使用Pytorch从零构建Llama3大模型--深入了解LLaMa3模型的每个组件
(本文主要内容译自build-your-own-llama-3-architecture-from-scratch-using-pytorch)
先看一下LLama3模型结构,这个是译文作者根据LLama3论文画的,画得很好。图中包括了训练和推理的流程。
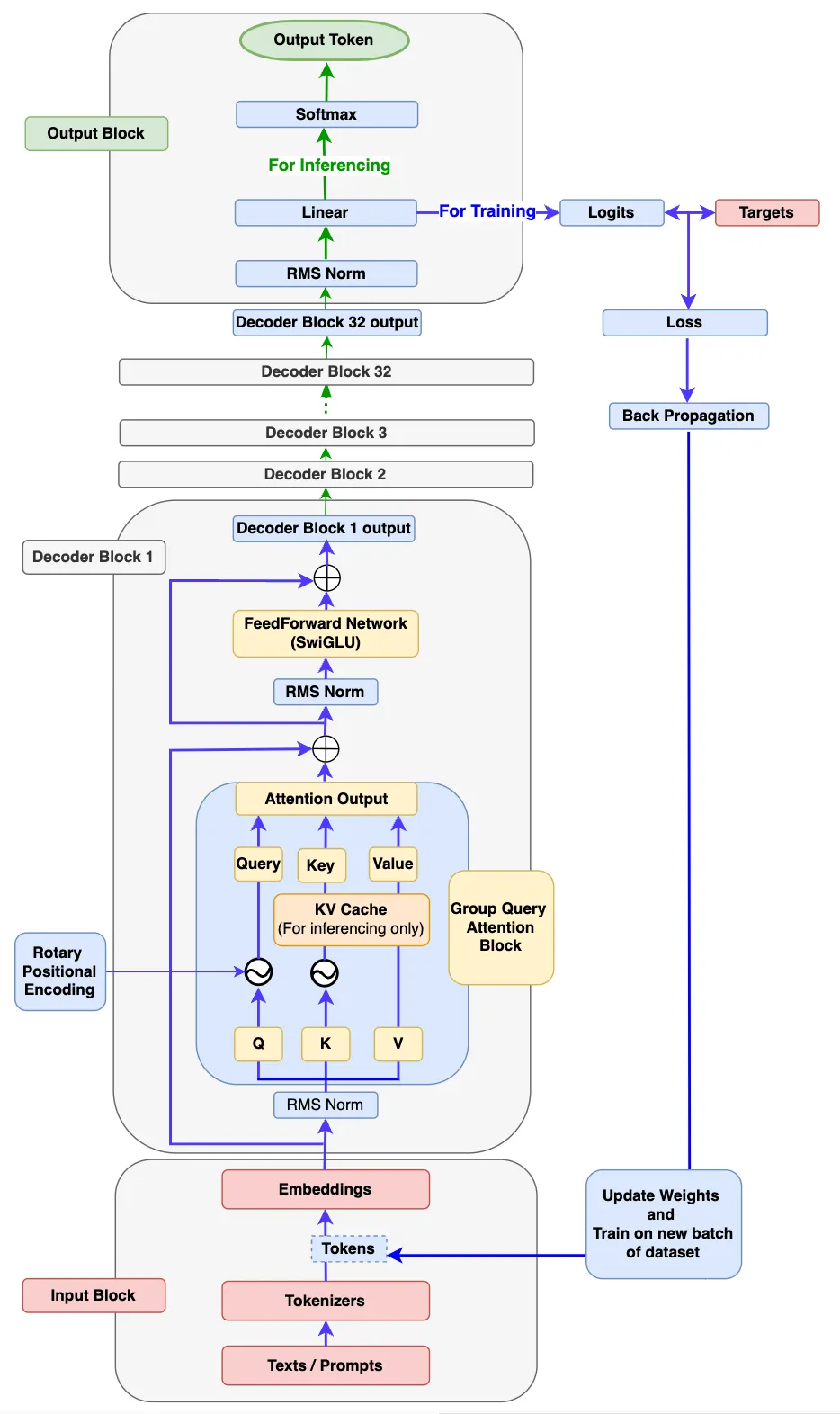
看了这篇文章的收获?¶
- 深入了解 LLaMa 3 模型的每个组件如何工作的。
- 编写代码来构建 LLaMa 3 的每个组件,然后将它们组装在一起以构建一个功能齐全的 LLaMa 3 模型。
- 编写代码使用新的自定义数据集来训练你的模型。
- 编写代码执行推理,以便你的 LLaMa 3 模型可以根据输入提示生成新文本。
输入Input Block¶
输入由三个部分组成: + Texts/ Prompts + Tokenizer + Embeddings
一图胜千言,通过图片来了解一下这三个部分如何一起工作的。
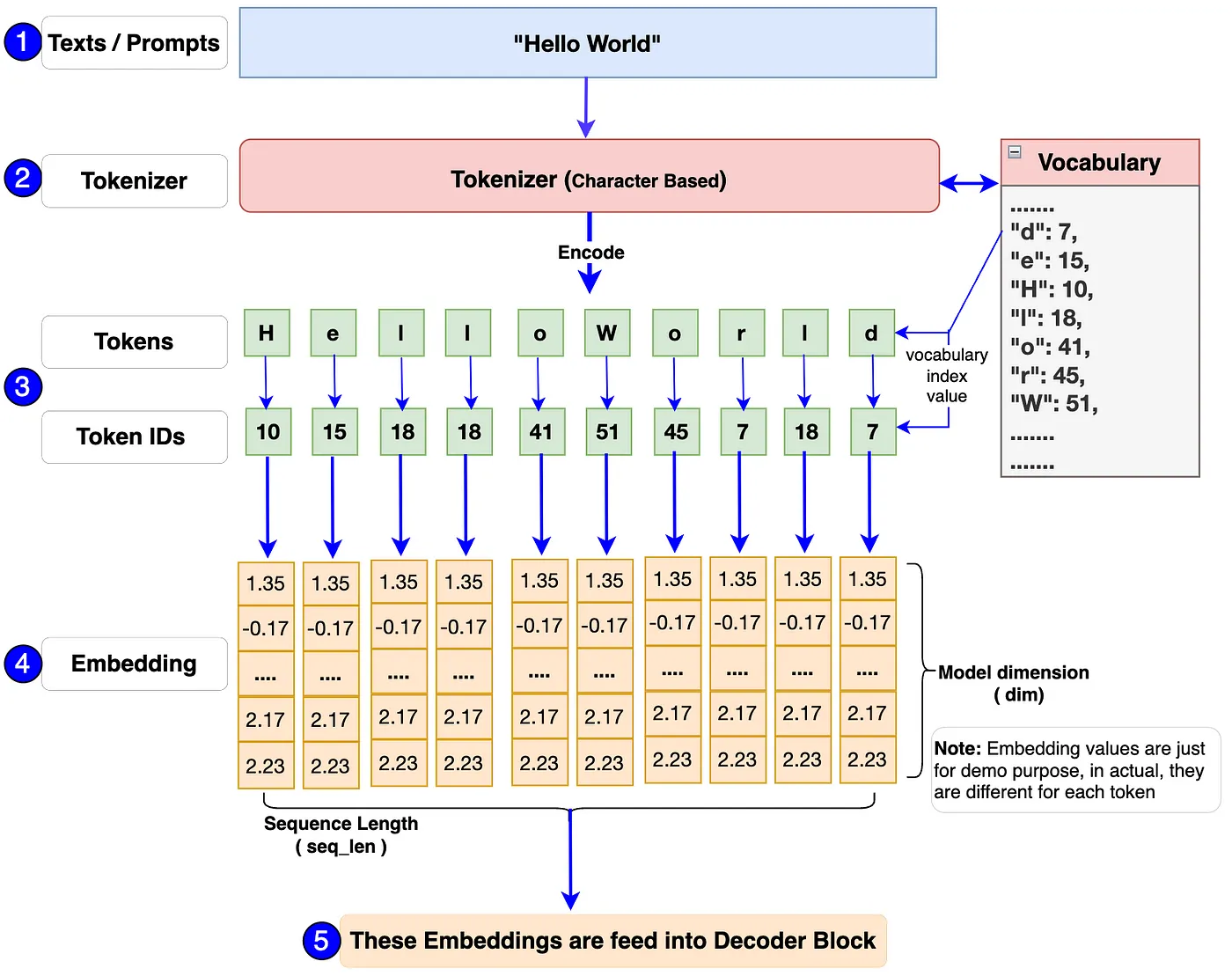
-
首先,单个或一批prompts(提示词)将被传入模型。例如:上述流程图中的“Hello World”。
-
模型的输入应始终为数字格式,因为它无法处理文本。Tokenizer 将这些文本/提示转换为token和ID(对应词汇表中标记的索引编号表示)。
