bvar如何实现高性能多线程统计计数器
bvar是什么?
bvar是百度开源贡献给Apache的多线程环境下的计数器库。
通过它可以统计计数器、最大值、最小值、windows一段时间累加、除以秒数就是每秒,还有时延、分位值等等。
如果你使用brpc还可以启动一个server,直接访问http网址,可以图形化、界面化查看,美观清晰又方便。当然不是打广告哈!!!
单维度简单看看下面的图吧!
bvar的简单用法
看了半天,到底到你的项目里面有没有帮助,怎么用呢?
这里看一下官方文档的简单例子:
C++ #include <bvar/bvar.h>
bvar :: Adder < int > value ;
value << 1 << 2 << 3 << -4 ;
CHECK_EQ ( 2 , value . get_value ());
bvar :: Maxer < int > value ;
value << 1 << 2 << 3 << -4 ;
CHECK_EQ ( 3 , value . get_value ());
// 获得之前一段时间内平均每秒的统计值。
bvar :: Adder < int > sum ;
// sum_per_second.get_value()是sum在之前60秒内*平均每秒*的累加值,省略最后一个时间窗口的话默认为bvar_dump_interval。
bvar :: PerSecond < bvar :: Adder < int > > sum_per_second ( & sum , 60 );
// 计算延迟
LatencyRecorder write_latency ( "table2_my_table_write" ); // produces 4 variables:
// table2_my_table_write_latency
// table2_my_table_write_max_latency
// table2_my_table_write_qps
// table2_my_table_write_count
// In your write function
write_latency << the_latency_of_write ;
详细用法请移步:bvar_c++
聊一聊原理
单线程实现统计很简单,对一个统计的变量加减等操作都没有竞争。多线程存在竞争,如果是复杂数据结构就要加锁,或者使用lock-free、wait-free等数据结构实现。
普通数据类型,int、bool等还可以使用原子变量,比如std::atomic等。使用原子变量也要注意,第一它可能没有想象中的没那么快,第二由于编译器、cpu的重排序可能导致运行逻辑不是代码逻辑,会引起程序崩溃。
