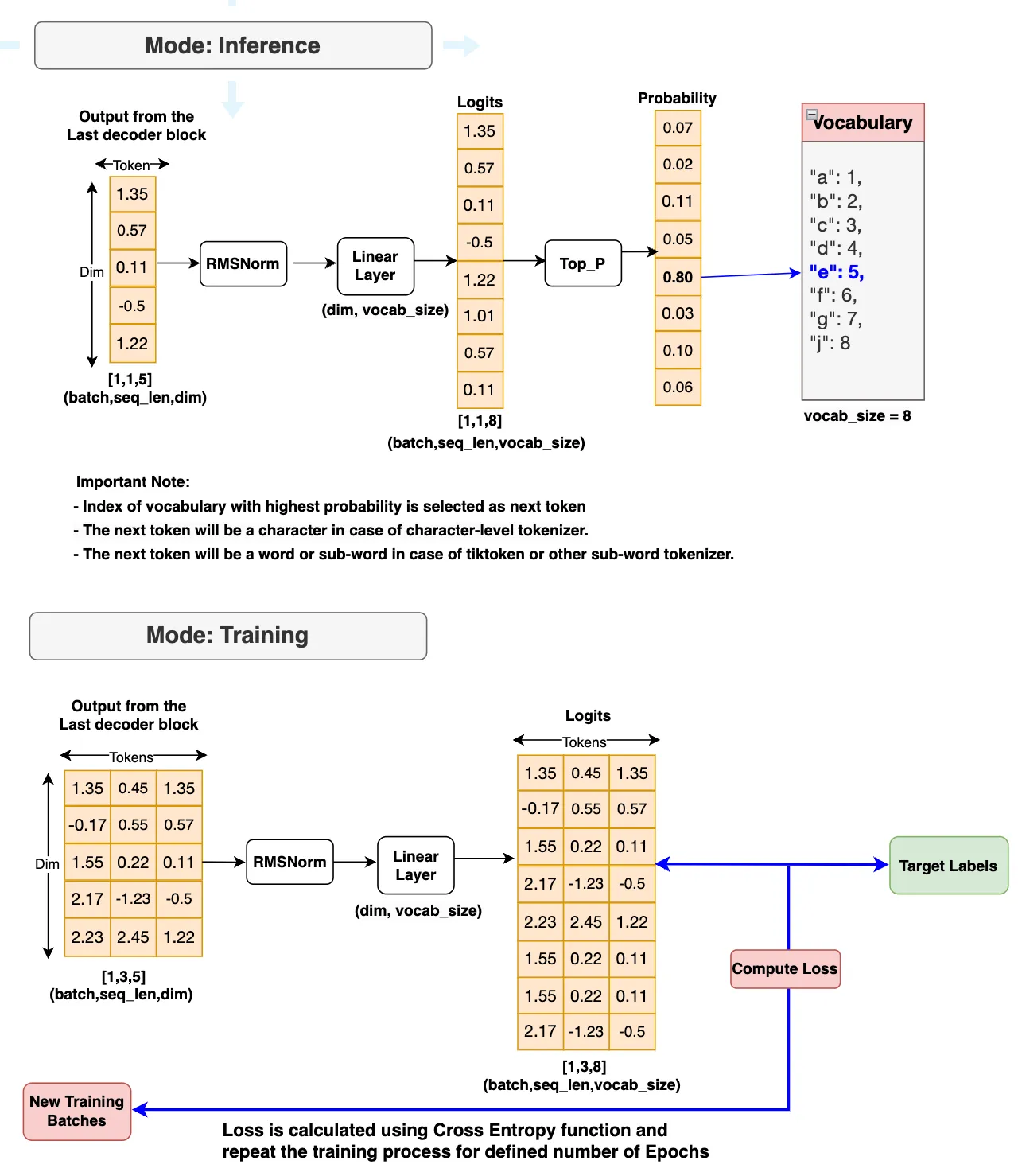
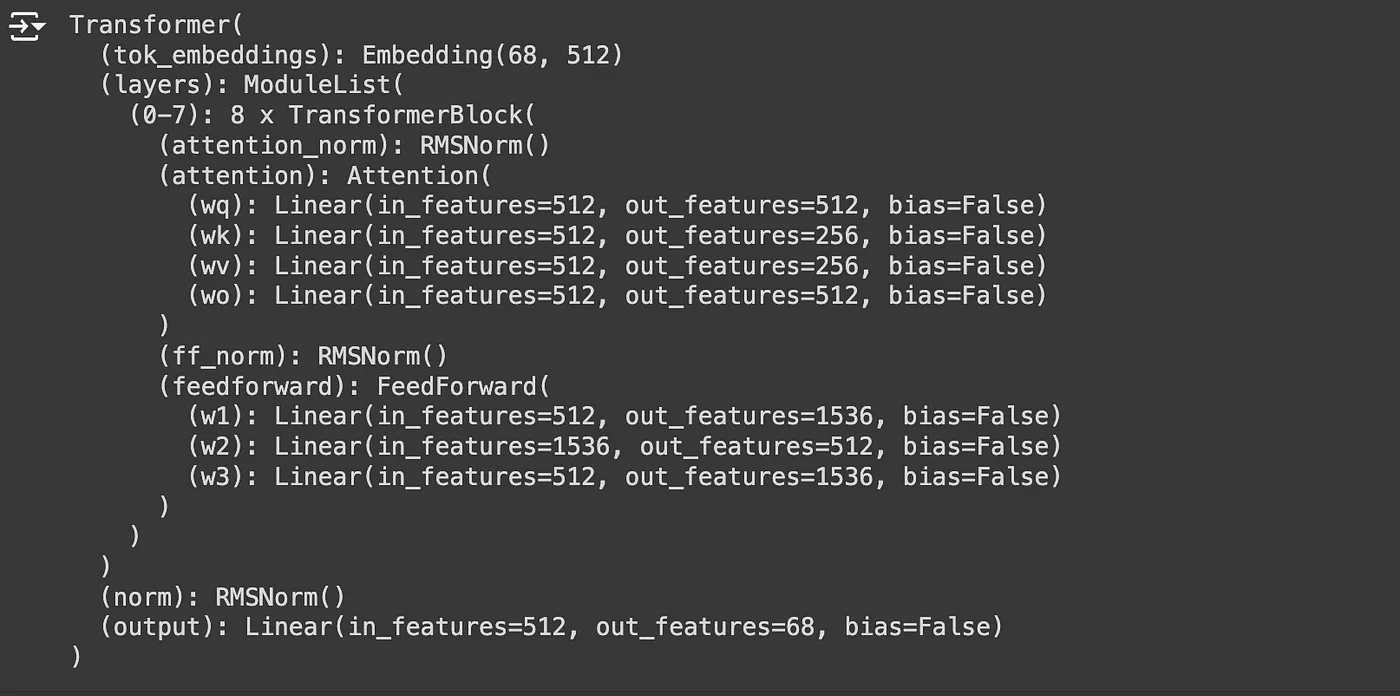
# This is the Llama 3 model. Again, the class name is maintained as Transformer to match with Meta Llama 3 model.classTransformer(nn.Module):def__init__(self,params:ModelArgs):super().__init__()# set all the ModelArgs in params variableself.params=params# Initilizate embedding class from the input blockself.tok_embeddings=nn.Embedding(params.vocab_size,params.dim)# Initialize the decoder block and store it inside the ModuleList. # This is because we've 4 decoder blocks in our Llama 3 model. (Official Llama 3 has 32 blocks)self.layers=nn.ModuleList()forlayer_idinrange(params.n_layers):self.layers.append(TransformerBlock(args=params))# Initilizate RMSNorm for the output blockself.norm=RMSNorm(params.dim,eps=params.norm_eps)# Initilizate linear layer at the output block.self.output=nn.Linear(params.dim,params.vocab_size,bias=False)defforward(self,x,start_pos=0,targets=None):# start_pos = token position for inference mode, inference = True for inference and False for training mode# x is the batch of token_ids generated from the texts or prompts using tokenizers.# x[bsz, seq_len] -> h[bsz, seq_len, dim]h=self.tok_embeddings(x)# If the target is none, Inference mode is activated and set to "True" and "False" if Training mode is activated.iftargetsisNone:inference=Trueelse:inference=False# The embeddings (h) will then pass though all the decoder blocks.forlayerinself.layers:h=layer(h,start_pos,inference)# The output from the final decoder block will feed into the RMSNormh=self.norm(h)# After normalized, the embedding h will then feed into the Linear layer. # The main task of the Linear layer is to generate logits that maps the embeddings with the vocabulary size.