- 在 Llama 3 模型中使用的Tokenizer是 TikToken,一种subword tokenizer。在文章中采用了使用字符级tokenizer。主要原因是我们应该知道如何自己构建包括编码和解码功能的词汇表和分词器。这样我们将能够了解一切在幕后是如何工作的,并且我们将完全控制代码。
- 最后,每个token ID 将被转换为维度为 128 的嵌入向量(embedding vector)(在原始的 Llama 3 8B模型中,它是 4096)。然后,这些embeddings将被传递到下一个称为Decoder Block的块中。
Decoder Block¶
由如下部分组成:
- RMS Norm
- Rotary Positional Encoding
- KV Cache
- Group Query Attention
- FeedForward Network
- Decoder Block
均方根归一化(Root Mean Square Normalization)¶
为什么需要 RMSNorm?
在上述架构图中,你一定注意到了输入块的输出,即嵌入向量会通过RMSNorm 块。这是因为嵌入向量有很多维度(在 Llama3-8b 中为 4096 维),并且始终存在值处于不同范围的可能性。这可能会导致模型梯度爆炸或消失,从而导致收敛缓慢甚至发散。RMSNorm 将这些值转换到一定范围,有助于稳定和加速训练过程。这使得梯度具有更一致的幅度,从而使模型更快地收敛。
通过一张图解释了RMS Norm是如何工作的!