cacheline是cpu同步的最小单位,一般64字节。我们都知道cpu cache分为三级,一级cache(分为指令和数据的)是cpu核私有的,二级和三级是共享的。一旦数据更改了,其它核要看见,就会通过cache一致性协议同步数据,对于统计计数频繁更改的值,同步过程很耗时。cacheline常见的问题有cache bouncing、cache伪共享问题(可以通过对齐cacheline避免)。
要提高性能,就要避免让CPU频繁同步cacheline。
bvar的核心原理就是:
让每个线程修改thread-local变量,在需要时再合并所有线程中的值 。
当很多线程都在累加一个计数器时,每个线程只累加私有的变量而不参与全局竞争,在读取时累加所有线程的私有变量。虽然读比之前慢多了,但由于这类计数器的读多为低频的记录和展现,慢点无所谓。而写就快多了,极小的开销使得用户可以无顾虑地使用bvar监控系统,这便是我们设计bvar的目的。
参考:bvar.md
Cacheline的原理引用一段bvar项目中的介绍,感兴趣的朋友,阅读原地址:
没有任何竞争或只被一个线程访问的原子操作是比较快的,“竞争”指的是多个线程同时访问同一个cacheline。现代CPU为了以低价格获得高性能,大量使用了cache,并把cache分了多级。百度内常见的Intel E5-2620拥有32K的L1 dcache和icache,256K的L2 cache和15M的L3 cache。其中L1和L2 cache为每个核心独有,L3则所有核心共享。一个核心写入自己的L1 cache是极快的(4 cycles, ~2ns),但当另一个核心读或写同一处内存时,它得确认看到其他核心中对应的cacheline。对于软件来说,这个过程是原子的,不能在中间穿插其他代码,只能等待CPU完成一致性同步,这个复杂的硬件算法使得原子操作会变得很慢,在E5-2620上竞争激烈时fetch_add会耗费700纳秒左右。访问被多个线程频繁共享的内存往往是比较慢的。比如像一些场景临界区看着很小,但保护它的spinlock性能不佳,因为spinlock使用的exchange, fetch_add等指令必须等待最新的cacheline,看上去只有几条指令,花费若干微秒并不奇怪。
参考:atomic_instructions
实现python版本的也很简单,只要跟着实现对应的API。而且因为python存在一个叫做全局解释器(GIL)锁的东东,所以不需要thread-local处理。GIL就是python解释器运行python代码时,多线程会加一把大锁,虽然性能低,但是避免了冲突和同步。因此,python运行大量计算程序,要用multi-process,多进程。