# h[bsz, seq_len, dim] -> logits[bsz, seq_len, vocab_size]logits=self.output(h).float()loss=None# Inference mode is activated if the targets is not availableiftargetsisNone:loss=None# Training mode is activated if the targets are available. And Loss will be calculated for further model training. else:# 交叉熵计算损失loss=F.cross_entropy(logits.view(-1,self.params.vocab_size),targets.view(-1))returnlogits,loss### Test: Transformer (Llama Model) #### You need take out the triple quotes below to perform testing"""model = Transformer(ModelArgs).to(ModelArgs.device)print(model)"""
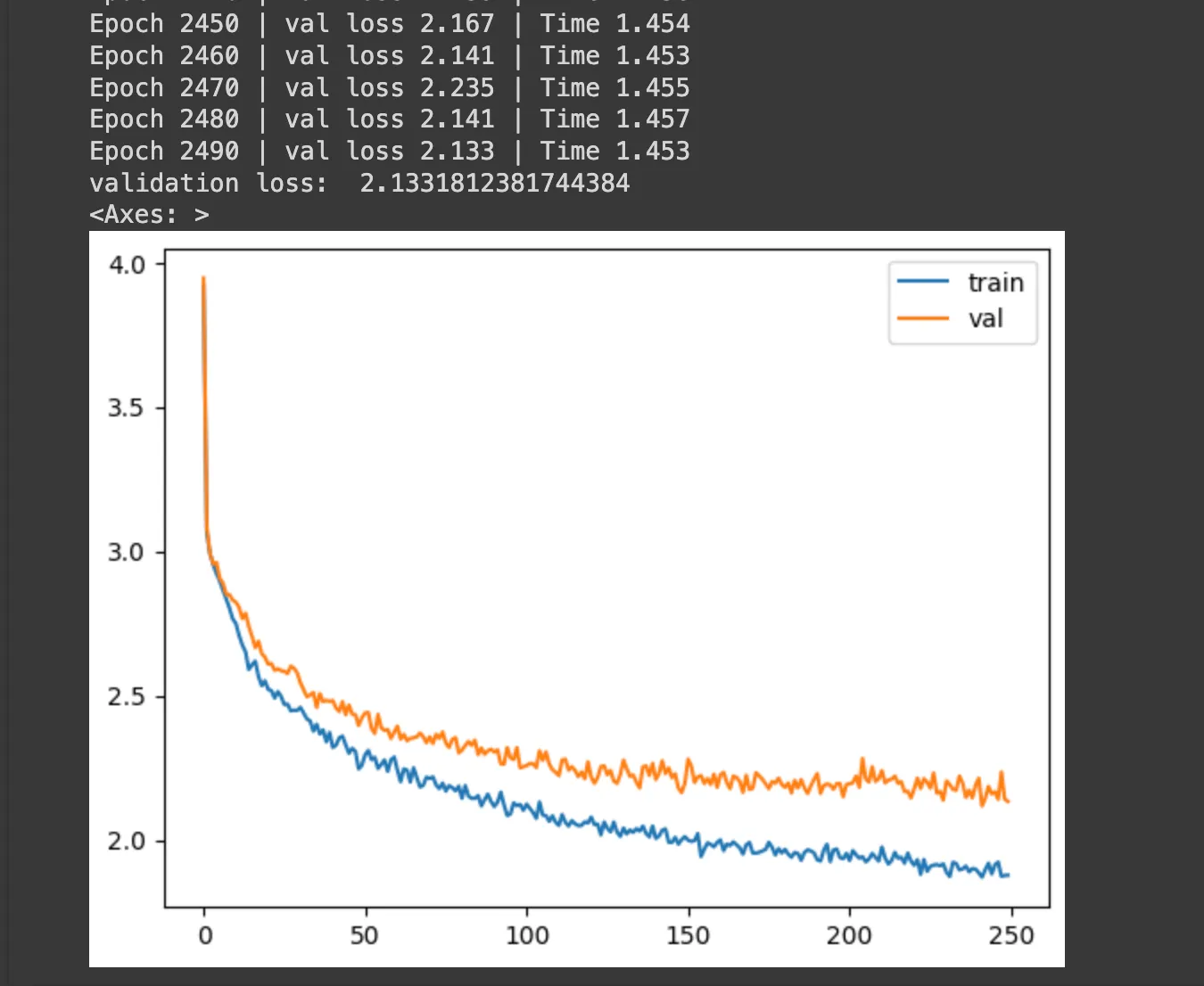
## Step 4: Train Llama 3 Model:# Create a dataset by encoding the entire tiny_shakespeare data token_ids list using the tokenizer's encode function that we've built at the input block sectiondataset=torch.tensor(encode(data),dtype=torch.int).to(ModelArgs.device)print(f"dataset-shape: {dataset.shape}")# Define function to generate batches from the given datasetdefget_dataset_batch(data,split,args:ModelArgs):seq_len=args.max_seq_lenbatch_size=args.max_batch_sizedevice=args.devicetrain=data[:int(0.8*len(data))]val=data[int(0.8*len(data)):int(0.9*len(data))]test=data[int(0.9*len(data)):]batch_data=trainifsplit=="val":batch_data=valifsplit=="test":batch_data=test# Picking random starting points from the dataset to give random samples for training, validation and testing.ix=torch.randint(0,len(batch_data)-seq_len-3,(batch_size,)).to(device)x=torch.stack([torch.cat([token_bos,batch_data[i:i+seq_len-1]])foriinix]).long().to(device)y=torch.stack([torch.cat([batch_data[i+1:i+seq_len],token_eos])foriinix]).long().to(device)returnx,y### Test: