defflash_attn_with_kvcache(q,k_cache,v_cache,k=None,v=None,rotary_cos=None,rotary_sin=None,cache_seqlens:Optional[Union[(int,torch.Tensor)]]=None,cache_batch_idx:Optional[torch.Tensor]=None,cache_leftpad:Optional[torch.Tensor]=None,block_table:Optional[torch.Tensor]=None,softmax_scale=None,causal=False,window_size=(-1,-1),# -1 means infinite context windowsoftcap=0.0,# 0.0 means deactivatedrotary_interleaved=True,alibi_slopes=None,num_splits=0,return_softmax_lse=False,):
如果 k 和 v 不为 None,k_cache 和 v_cache 将被原地更新为来自 k 和 v 的新值。这对于decoding很有用:你可以传入上一步的缓存键/值,并使用当前步的新键/值进行更新,然后使用更新后的缓存进行注意力计算,所有这些都在一个内核中完成。
如果你传入 k / v,你必须确保缓存足够大以容纳新值。例如,KV 缓存可以预先分配最大序列长度(max_seq_len),并且你可以使用 cache_seqlens 来跟踪批处理中每个序列的当前序列长度。
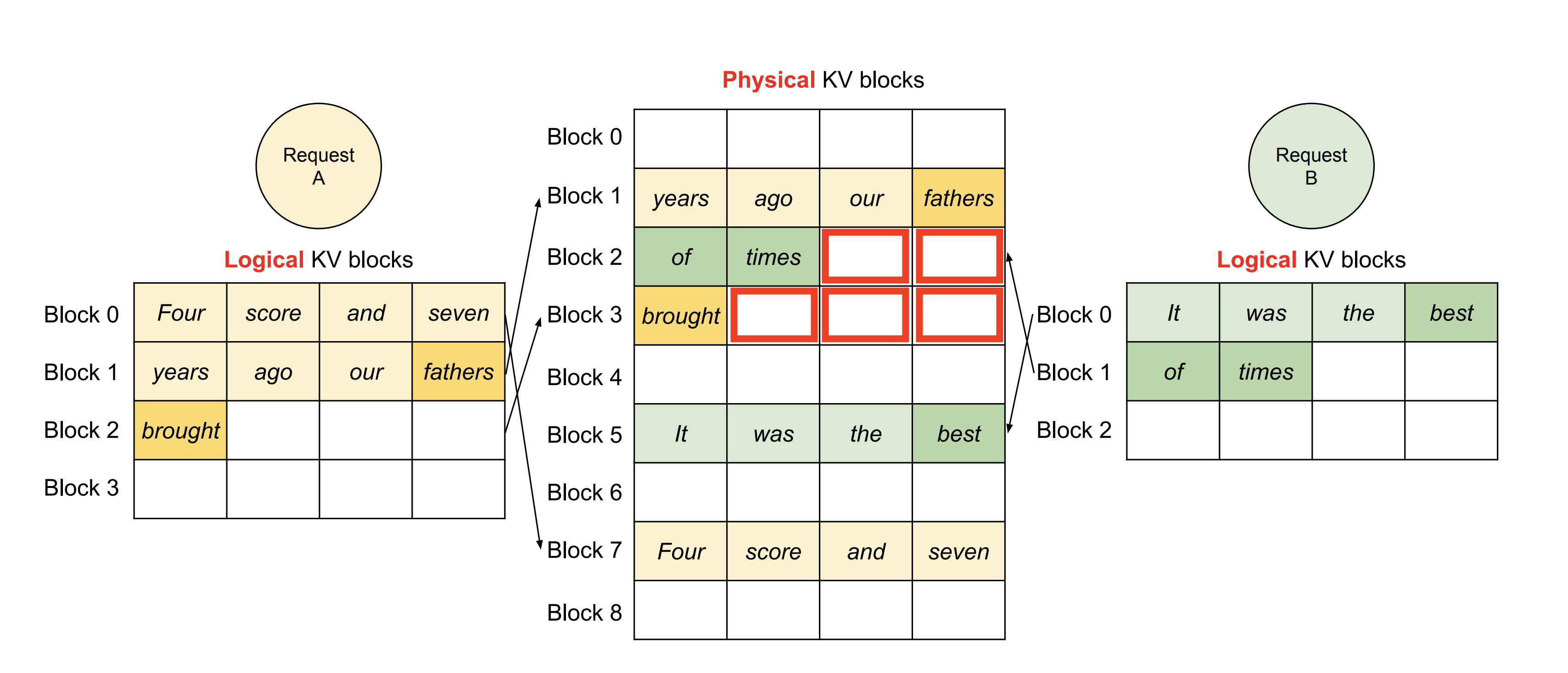
block_size=256classCacheManager:def__init__(self,tokens,block_size=block_size,batch_size=bsz,n_kv_heads=n_kv_heads,head_dim=head_dim):self.block_size=block_sizeself.batch_size=bszself.n_kv_heads=n_kv_headsself.head_dim=head_dimself.num_blocks=(max_seq_len//block_size)*5# TODO: make this dynamic# [batch_id, (index, filled_positions)]self.block_table={i:[]foriinrange(batch_size)}self.free_blocks=set(range(self.num_blocks))self.k_cache_paged=torch.randn(self.num_blocks,block_size,n_kv_heads,head_dim,device=device,dtype=torch.bfloat16)self.v_cache_paged=torch.randn(self.num_blocks,block_size,n_kv_heads,head_dim,device=device,dtype=torch.bfloat16)seq_lens=(tokens!=-1).sum(1)fori,tinenumerate(seq_lens.tolist()):num_blocks_to_reserve=math.ceil(t/block_size)num_filled_positions=t%block_sizeforbinrange(num_blocks_to_reserve):index=self.get_free_block()ifb==num_blocks_to_reserve-1:self.block_table[i].append((index,num_filled_positions))else:self.block_table[i].append((index,block_size))# Returns a free block to allocate more tokens to.# For simplicity, I raise an error when we run out of free blocks.# In the actual implementation, it solves this through scheduling and preemption (see paper)defget_free_block(self):iflen(self.free_blocks)==0:raiseException('No more free blocks. Implement scheduling and preemption.')index=random.choice(list(self.free_blocks))self.free_blocks.remove(index)returnindex# Gets the logical block table that PagedAttention uses# TODO: Serial computation makes it slow. Is there a faster way?