聊到这里了就是,还有FFI绑定,也就是比如c或者C++实现了一个多线程的cpu大量计算程序,通过ctypes、Pybind等方式绑定了接口。那么是不需要考虑GIL的,因为c++实现了多个线程的计算,没有GIL这个大锁哈。
研读一下源码,哪天你也可以造轮子
了解了bvar的功能、原理、API介绍,到这个程度,你已经熟悉了这个库了。再踩踩坑,就可以在项目中熟练使用了。又多了一个屠龙技。
接下来,剖析一下美妙的源码实现,有一天你也可以可以造出漂亮的改变世界的轮子。
阅读源码小妙招:
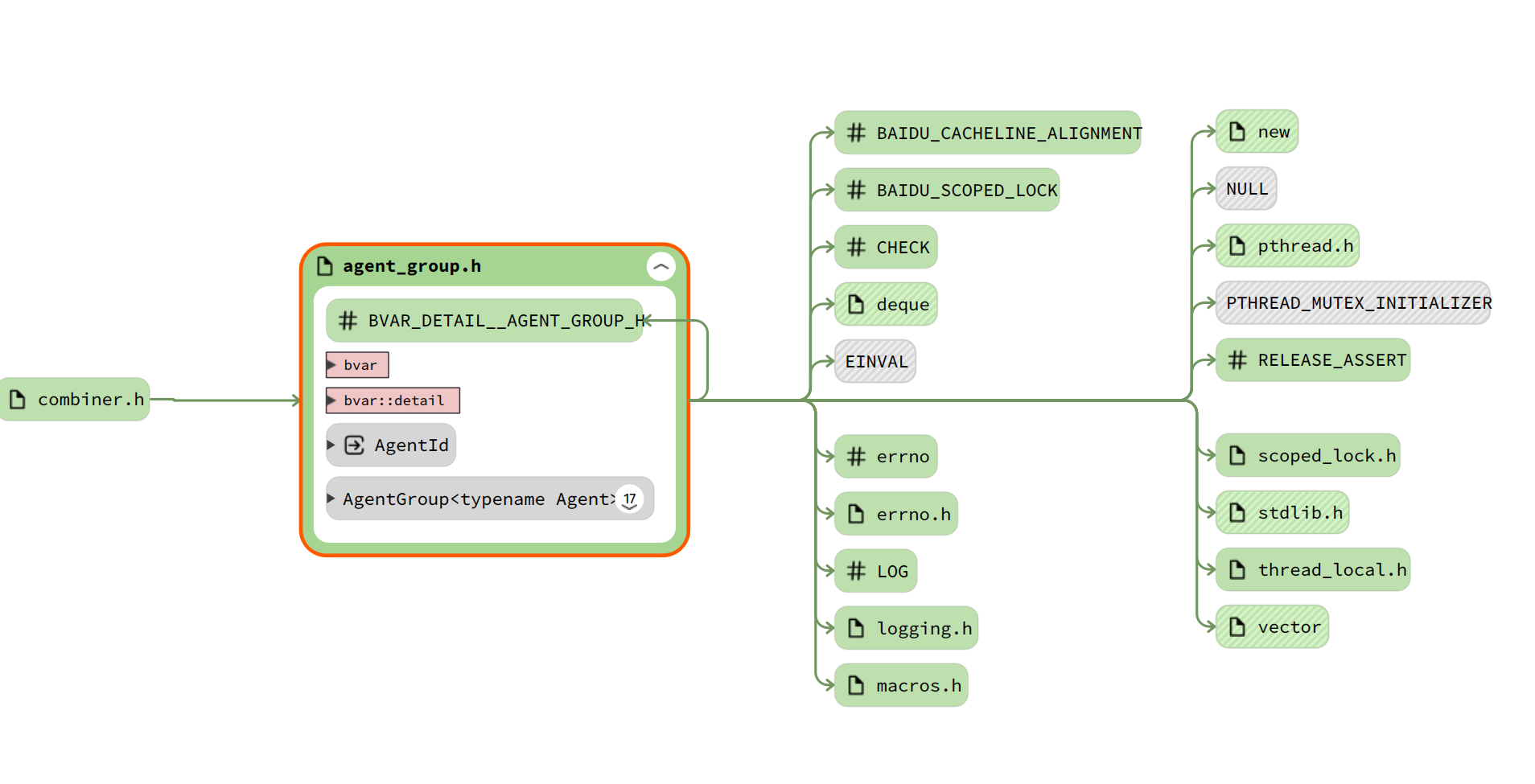
AgentGroup类(维护thread_local数组)
AgentGroup类是bvar实现中一个特别重要的类,它实现了统计数据中thread_local变量的保存。它提供了thread_local变量的创建、查询等功能。
下面会提到另一个类AgentCombiner, 在读取统计值时,这个类会调用AgentGroup的API去查询然后合并所有的thread_local变量。
在其它一些IntRecorder类中,需要写入统计值时,就会调用AgentGroup的API去创建thread_local变量和修改值。
简单理解起来,AgentGroup像不像一个数据中心,申请内存管理所有的thread_local变量、以及在析构时释放内存、clear和reset thread_local变量等。
thread_local变量如何保存以及定义的
详细的变量和成员变量注释,为了清晰,补充到代码注释中了,如下:
C++ template < typename Agent >
class AgentGroup {
// 保存统计变量,按照BLOCK_SIZE进行分块,一块是ThreadBlock *,很多块就是std::vector<ThreadBlock *>
// 即是:static __thread std::vector<ThreadBlock *> *_s_tls_blocks;
const static size_t RAW_BLOCK_SIZE = 4096 ;
// 根据Agent类型判断一个BLOCK中有多少了ELEMENT元素,比如Agent是Int,sizeof(Agent)就是4
const static size_t ELEMENTS_PER_BLOCK =
( RAW_BLOCK_SIZE + sizeof ( Agent ) - 1 ) / sizeof ( Agent );
public :
typedef Agent agent_type ;
static pthread_mutex_t _s_mutex ;