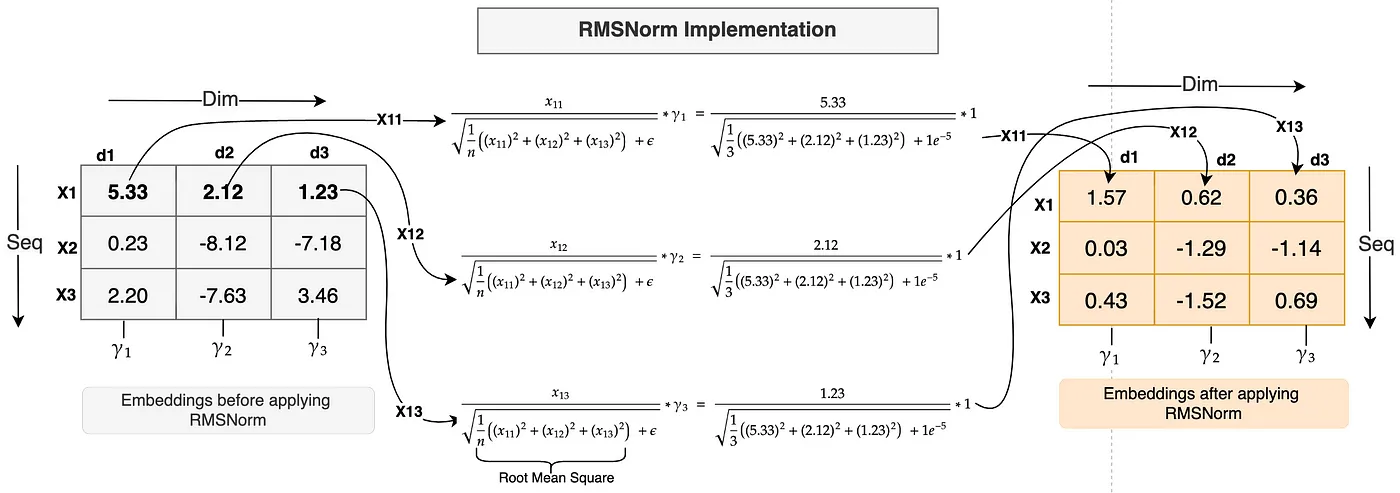
图中的embedding输入shape是3x3,也就是有3个token,每个token的embedding vector维度为3。
与层归一化(layer normalization)类似,均方根归一化(RMSNorm)沿embedding特征或维度应用。上面的图具有形状为[3,3]的embedding,这意味着每个token有 3 个维度。
解释将 RMSNorm 应用于第一个token X1 的embedding的过程¶
-
在X1沿着embedding的每个维度上,即 x11、x12 和 x13,标记 X1 的值将分别除以所有这些值的均方根。计算公式如上图所示。
-
E(Epsilon,一个小的常数)被添加到均方根中,以避免为了数值稳定性而出现除以零的情况。
-
最后,一个缩放参数Gamma \(Gamma\) 与之相乘。每个特征都有一个唯一的 \(Gamma\) 参数(就像上面图中的维度 d1 的 Y1、维度 d2 的 Y2 和维度 d3 的 Y3 一样),它是一个学习参数,可以向上或向下缩放,以进一步稳定归一化。\(Gamma\) 参数初始值为 1(如上面的计算所示)。
-
正如你在上面的例子中注意到的,embedding值很大且分布在一个很宽的范围内。应用 RMSNorm 后,值变得小很多且在一个较小的范围内。计算是使用实际的 RMSNorm 函数完成的。
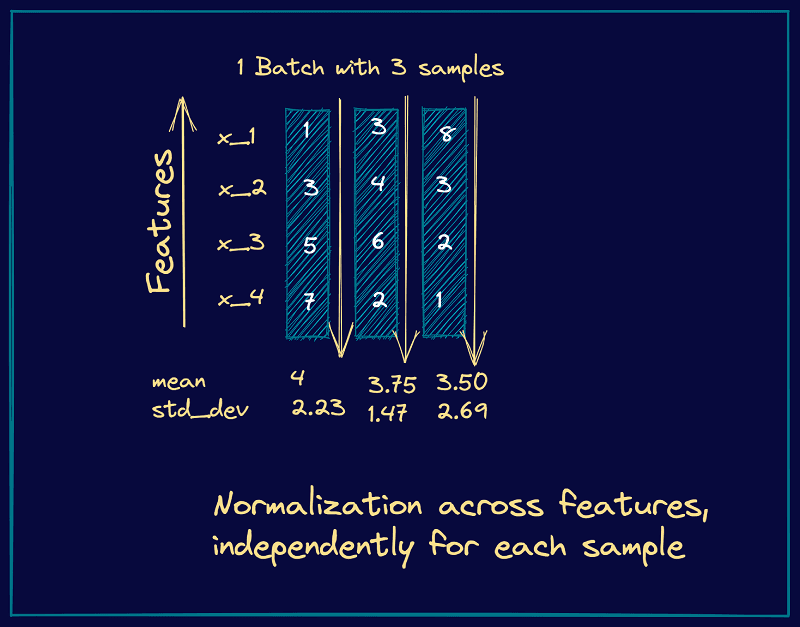
为什么选择 RMSNorm 而不是层归一化?正如你在上面的例子中注意到的,我们没有计算任何均值或方差,而这在层归一化的情况下是会进行计算的。因此,我们可以说 RMSNorm 通过避免均值和方差的计算减少了计算开销。此外,根据作者的论文,RMSNorm 在不影响准确性的情况下具有性能优势。
层归一化的图示:

旋转位置编码(RoPE)¶
为什么我们需要旋转位置编码(RoPE)?