get_dataset function ###"""xs, ys = get_dataset_batch(dataset, split="train", args=ModelArgs)print([(decode(xs[i].tolist()), decode(ys[i].tolist())) for i in range(len(xs))])"""# Define a evaluate loss function to calculate and store training and validation loss for logging and plotting@torch.no_grad()defevaluate_loss(model,args:ModelArgs):out={}model.eval()forsplitin["train","val"]:losses=[]for_inrange(10):xb,yb=get_dataset_batch(dataset,split,args)_,loss=model(x=xb,targets=yb)losses.append(loss.item())out[split]=np.mean(losses)model.train()returnout# Define a training function to perform model trainingdeftrain(model,optimizer,args:ModelArgs):epochs=args.epochslog_interval=args.log_intervaldevice=args.devicelosses=[]start_time=time.time()forepochinrange(epochs):optimizer.zero_grad()xs,ys=get_dataset_batch(dataset,'train',args)xs=xs.to(device)ys=ys.to(device)logits,loss=model(x=xs,targets=ys)loss.backward()optimizer.step()ifepoch%log_interval==0:batch_time=time.time()-start_timex=evaluate_loss(model,args)losses+=[x]print(f"Epoch {epoch} | val loss {x['val']:.3f} | Time {batch_time:.3f}")start_time=time.time()# Print the final validation lossprint("validation loss: ",losses[-1]['val'])# Display the interval losses in plot returnpd.DataFrame(losses).plot()
## Step 5: Inference Llama 3 Model:# This function generates text sequences based on provided prompts using the LLama 3 model we've built and trained.defgenerate(model,prompts:str,params:ModelArgs,max_gen_len:int=500,temperature:float=0.6,top_p:float=0.9):# prompt_tokens: List of user input texts or prompts# max_gen_len: Maximum length of the generated text sequence.