static AgentId _s_agent_kinds ;
static std :: deque < AgentId > * _s_free_ids ;
static __thread std :: vector < ThreadBlock *> * _s_tls_blocks ;
};
在AgentGroup中_s_tls_blocks,声明为__thread, 就是thread_lock变量,也就是在多线程环境中,每个线程都单独保存了一份。每个线程写统计变量就是写到每个线程自己的_s_tls_blocks中,读取就会去根据ID找到所有的_s_tls_blocks中的Agent,然后合并数据。比如IntRecorder就是把所有的加起来。
通过ID去找后面会提到,每个统计量有个ID,对应每个线程中保存的数据就是Node,通过链表记录。多一个线程申请统计就会多一个Node,合并时遍历Node就可以找到统计量的所有thread_local变量了。
ThreadBlock类,保存了Agent数组,以及提供at函数获取值。
C++ struct BAIDU_CACHELINE_ALIGNMENT ThreadBlock {
inline Agent * at ( size_t offset ) { return _agents + offset ; };
private :
Agent _agents [ ELEMENTS_PER_BLOCK ];
};
C++ #if defined(COMPILER_MSVC)
# define ALIGNAS(byte_alignment) __declspec(align(byte_alignment))
#elif defined(COMPILER_GCC)
# define ALIGNAS(byte_alignment) __attribute__((aligned(byte_alignment)))
#endif
那我们要根据id获取Agent就需要通过计算先获取在vector里的哪个BLOCK,然后根据偏移量获取数组中的Agent。
C++ inline static Agent * get_tls_agent ( AgentId id ) {
if ( __builtin_expect ( id >= 0 , 1 )) {
if ( _s_tls_blocks ) {
const size_t block_id = ( size_t ) id / ELEMENTS_PER_BLOCK ;
if ( block_id < _s_tls_blocks -> size ()) {
