LLM推理:采用投机采样加速推理[译]
推测解码¶
关于投机采样是什么这里就不赘述了,参考这篇大佬的文章大模型推理妙招—投机采样(Speculative Decoding),解释的很清晰。
vllm框架对投机采样(Speculative Decoding)进行了支持, 见spec_decode。
投机采样也可以翻译为推测解码,我觉得推测解码会更加容易理解一些,下文采用推测解码。
推测解码是一种推理优化技术,它在生成当前Token的同时,对未来的Token进行有根据的猜测,这一切都在一次前向传播中完成。它融入了一种验证机制,以确保这些推测出的Token的正确性,从而保证推测解码的整体输出与普通解码的输出相同。优化大语言模型(LLMs)的推理成本,可以说是降低生成式人工智能成本并提高其应用率的最关键因素之一。为了实现这一目标,有各种推理优化技术可用,包括自定义内核、输入请求的动态批处理以及大型模型的量化。
可以肉眼上直观观察哈效果:
在实验中,与非推测解码版本相比,推测解码版本在Llama2 13B聊天模型上的速度快近一倍,在Granite 20B代码模型上的速度快近两倍。
推测解码有两种主要方法,一种是利用较小的模型(例如,将Llama 7B用作Llama 70B的推测器),另一种是添加推测头(并对其进行训练)。在IBM的PyTorch团队的实验中,我们发现添加推测头的方法在模型质量和延迟改善方面都更为有效。
效率说明¶
增加推测解码的效率说明:
-
投机者架构:目前的方法允许修改头的数量,这对应于输出的我们可以选择的token数量。增加头的数量也会增加所需的额外计算量和训练的复杂性。在实践中,对于语言模型,我们发现3 - 4个头在实际应用中效果良好,而代码模型则可以从6 - 8个头中获益。
-
计算量:增加头的数量会在两个维度上导致计算量增加,一是单次前向传播的延迟增加,二是处理多个Token所需的计算量增加。如果推测器在增加头的数量后准确率不高,就会导致计算资源浪费,增加延迟并降低吞吐量。
-
内存:每次前向传递都需要与高带宽内存(HBM)进行往返通信,增加的计算量由此得到抵消。请注意,如果我们提前正确预测3个Token,那么就节省了三次与HBM的往返时间。
我们知道decode阶段是内存限制(Memory Bound)的操作,而推测解码,通过显著提升计算访存比,并且保证和使用原始模型的采样分布完全相同。
推测器架构¶
我们确定语言模型使用3 - 4个注意力头,代码模型使用6 - 8个注意力头。在从70亿到200亿参数规模不等的不同模型中,与非推测解码相比,我们观察到延迟显著改善,且没有吞吐量损失。我们开始注意到,批量大小超过64时,吞吐量会下降,但这种情况在实际中很少发生。