# temperature: Temperature value for controlling randomness in sampling. Defaults to 0.6.# top_p: Top-p probability threshold for sampling prob output from the logits. Defaults to 0.9.# prompt_tokens = [0]bsz=1#For inferencing, in general user just input one prompt which we'll take it as 1-batchprompt_tokens=token_bos.tolist()+encode(prompts)assertlen(prompt_tokens)<=params.max_seq_len,"prompt token length should be small than max_seq_len"total_len=min(len(prompt_tokens)+max_gen_len,params.max_seq_len)# this tokens matrix is to store the input prompts and all the output that is generated by model.# later we'll use the tokenizers decode function to decode this token to view results in text formattokens=torch.full((bsz,total_len),fill_value=token_pad.item(),dtype=torch.long,device=params.device)# fill in the prompt tokens into the token matrixtokens[:,:len(prompt_tokens)]=torch.tensor(prompt_tokens,dtype=torch.long,device=params.device)#create a prompt_mask_token for later use to identify if the token is a prompt token or a padding token# True if it is a prompt token, False if it is a padding tokeninput_text_mask=tokens!=token_pad.item()#now we can start inferencing using one token at a time from the prompt_tokens list starting with the first position.prev_pos=0forcur_posinrange(1,total_len):withtorch.no_grad():logits,_=model(x=tokens[:,prev_pos:cur_pos],start_pos=prev_pos)iftemperature>0:probs=torch.softmax(logits[:,-1]/temperature,dim=-1)next_token=sample_top_p(probs,top_p)else:next_token=torch.argmax(logits[:,-1],dim=-1)next_token=next_token.reshape(-1)# only replace the token if it's a padding