ThreadBlock * const tb = ( * _s_tls_blocks )[ block_id ];
if ( tb ) {
return tb -> at ( id - block_id * ELEMENTS_PER_BLOCK );
}
}
}
}
return NULL ;
}
Agent模板参数
Agent模板参数是传入的一个数据类型,比如int、float等等,所以AgentGroup类就是分配一块内存去管理Agent数据,并且提供接口去查询、修改它。
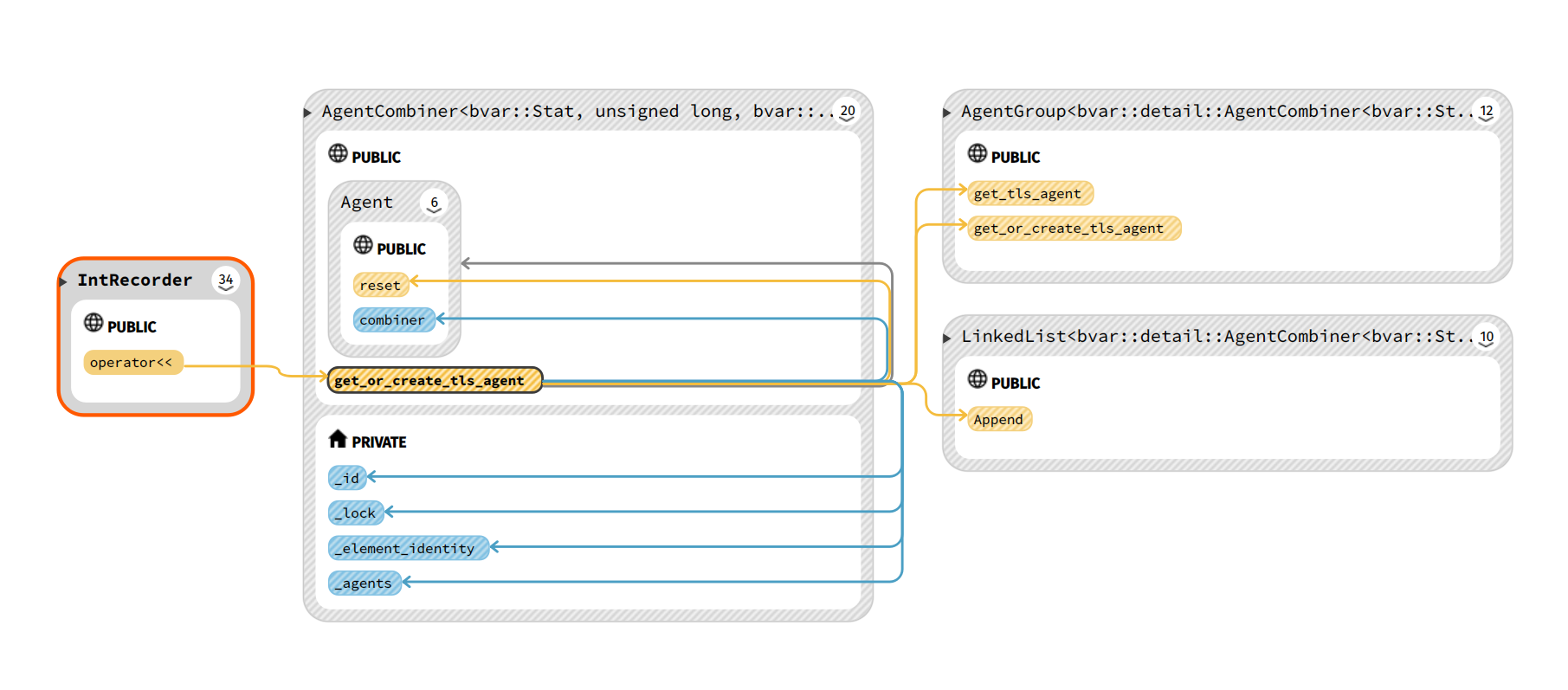
AgentCombiner类(合并读取数据)
AgentCombiner定义
AgentCombiner是个模板类,在bvar中有多个实例化的例子。
定义了_id, 在后文的get_or_create_tls_agent函数中就会通过该_id去查询各个线程上保存的thread_local变量。拿到以后就可以对变量进行写更新了。
通过链表保存的所有的Agent,也是要合并的目标值。定义了合并时的op操作,比如bar::detail::AddTo函数。
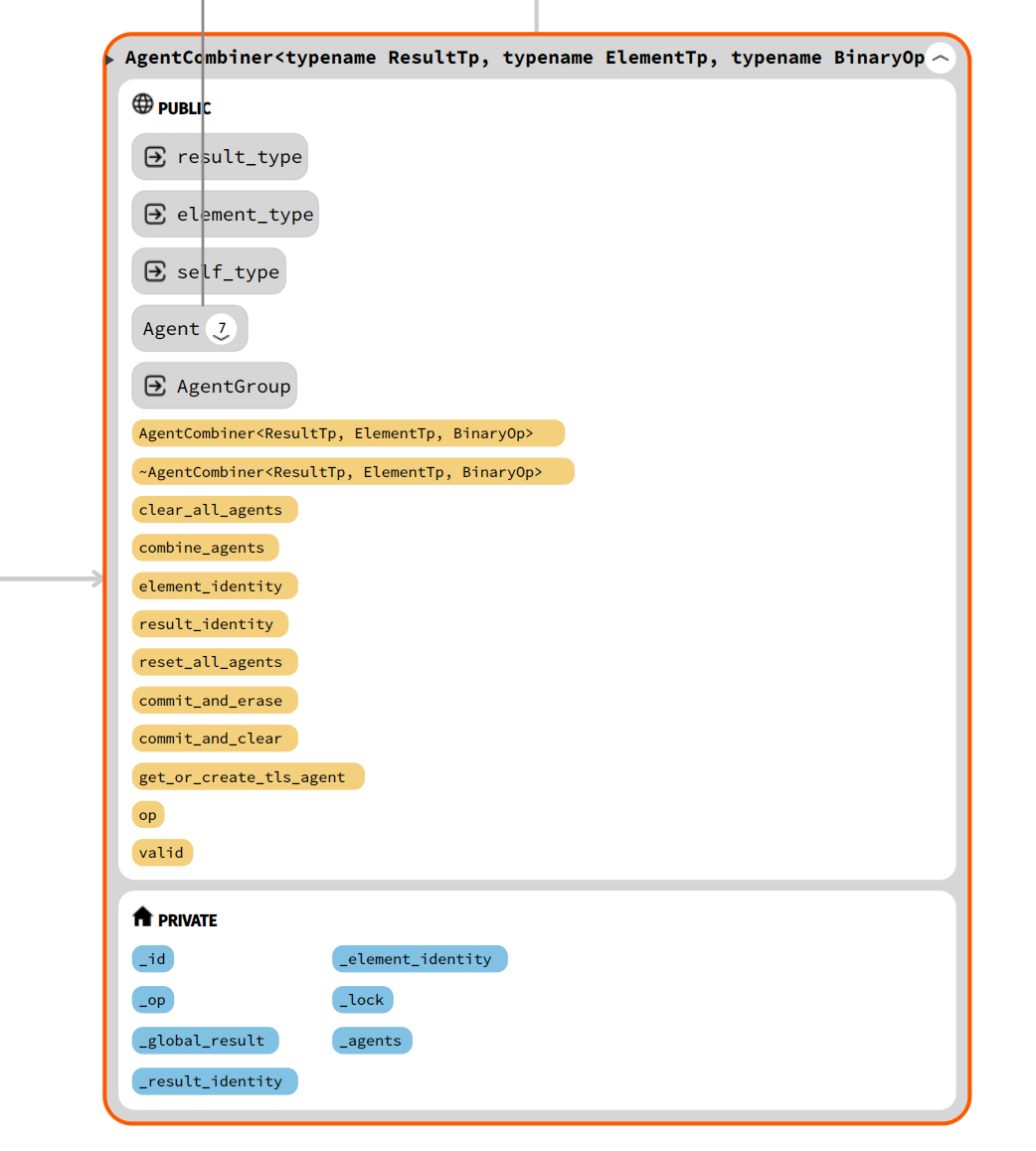
C++ template < typename ResultTp , typename ElementTp , typename BinaryOp >
class AgentCombiner {
public :
typedef ResultTp result_type ;
typedef ElementTp element_type ;
typedef AgentCombiner < ResultTp , ElementTp , BinaryOp > self_type ;
private :
explicit AgentCombiner ( const ResultTp result_identity = ResultTp (),
const ElementTp element_identity = ElementTp (),
const BinaryOp & op = BinaryOp ())
: _id ( AgentGroup :: create_new_agent ())
, _op ( op )
, _global_result ( result_identity )
, _result_identity ( result_identity )
, _element_identity ( element_identity ) {
}
// 根据这个ID去区分一个统计量(Agent),通过该ID去查询AgentGroup中保存的各个线程更新的thread_local Agent