在我们深入探讨为什么需要它之前,回顾一下到目前为止我们所做的事情。首先,我们将输入文本转换为embedding表示。接下来,我们对embedding表示应用均方根归一化(RMSNorm)。
不知道你一定注意到有些不对劲的地方没有。比如说,输入文本是“我喜欢苹果”(I love apple)或“苹果喜欢我”(Apple love I),模型仍然会将这两个句子视为相同并以相同的方式学习。因为在embedding表示中没有为模型定义顺序以供学习。因此,顺序对于任何语言模型都非常重要。
在Llama 3模型架构中,旋转位置编码(RoPE)用于定义句子中每个token的位置,它不仅维护了顺序,还维护了句子中token的相对位置。
那么,什么是旋转位置编码以及它是如何工作的呢?正如上面“为什么”部分所提到的,RoPE 是一种位置编码,它对embedding表示进行编码,通过添加绝对位置信息以及结合token之间的相对位置信息来维护句子中token的顺序。它通过使用称为旋转矩阵的特殊矩阵旋转给定的embedding表示来执行编码操作。这个使用旋转矩阵的简单而非常强大的数学推导是 RoPE 的核心。
下图展示了一个旋转矩阵如何应用到二维矩阵。
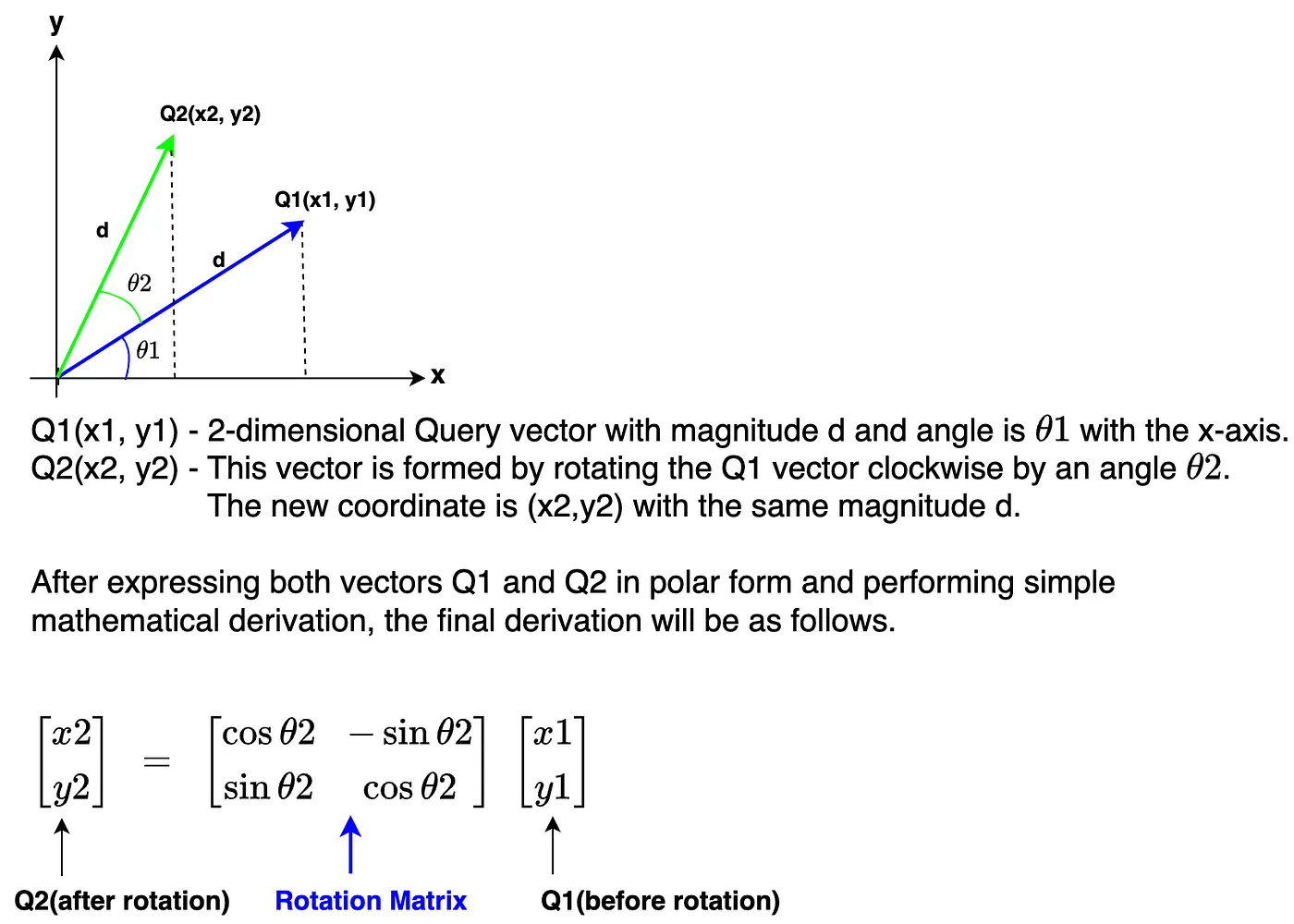
上图中的旋转矩阵可旋转二维向量。然而,Llama 3 模型的维度数为 4096,要多得多。让我们来看看如何在更高维度的embedding上应用旋转。
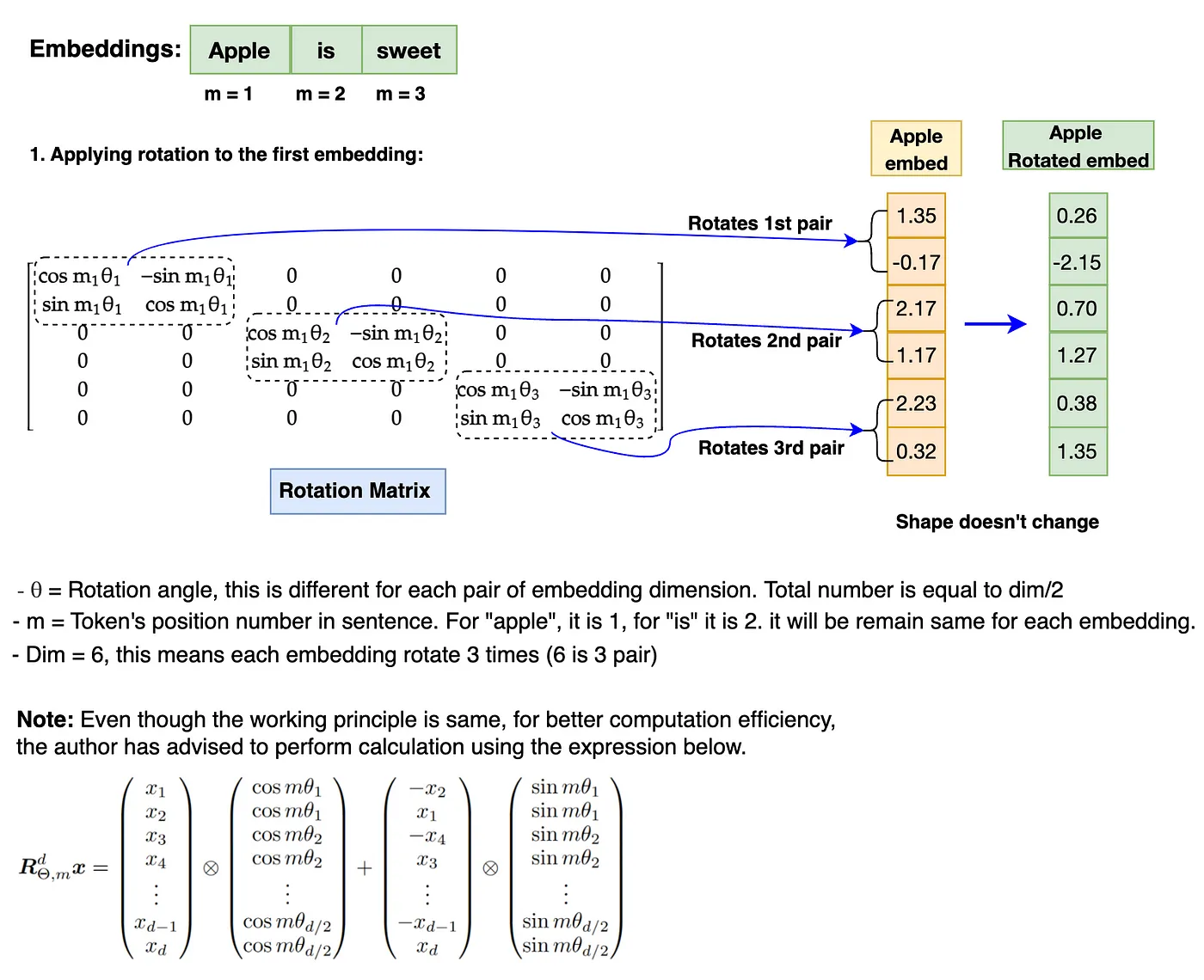
embedding的旋转涉及每对embedding维度中每个embedding位置(m)值与 theta(θ)的乘法。这就是旋转位置编码(RoPE)通过旋转矩阵的实现来捕获绝对位置以及相对位置信息的方式。
!!! 注意:在执行旋转之前,旋转矩阵需要转换为极坐标形式,embedding向量需要转换为复数。旋转完成后,旋转后的嵌入需要转换回实数以进行注意力操作。此外,RoPE 仅应用于查询(Query)和键(Key)嵌入,不适用于值(Value)嵌入。
KV Cache (仅在推理阶段应用)¶
什么是 KV-Cache?