tokennext_token=torch.where(input_text_mask[:,cur_pos],tokens[:,cur_pos],next_token)tokens[:,cur_pos]=next_tokenprev_pos=cur_posiftokens[:,cur_pos]==token_pad.item()andnext_token==token_eos.item():breakoutput_tokens,output_texts=[],[]fori,toksinenumerate(tokens.tolist()):# eos_idx = toks.index(token_eos.item())iftoken_eos.item()intoks:eos_idx=toks.index(token_eos.item())toks=toks[:eos_idx]output_tokens.append(toks)output_texts.append(decode(toks))returnoutput_tokens,output_texts# Perform top-p (nucleus) sampling on a probability distribution.# probs (torch.Tensor): Probability distribution tensor derived from the logits.# p: Probability threshold for top-p sampling.# According to the paper, Top-p sampling selects the smallest set of tokens whose cumulative probability mass exceeds the threshold p. # The distribution is renormalized based on the selected tokens.defsample_top_p(probs,p):probs_sort,prob_idx=torch.sort(probs,dim=-1,descending=True)probs_sum=torch.cumsum(probs_sort,dim=-1)mask=probs_sum-probs_sort>pprobs_sort[mask]=0.0probs_sort.div_(probs_sort.sum(dim=-1,keepdim=True))next_token=torch.multinomial(probs_sort,num_samples=1)next_token=torch.gather(prob_idx,-1,next_token)# Sampled token indices from the vocabular is returned returnnext_token
## Perform the inferencing on user input promptsprompts="Consider you what services he has done"output_tokens,output_texts=generate(model,prompts,ModelArgs)output_texts=output_texts[0].replace("<|begin_of_text|>","")print(output_texts)## Output ##Consideryouwhatserviceshehasdone.CLARENCE:Why,Isay,letmeseethepoorofyourfather,Andalltheshepherd's anchor in the causeOfyourhonourinthepeopleofthetribunesOftheworldthereisahorseman's face,Thatworthystrongerinthe