AgentId _id ;
// 合并时的op操作,比如bar::detail::AddTo<long>函数
BinaryOp _op ;
mutable butil :: Lock _lock ;
ResultTp _global_result ;
ResultTp _result_identity ;
ElementTp _element_identity ;
// 通过链表保存的所有的Agent,也是要合并的目标值
butil :: LinkedList < Agent > _agents ;
};
两个重要函数:
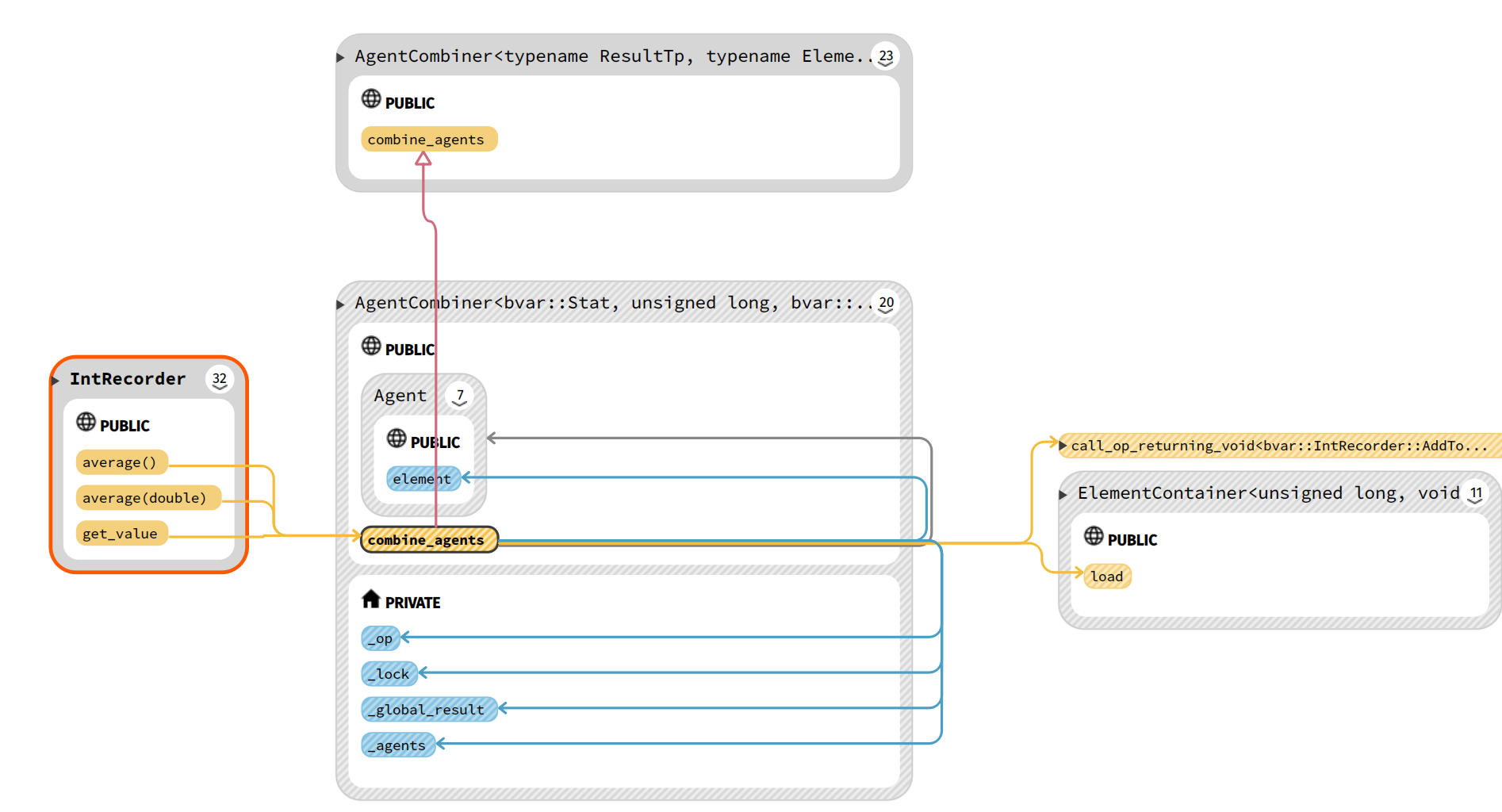
combine_agents函数
比如IntRecorder类的average()、get_value()函数,获取值或者求平均值操作,就会调用AgentCombiner的combine_agents函数。该函数遍历所有的agents,获取tls_value执行实例化时传入的op。执行合并操作,返回结果。
注意,这里可以在任意地方被调用,遍历链表需要加锁。
C++ // [Threadsafe] May be called from anywhere
ResultTp combine_agents () const {
ElementTp tls_value ;
butil :: AutoLock guard ( _lock );
ResultTp ret = _global_result ;
for ( butil :: LinkNode < Agent >* node = _agents . head ();
node != _agents . end (); node = node -> next ()) {
node -> value () -> element . load ( & tls_value );
call_op_returning_void ( _op , ret , tls_value );
}
return ret ;
}
get_or_create_tls_agent函数
这是一个关于获取value指针,即Agent*,然后写统计变量的重要函数。
还是以IntRecorder类举例,IntRecoreder类重载了 << 运算符,会调用get_or_create_tls_agent函数。
在bvar中很多重载的<<运算符的例子,比如Adder的<<就是+加号,3 + 4 + 5 如下:
Text Only
C++ // We need this function to be as fast as possible.