在 LLaMa 3 架构中,在推理时引入了 KV-Cache 的概念,以键值缓存的形式存储先前生成的token。这些缓存将用于计算自注意力以生成下一个token。仅缓存键(Key)和值(Value)的token,而不缓存查询(Query)的token,因此称为 KV 缓存。
我们为什么需要 KV 缓存?让我们看下面的图表来解答我们的疑惑。
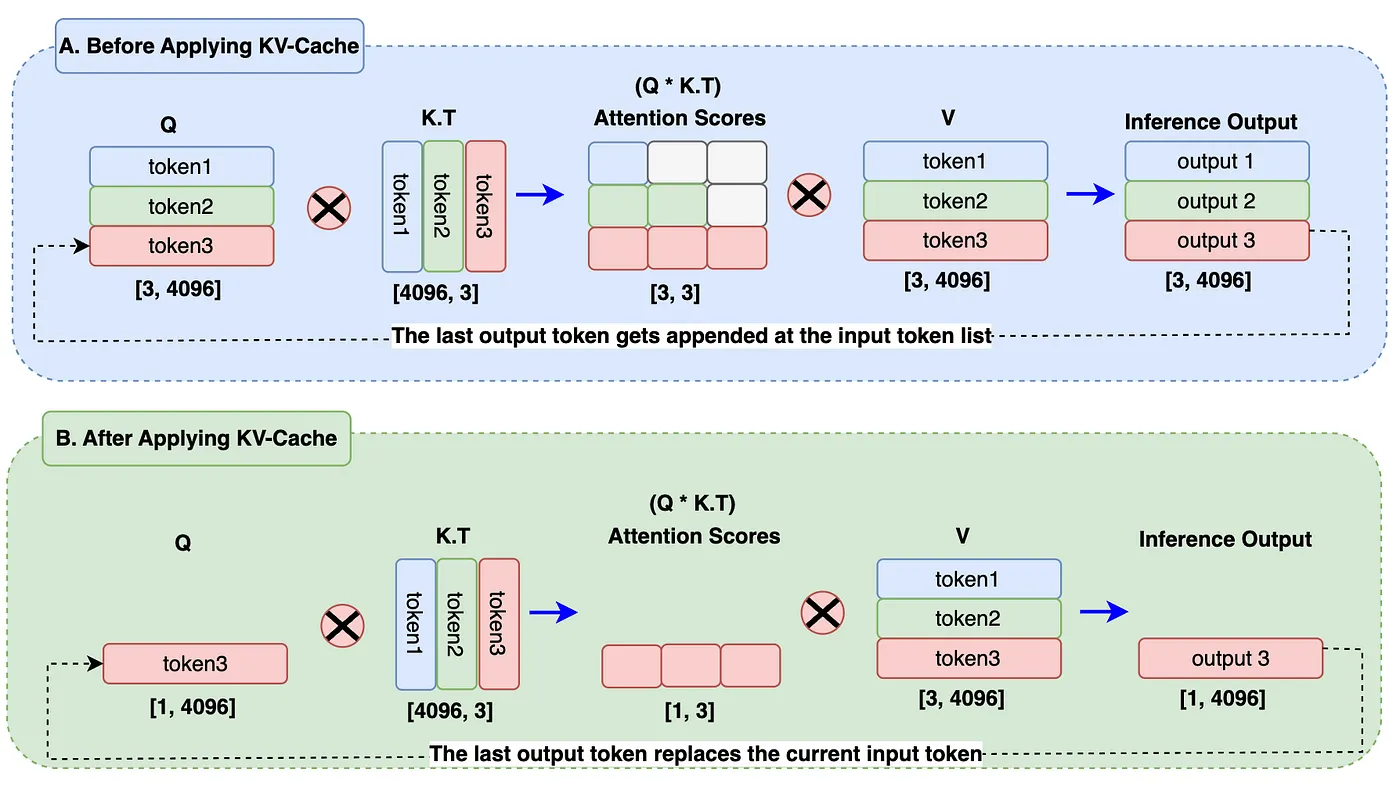
在图表的 A 块中,当生成output3 token时,先前的output token(output1、output2)仍在计算中,这完全没有必要。这在注意力计算期间导致了额外的矩阵乘法,因此计算资源大大增加。
在图表的 B 块中,最后生成的output token替换input token构成Query Embedding输入。KV 缓存存储先前生成的token。在计算注意力得分时,我们只需要从Query中使用 1 个token,并从键值缓存中使用先前的token。