# 将block_table转换为tensor,用于PagedAttention的输入defget_block_table(self):max_len=max(len(b)forbinself.block_table.values())block_table=[[-1]*max_lenfor_inrange(self.batch_size)]# i is batch index, j is block indexfori,binself.block_table.items():forj,(index,_)inenumerate(b):block_table[i][j]=indexreturntorch.tensor(block_table,dtype=torch.int32,device=device)defget_kv_cache(self):returnself.k_cache_paged,self.v_cache_paged# Specific to my KV implementation. Returns the last sequence position given the block table.defget_last_pos(self):last_pos=[(len(b)-1)*self.block_size+b[len(b)-1][1]-1forbinself.block_table.values()]returntorch.tensor(last_pos,dtype=torch.int32,device=device)# Frees request's blocks.# Here, I leave one block, and free the rest. This is a limitation imposed by my kv cache implementation.# TODO: Avoid this limitation.deffree_memory(self,index):blocks=self.block_table[index]iflen(blocks)==1:returnfori,_inblocks[1:]:self.free_blocks.add(i)self.block_table[index]=blocks[:1]# Updates block table and filled positions.# TODO: Again, pretty slow. Faster parallel way?defupdate(self,eos_reached,input_text_mask):fori,(eos,is_prompt)inenumerate(zip(eos_reached,input_text_mask)):ifis_prompt:# if the token is part of the original prompt, we skipcontinueifeos:# free the request's blocks since we have generated the complete answerself.free_memory(i)continueold_index,n=self.block_table[i][-1]ifn==self.block_size:# allocate new block if necessarynew_index=self.get_free_block()self.block_table[i].append((new_index,1))else:# otherwise, just use the next available slot in the blockself.block_table[i][-1]=(old_index,n+1)defget_fragmented_memory_size(self):size=0forbinself.block_table.values():_,filled=b[-1]# only the last block has fragmentationsize+=(self.block_size-filled)*n_kv_heads*head_dim*2*2returnsize# Create CacheManagers for each layer# 为每层创建CacheManagercms=[CacheManager(tokens)for_inrange(n_layers)]
# Do inferenceforcur_posinrange(min_prompt_len,max_seq_len):next_token=forward(tokens[:,prev_pos:cur_pos],prev_pos)next_token=torch.where(input_text_mask[:,cur_pos],tokens[:,cur_pos],next_token)tokens[:,cur_pos]=next_tokenpdb.set_trace()# Update CacheManagers. Increment filled positions + allocate new block if required.forlayerinrange(n_layers):cms[layer].update(eos_reached.tolist(),input_text_mask[:,cur_pos].tolist())eos_reached|=(~input_text_mask[:,cur_pos])&(torch.isin(next_token,stop_tokens))prev_pos=cur_posifall(eos_reached):break