#include"llvm/IR/PassManager.h"#include"llvm/Passes/PassBuilder.h"#include"llvm/Passes/PassPlugin.h"#include"llvm/Support/raw_ostream.h"usingnamespacellvm;namespace{// 在LLVM中,所有的Pass都必须继承自CRTP(Curiously Recurring Template Pattern)混入类PassInfoMixin。这种设计模式允许Pass通过模板机制来获得与Pass相关的元信息。structFunctionListerPass:publicPassInfoMixin<FunctionListerPass>{// A pass should have a run methodPreservedAnalysesrun(Function&F,FunctionAnalysisManager&FAM){// outs() returns a reference to a raw_fd_ostream for standard output.outs()<<F.getName()<<'\n';returnPreservedAnalyses::all();}};}PassPluginLibraryInfogetPassPluginInfo(){constautocallback=[](PassBuilder&PB){PB.registerPipelineStartEPCallback([&](ModulePassManager&MPM,auto){MPM.addPass(createModuleToFunctionPassAdaptor(FunctionListerPass()));returntrue;});};return{LLVM_PLUGIN_API_VERSION,"name","0.0.1",callback};};// 当驱动程序加载一个插件时,它会调用这个入口点以获取有关该插件的信息,以及如何注册其Pass的信息。extern"C"LLVM_ATTRIBUTE_WEAKPassPluginLibraryInfollvmGetPassPluginInfo(){returngetPassPluginInfo();}
PreservedAnalysesrun(Module&M,ModuleAnalysisManager&MPM){autoglobalVars=M.globals();for(GlobalVariable&gvar:globalVars){if(gvar.use_empty()){outs()<<"Unused global variable: "<<gvar.getName()<<"\n";}}returnPreservedAnalyses::all();}
// main.cpp部分代码PreservedAnalysesrun(Module&M,ModuleAnalysisManager&MPM){for(Function&F:M){if(!F.isDeclaration()){intnBlocks=0;outs()<<"----------------------------------------------------------------------\n";outs()<<"Counting and printing basic blocks in the function "<<F.getName()<<"\n";for(BasicBlock&BB:F){BB.print(outs());outs()<<"\n";nBlocks++;}outs()<<"Number of basic blocks: "<<nBlocks<<"\n";}}returnPreservedAnalyses::all();}
voidDfs(BasicBlock*currentBlock){staticstd::unordered_map<BasicBlock*,bool>visited;visited[currentBlock]=true;currentBlock->print(outs());for(BasicBlock*bb:successors(currentBlock)){if(!visited[bb]){Dfs(bb);}}}PreservedAnalysesrun(Module&M,ModuleAnalysisManager&MPM){for(Function&F:M){if(!F.isDeclaration()){outs()<<"----------------------------------------------------------------\n";outs()<<"Running DFS for the function "<<F.getName()<<"\n";BasicBlock&entryBlock=F.getEntryBlock();Dfs(&entryBlock);}}returnPreservedAnalyses::all();}
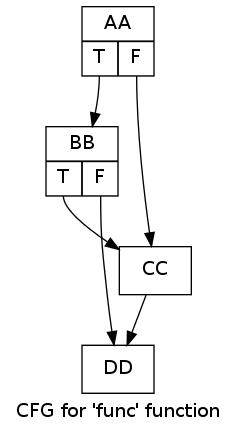
# 安装dot工具sudoaptinstallgraphviz
# Generate the LLVM IRclang-16-S-emit-llvmtest.c-otest.ll
# Print Control-Flow Graph to 'dot' file.opt-16-dot-cfg-disable-output-enable-new-pm=0test.ll
# Generate an image from the 'dot' filedot-Tpng-oimg.png.main.dot
std::vector<std::unique_ptr<Instruction>>GetInstructions(conststd::string&file_name){std::ifstreamifile(file_name);std::stringinstruction_line;std::vector<std::unique_ptr<Instruction>>instructions;if(!ifile.is_open()){fatal_error("Failed to open file: "+file_name);}while(std::getline(ifile,instruction_line)){std::istringstreamstream(instruction_line);std::stringinstruction_type;int64_tval1,val2;charcomma;if(stream>>instruction_type>>val1>>comma>>val2){instructions.push_back(std::make_unique<Instruction>(instruction_type,val1,val2));}else{fatal_error("Invalid instruction format: "+instruction_line);}}returninstructions;}
voidAddFunctionsToIR(llvm::LLVMContext&ctx,llvm::Module*module,conststd::string&function_name){autoint64_type=llvm::Type::getInt64Ty(ctx);std::vector<llvm::Type*>params(2,int64_type);llvm::IRBuilder<>ir_builder(ctx);llvm::FunctionType*function_type=llvm::FunctionType::get(int64_type,params,false);llvm::Function*func=llvm::Function::Create(function_type,llvm::Function::ExternalLinkage,function_name,module);// Create the entry block for the functionllvm::BasicBlock*basic_block=llvm::BasicBlock::Create(ctx,"entry",func);// Append instructions to the basic blockir_builder.SetInsertPoint(basic_block);autoargs=func->args();autoarg_iter=args.begin();llvm::Argument*arg1=arg_iter++;llvm::Argument*arg2=arg_iter;llvm::Value*result=nullptr;if(function_name=="add"){result=ir_builder.CreateAdd(arg1,arg2);}elseif(function_name=="sub"){result=ir_builder.CreateSub(arg1,arg2);}elseif(function_name=="mul"){result=ir_builder.CreateMul(arg1,arg2);}elseif(function_name=="xor"){result=ir_builder.CreateXor(arg1,arg2);}else{fatal_error("Invalid function name: "+function_name);}// return the valueir_builder.CreateRet(result);}