它将矩阵乘法从 A 块的 3x3 减少到 B 块的 1x3,几乎减少了 66%。在现实世界中,对于巨大的序列长度和批量大小,这将有助于减少大量的计算能力。最后,始终只有一个最新生成的ouput token。这就是引入 KV-Cache 的主要原因。
分组查询注意力 (Group Query Attention)¶
组查询注意力与之前模型(如 Llama 1)中使用的多头注意力相同,唯一的区别在于对查询(Query)使用单独的头(Head),对键/值(Key/Value)使用单独的头。通常,分配给查询的头数是键和值头数的 n 倍。让我们看一下图表以进一步加深理解。
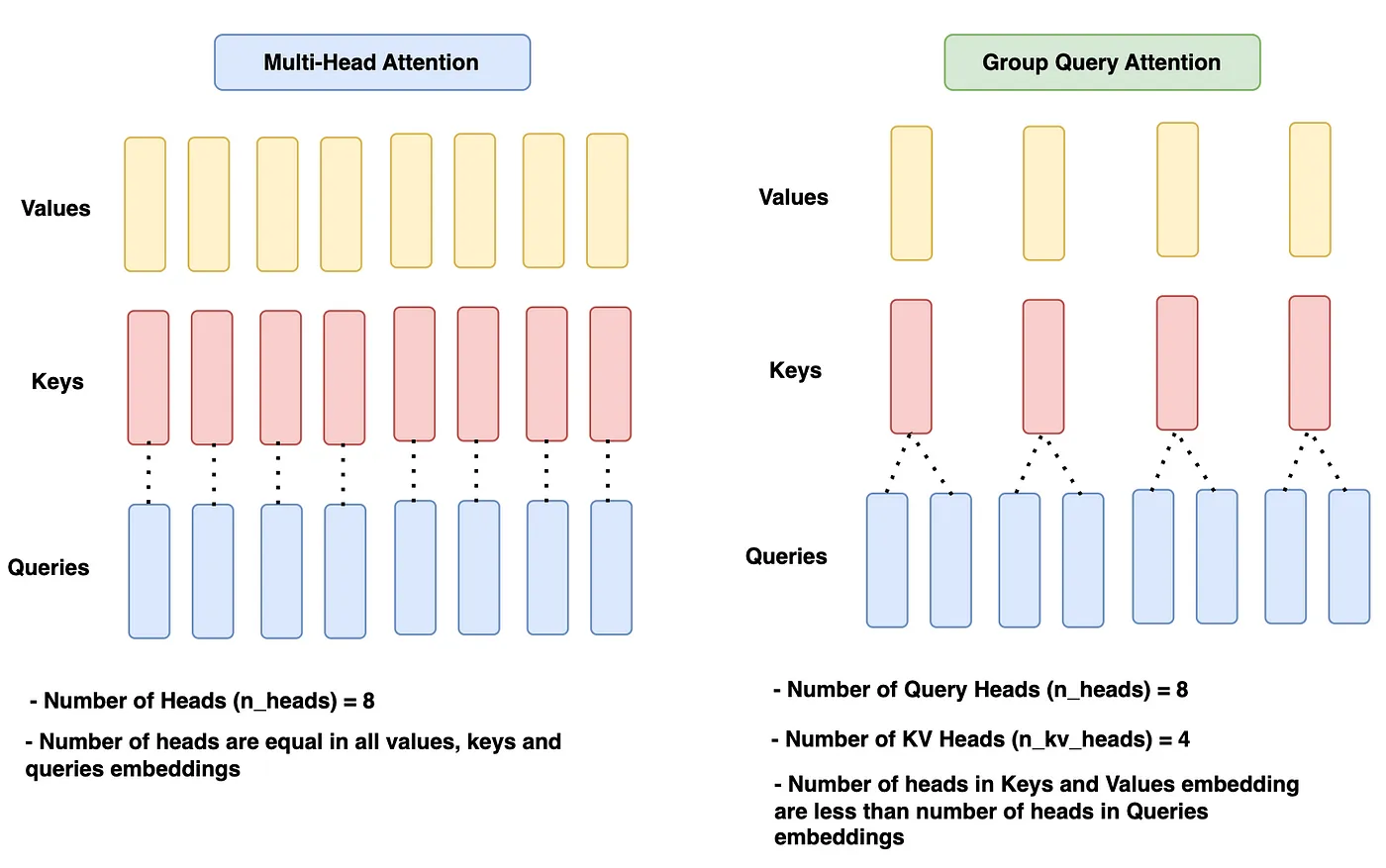
在给定的图表中,多头注意力在所有查询、键和值中具有相同数量的头,即 n_heads = 8。
组查询注意力模块对于查询有 8 个头(n_heads),对于键和值有 4 个头(n_kv_heads),这比查询头少 2 倍。
既然多头注意力已经如此出色,为什么我们还需要分组查询注意力呢?