美杜莎(Medusa)推理框架使推测解码流行起来;其方法是在现有模型上添加一个头,然后对其进行训练以进行推测。我们通过使“头”呈分层结构来修改美杜莎架构,其中每个头阶段预测一个单一的Token,然后将其输入到下一个头阶段。这些多阶段头如下图所示。我们正在探索通过在多个阶段和基础模型之间共享嵌入表(embeddings table)来最小化嵌入表的方法。

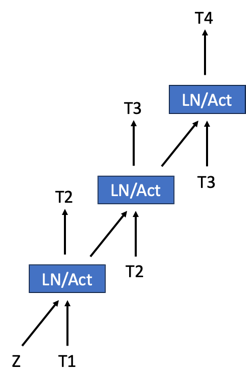
推理实现方法¶
我们在内部生产环境中运行IBM TGIS,该环境具有诸如连续批处理、融合内核和量化内核等优化措施。为了在TGIS中实现推测解码,我们修改了来自vLLM的分页注意力内核。接下来,我们将描述推理引擎为实现推测解码所做的关键更改。
推测解码基于这样一个前提,即模型足够强大,可以在单次前向传播中预测多个Token。然而,当前的推理服务器经过优化,每次只能预测一个Token。在我们的方法中,我们在大语言模型(LLM)上附加多个推测头(除了通常的那个),以预测第N+1、N+2、N+3……个Token。例如,3个推测头将预测3个额外的Token。在推理过程中实现效率和准确性存在两个挑战——一是在不复制键值缓存(KV-cache)的情况下进行预测,另一个是验证预测结果是否与原始模型的输出匹配。
在典型的生成循环中,提示词在单个前向步骤中处理完毕后,长度为1的序列(预测的下一个Token)会与键值缓存一起输入到模型的前向传递中。在一个简单的推测解码实现中,每个推测头都会有自己的键值缓存,但我们改为修改vLLM项目中开发的分页注意力内核,以实现高效的键值缓存维护。这确保了在更大的批量大小下吞吐量不会降低。此外,我们修改注意力掩码,以便对第N+1个Token进行验证,从而在不偏离原始模型输出的情况下实现推测解码。此实现的详细信息见此处foundation-model-stack/fms-extras。
投机模型训练¶
出于效率考虑,我们采用两阶段方法来训练推测器。在第一阶段,我们使用长序列长度(4000个Token)的小批次数据进行训练,并采用标准的因果语言模型方法进行训练。在第二阶段,我们使用从基础模型生成的短序列长度(256个Token)的大批量数据。在这个训练阶段,我们调整头以匹配基础模型的输出。通过大量实验,我们发现第一阶段与第二阶段的步数比例为5:2时效果良好。我们在下图中展示了这些阶段的进展情况。我们使用PyTorch FSDP和IBM FMS来训练推测器。
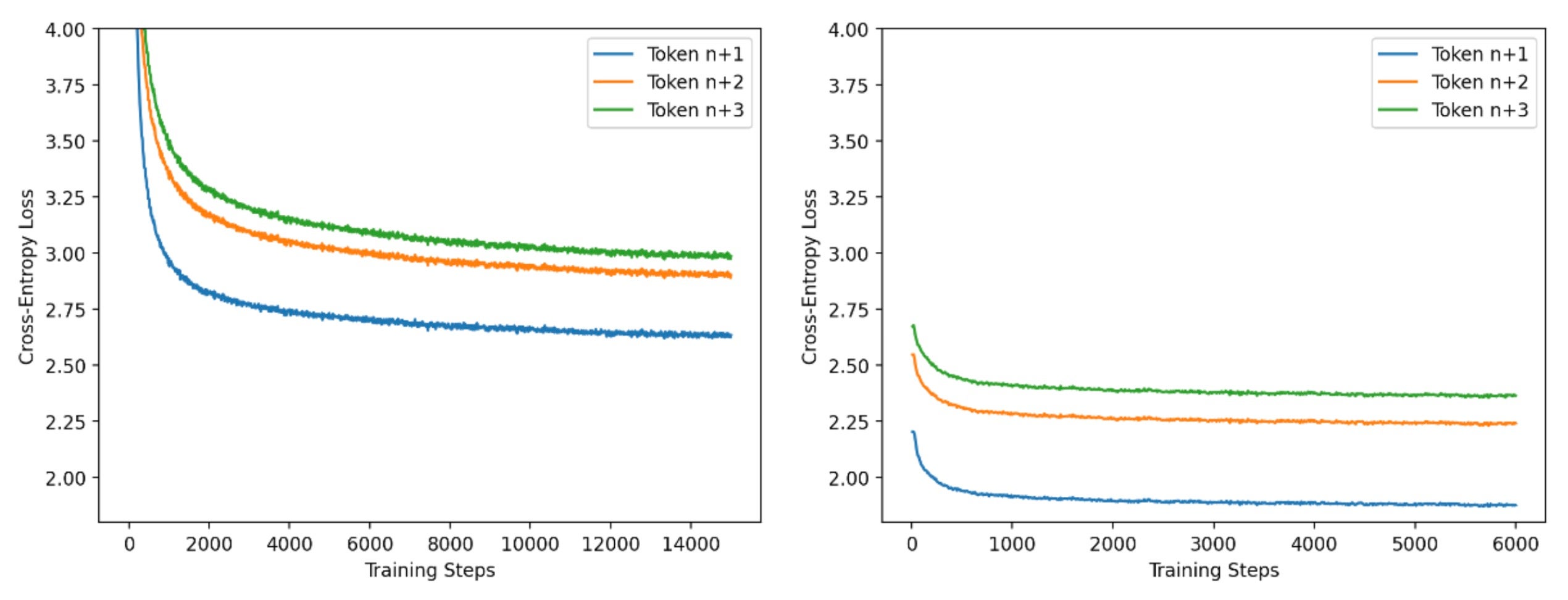
(本文译自hitchhikers-guide-speculative-decoding)