关于阅读源码的一点心得
朋友们,阅读优秀的源码可以学到很多,例如代码的结构组织、设计模式、为了解决一些问题特殊处理、写法技巧、优化策略等,同时也扩展了对编程语言的熟悉程度、关于这个项目的解决问题思路。
朋友们,阅读优秀的源码可以学到很多,例如代码的结构组织、设计模式、为了解决一些问题特殊处理、写法技巧、优化策略等,同时也扩展了对编程语言的熟悉程度、关于这个项目的解决问题思路。
MPI(Message Passing Interface,消息传递接口)是一种并行计算的通信标准,主要用于在分布式内存系统中实现多进程间的数据交换和协同计算。它是高性能计算(HPC)领域的核心工具之一,尤其适用于超级计算机和集群环境。MPI是独立于硬件和编程语言的规范,主流实现(如OpenMPI、MPICH)支持C/C++、Fortran等语言,可在Linux、Windows等系统运行。
类似linux操作系统管理内存的机制,paged_attention用于管理LLM推理时kv cache的显存分配,通过页表机制,优化显存分配,减少碎片。
(本文主要内容译自build-your-own-llama-3-architecture-from-scratch-using-pytorch)
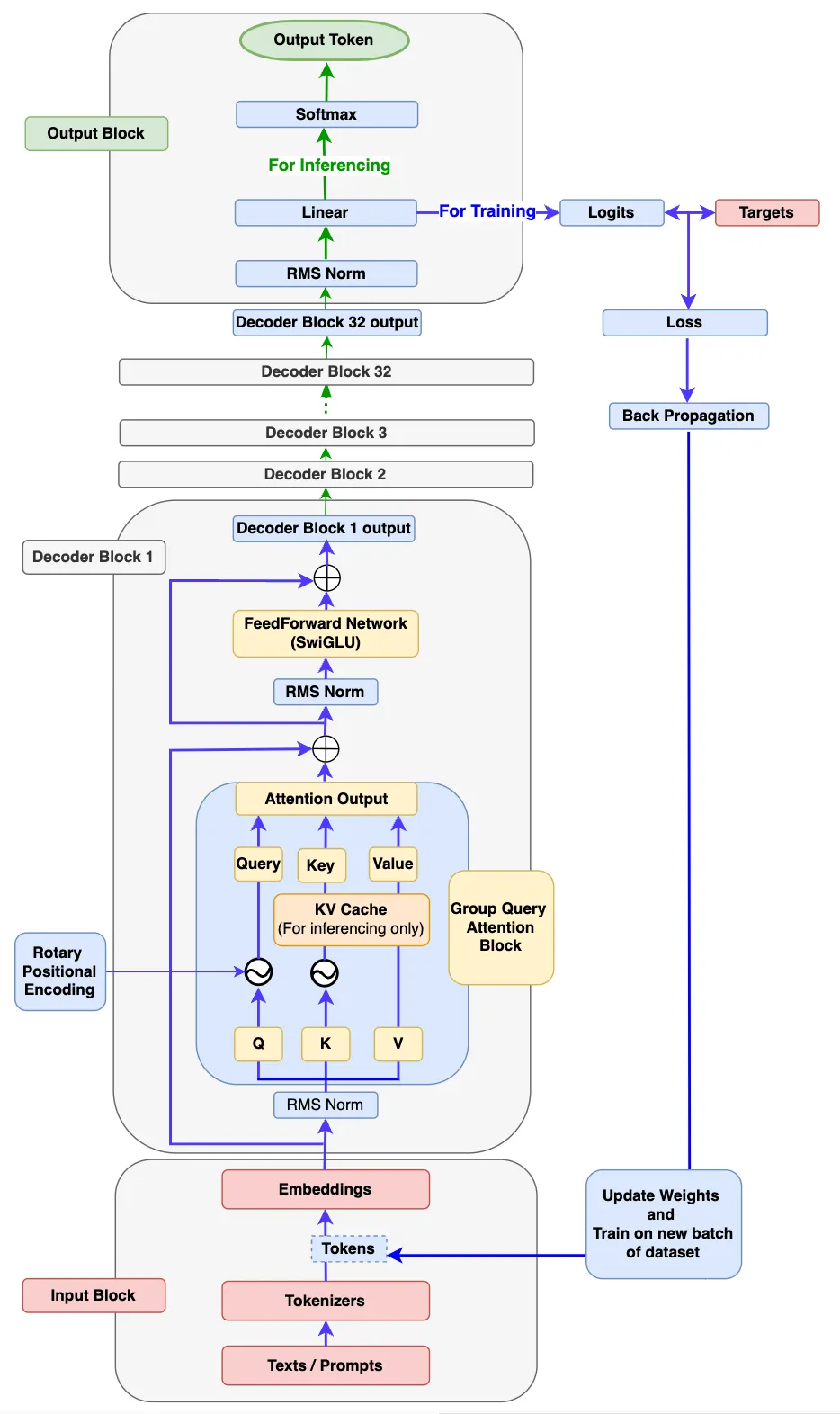
朋友们,书接上文,上一篇的Llama3还没有分享完,接着分享输出模块(Output Block)和训练、推理。
最终Decode Block的解码器(decoder)输出将输入到Output Block中。首先,它被输入到 RMSNorm 中。然后,它将被输入到线性层中用于生成logits。
接下来,会发生以下两种操作之一。
(本文主要内容译自build-your-own-llama-3-architecture-from-scratch-using-pytorch)
先看一下LLama3模型结构,这个是译文作者根据LLama3论文画的,画得很好。图中包括了训练和推理的流程。