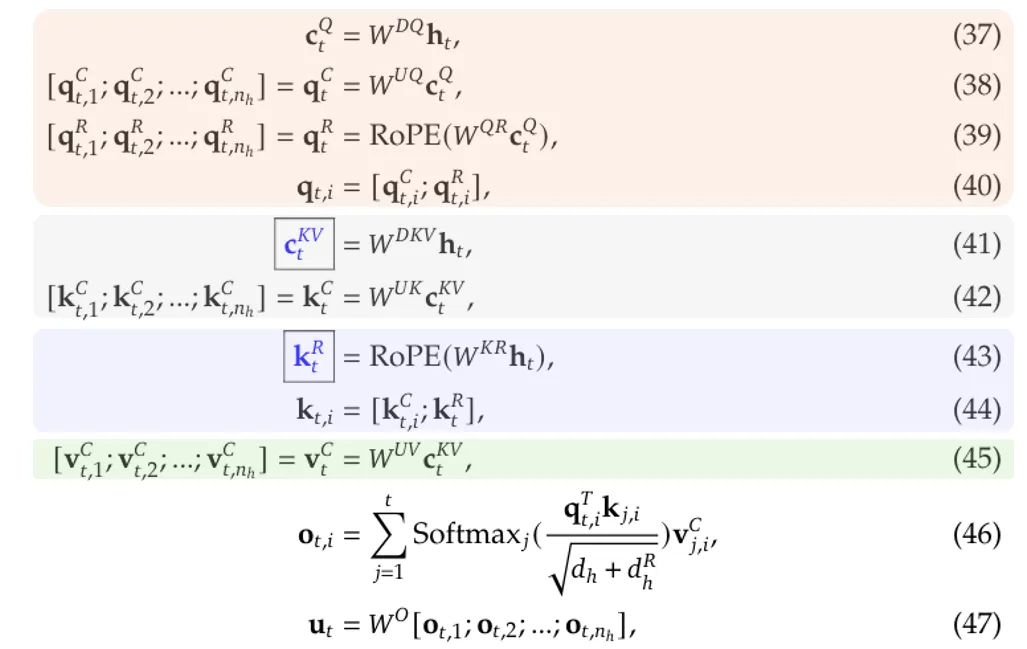
-
等式 (37) 到 (40) 描述如何处理查询标记。
-
等式 (41) 和 (42) 描述了如何处理key tokens。
-
等式 (43) 和 (44) 描述了如何为 RoPE 使用额外的共享key,请注意 (42) 的输出不涉及 RoPE。
-
方程 (45) 描述了如何处理value tokens。
在此过程中,只需要缓存带有框的蓝色变量。对于每一个 Token,推理时在每一个 Transformer Layer 需要缓存的蓝色的两个方块Cache,大小为 512+64=576。而标准 MHA 需要缓存的大小为 2 * Hidden 维度 ,即 2*7168=14336,也就是 DeepSeek V3 的 MLA 的 Cache 大小只有 MHA 的 1/25。
这个过程可以用流程图更清楚地说明:
MLA性能比较¶
下表比较了 KV 缓存所需的元素数量(每个Token)以及 MHA、GQA、MQA 和 MLA 之间的建模能力,表明 MLA 确实可以在内存效率和建模能力之间实现更好的平衡。
有趣的是,MLA 的建模能力甚至超过了原始 MHA。

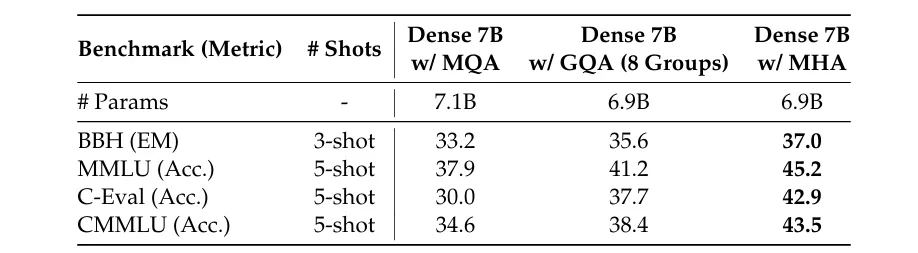
更具体地说,下表显示了 MHA、GQA 和 MQA 在 7B 型号上的性能,其中 MHA 明显优于 MQA 和 GQA。
作者在文章中Table-9还对 MHA 与 MLA 进行了分析,结果总结在下表中,其中 MLA 总体上取得了更好的结果。

(MLA核心内容来源于DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model和译自deepseek-v3-explained-1-multi-head-latent-attention, 并结合其他资料解释)