LLM推理:量化算法杂记
llama4¶
llama4目前支持:fbgemm 和 compressed-tensor 。
per_channel和per_token的区别¶
属于不同的量化策略:
将模型的权重量化为 8 位/channel,将激活量化为 8 位/token(也称为 fp8 或 w8a8)。
以激活X [Txh]和权重W [hxh0]的矩阵相乘为例,特征维度就是指h这个维度。不论是 per-token(针对激活 x 而言:每行对应一个量化系数) 还是 per-channel (针对权重 w 而言:每列对应一个量化系数)量化,都会受到这些离群值的很大影响。LLM.int8()
LLM.int8¶
LLM.int8()(8-bit Matrix Multiplication for Transformers at Scale)是一种采用混合精度分解的量化方法。该方案先做了一个矩阵分解,对绝大部分权重和激活用8bit量化(vector-wise)。对离群特征的几个维度保留16bit,对其做高精度的矩阵乘法。
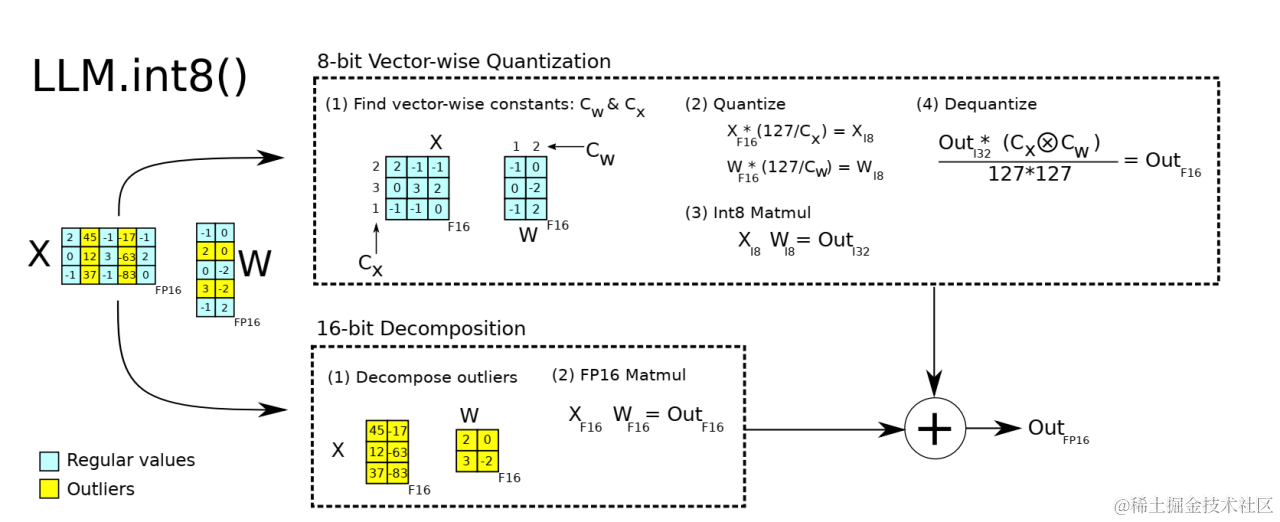
是一种outlier-aware quantization(离群值感知量化)。
使用量化就会推理更快吗?错误的。 LLM.int8() 方法的主要目的是在不降低性能的情况下降低大模型的应用门槛,使用了 LLM.int8() 的 BLOOM-176B 比 FP16 版本慢了大约 15% 到 23%。。我理解,以LLM.in8方式为例,引入量化后,只是降低了显存占用,但是计算步骤增加,推理速度也会变慢。
SmoothQuant 量化方案¶
由于量化前的激活值变化范围较大,即使对于同一 token,不同channel数值差异较大,对每个 token 的量化也会造成精度损失,但是不难看出较大值一般出现在同一 channel,因此作者也分析了采用 per-channel 的量化方式,这种量化方式能很好的避免精度损失,但是硬件不能高效执行,增加了计算时间,因此大多数量化仍采用 per-token 及 per-tensor 的量化方式。
transformers实现的各种量化¶
https://github.com/huggingface/transformers/blob/main/docs/source/en/quantization/fbgemm_fp8.md
w8a8和w4a16¶
在过去的部署里,我们很难协调一个问题,当用户的输入和输出都比较长时,我们应该给用户推荐怎么样的量化方案?W4A16 有更好的 Decode 性能,但会造成很长的 TTFT(甚至大于 FP16);W8A8 确实可以更快完成 Prefill,但时延却不一定短于 W4A16,更长的时延也不利于更大的吞吐。有没有可能两个阶段使用不同的量化方案呢?在单部署只保存一份模型权重的情况下,这是做不到的。
所幸 P-D 分离终于为我们提供了 Prefill 和 Decode 分开部署的方案。基于 P-D 分离的方案,我们可以自由地在 Prefill 机器部署 FP16 / W8A8 的模型文件,来获得相对不错的 Prefill 性能;而 Decode 机器则可以自由地选择 W4A16 / W4A8 的方案,来获得整体的更优性能。这是 P-D 分离在部署上的额外收益,为部署模型精度提供了更多的选择。
https://mp.weixin.qq.com/s/Zs61CDerMwI7JKbFyD001Q