inline Agent * get_or_create_tls_agent () {
Agent * agent = AgentGroup :: get_tls_agent ( _id );
if ( ! agent ) {
// Create the agent
agent = AgentGroup :: get_or_create_tls_agent ( _id );
if ( NULL == agent ) {
LOG ( FATAL ) << "Fail to create agent" ;
return NULL ;
}
}
if ( agent -> combiner ) {
return agent ;
}
agent -> reset ( _element_identity , this );
// TODO: Is uniqueness-checking necessary here?
{
butil :: AutoLock guard ( _lock );
_agents . Append ( agent );
}
return agent ;
}
C++ inline IntRecorder & IntRecorder :: operator << ( int64_t sample ) {
agent_type * agent = _combiner . get_or_create_tls_agent ();
if ( BAIDU_UNLIKELY ( ! agent )) {
LOG ( FATAL ) << "Fail to create agent" ;
return * this ;
}
uint64_t n ;
agent -> element . load ( & n );
const uint64_t complement = _get_complement ( sample );
uint64_t num ;
uint64_t sum ;
do {
num = _get_num ( n );
sum = _get_sum ( n );
if ( BAIDU_UNLIKELY (( num + 1 > MAX_NUM_PER_THREAD ) ||
_will_overflow ( _extend_sign_bit ( sum ), sample ))) {
// Although agent->element might have been cleared at this
// point, it is just OK because the very value is 0 in
// this case
agent -> combiner -> commit_and_clear ( agent );
sum = 0 ;
num = 0 ;
n = 0 ;
}
} while ( ! agent -> element . compare_exchange_weak (
n , _compress ( num + 1 , sum + complement )));
return * this ;
}
IntRecorder类 (更新/写统计量数据)
上面已经很多次谈到了IntRecorder类了,在介绍读和写thread_local变量时,最上层的调用都是从这个例子出发的。
IntRecoreder定义
IntRecoreder中记录了num和sum,num就是一共统计了多少了数,sum就是所有数的累计和。
保存数据通过自定义的Compressing format,20bit保存num,44bit保存sum,也就是用int64_t就保存了这两个数。
C++ // For calculating average of numbers.
// Example:
// IntRecorder latency;
// latency << 1 << 3 << 5;
// CHECK_EQ(3, latency.average());
class IntRecorder : public Variable {
// Compressing format:
// | 20 bits (unsigned) | sign bit | 43 bits |
// num sum
const static size_t SUM_BIT_WIDTH = 44 ;
const static uint64_t MAX_SUM_PER_THREAD = ( 1ul << SUM_BIT_WIDTH ) - 1 ;
const static uint64_t MAX_NUM_PER_THREAD = ( 1ul << ( 64ul - SUM_BIT_WIDTH )) - 1 ;
public :
int64_t average () const ;
Stat get_value () const ;
private :
combiner_type _combiner ;
sampler_type * _sampler ;
std :: string _debug_name ;
};
// 重载operator<<
inline IntRecorder & IntRecorder :: operator << ( int64_t sample ){
...
};
IntRecoreder向上提供了get_value()、average()等函数接口,被LatencyRecorder、Window等调用,用于计算统计值。
除了IntRecorder类,还有很多Maxer、Adder、PassiveStatus等类,它们都继承自Variable类。
相信以上的讲解,大致理清了bvar源码实现的脉络。我们通过一个个实现例子,自底向上,分析了从thread_local变量的申请,到IntRecorder的实现。
感谢您的阅读,感兴趣的朋友可以结合文章阅读apache/brpc中bvar源码 效果更佳。