为了回答这个问题,我们需要回到KV Cache上来。KV Cache极大地有助于减少计算资源。然而,随着KV Cache存储越来越多的先前token,内存资源将显著增加。从模型性能的角度以及经济角度来看,这都不是一件好事。因此,引入了分组查询注意力。减少键(K)和值(V)的头数会减少要存储的参数数量,因此使用的内存更少。各种测试结果已经证明,采用这种方法,模型的准确性仍然保持在相同的范围内。
前馈网络(SwiGLU 激活)¶
在解码器块(Decoder Block)中前馈网络(FeedForward Network)的作用是什么?如上面的架构图所示,注意力输出首先在 RMSNorm 期间进行归一化,然后输入到前馈网络中。在前馈网络内部,注意力input embedding将在其隐藏层中扩展到更高维度,并学习token的更复杂特征。
为什么使用 SwiGLU 而不是 ReLU?
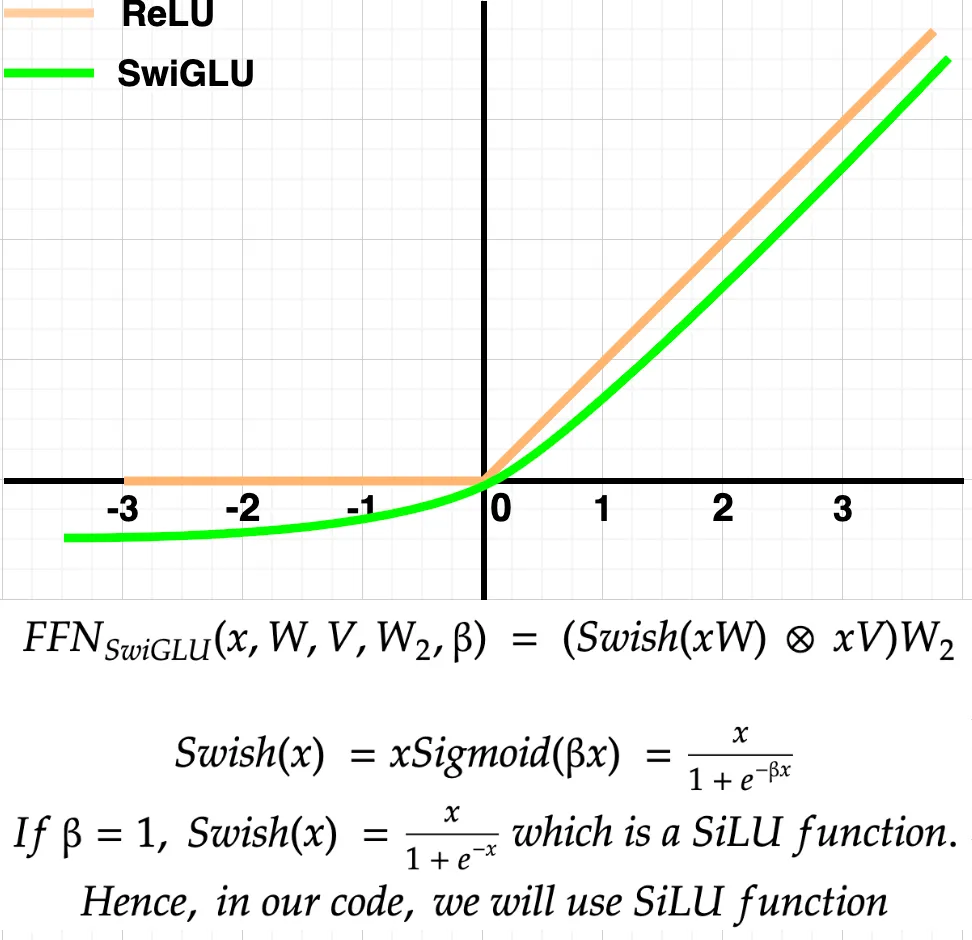
如上图所示,SwiGLU 函数在正轴上的表现几乎与 ReLU 相同。然而,在负轴上,SwiGLU 输出一些负值,在 ReLU 的情况下,这对于学习较小的值而不是平坦的 0 可能是有用的。总体而言,根据作者的说法,SwiGLU 的性能优于 ReLU;因此,它被选用。
Decoder Block¶
如文章最前面的架构图所示。解码器模块由多个子组件组成,前面的内容展开了讲解。
下面是在解码器模块内部执行的操作。
-
来自输入模块的embedding被送入Attention-RMSNorm 模块。这将进一步被送入组查询注意力模块(Group Query Attention block)。
-
来自输入模块的相同embedding随后将被加到注意力输出中。
-
之后,注意力输出被送入FeedFoWard-RMSNorm,并进一步送入前馈网络模块。
-
前馈网络的输出随后再次与注意力输出相加。
-
得到的输出被称为解码器输出。这个解码器输出随后作为输入被送入另一个解码器模块。同样的操作将在接下来的 31 个解码器模块中重复。第 32 个解码器模块的最终解码器输出随后被传递到输出模块(Output Block)。
Output Block以及后面的内容下篇文章再讲解。