/*Initialize the native target corresponding to the host*/llvm::InitializeNativeTarget();/* Calling this function is also necessary for code generation. It sets up the assembly printer for the native host architecture.*/llvm::InitializeNativeTargetAsmPrinter();
if(autoerr=jit->get()->addIRModule(llvm::orc::ThreadSafeModule(std::move(module),std::make_unique<llvm::LLVMContext>()))){fatal_error("Failed to add IR module for JIT compilation: "+llvm::toString(std::move(err)));}
llvm::orc::ExecutorAddrGetExecutorAddr(llvm::orc::LLJIT&jit,conststd::string&function_name){autosym=jit.lookup(function_name).get();if(!sym){fatal_error("Function not found in JIT: "+function_name);}returnsym;}
#include<iostream>#include<string>#include<fstream>#include<sstream>#include<unordered_map>#include<vector>#include<memory>#include<llvm/IR/LLVMContext.h>#include<llvm/IR/Function.h>#include<llvm/IR/Module.h>#include<llvm/IR/IRBuilder.h>#include<llvm/Support/TargetSelect.h>#include<llvm/ExecutionEngine/Orc/LLJIT.h>#include<llvm/Support/Error.h>#include<llvm/Support/raw_ostream.h>structInstruction{std::stringname;int64_tval1;int64_tval2;Instruction(conststd::string&name,int64_tval1,int64_tval2):name(name),val1(val1),val2(val2){}};voidfatal_error(conststd::string&message){std::cerr<<message<<std::endl;std::exit(1);}std::vector<std::unique_ptr<Instruction>>GetInstructions(conststd::string&file_name){std::ifstreamifile(file_name);std::stringinstruction_line;std::vector<std::unique_ptr<Instruction>>instructions;if(!ifile.is_open()){fatal_error("Failed to open file: "+file_name);}while(std::getline(ifile,instruction_line)){std::istringstreamstream(instruction_line);std::stringinstruction_type;int64_tval1,val2;charcomma;if(stream>>instruction_type>>val1>>comma>>val2){instructions.push_back(std::make_unique<Instruction>(instruction_type,val1,val2));}else{fatal_error("Invalid instruction format: "+instruction_line);}}returninstructions;}voidAddFunctionsToIR(llvm::LLVMContext&ctx,llvm::Module*module,conststd::string&function_name){autoint64_type=llvm::Type::getInt64Ty(ctx);std::vector<llvm::Type*>params(2,int64_type);llvm::IRBuilder<>ir_builder(ctx);llvm::FunctionType*function_type=llvm::FunctionType::get(int64_type,params,false);llvm::Function*func=llvm::Function::Create(function_type,llvm::Function::ExternalLinkage,function_name,module);llvm::BasicBlock*basic_block=llvm::BasicBlock::Create(ctx,"entry",func);// Append instructions to the basic blockir_builder.SetInsertPoint(basic_block);autoargs=func->args();autoarg_iter=args.begin();llvm::Argument*arg1=arg_iter++;llvm::Argument*arg2=arg_iter;llvm::Value*result=nullptr;if(function_name=="add"){result=ir_builder.CreateAdd(arg1,arg2);}elseif(function_name=="sub"){result=ir_builder.CreateSub(arg1,arg2);}elseif(function_name=="mul"){result=ir_builder.CreateMul(arg1,arg2);}elseif(function_name=="xor"){result=ir_builder.CreateXor(arg1,arg2);}else{fatal_error("Invalid function name: "+function_name);}ir_builder.CreateRet(result);}llvm::orc::ExecutorAddrGetExecutorAddr(llvm::orc::LLJIT&jit,conststd::string&function_name){autosym=jit.lookup(function_name).get();if(!sym){fatal_error("Function not found in JIT: "+function_name);}returnsym;}intmain(){llvm::LLVMContextctx;llvm::InitializeNativeTarget();llvm::InitializeNativeTargetAsmPrinter();automodule=std::make_unique<llvm::Module>("neko_module",ctx);AddFunctionsToIR(ctx,module.get(),"add");AddFunctionsToIR(ctx,module.get(),"sub");AddFunctionsToIR(ctx,module.get(),"mul");AddFunctionsToIR(ctx,module.get(),"xor");autojit_builder=llvm::orc::LLJITBuilder();autojit=jit_builder.create();if(!jit){fatal_error("Failed to create JIT: "+llvm::toString(jit.takeError()));}if(autoerr=jit->get()->addIRModule(llvm::orc::ThreadSafeModule(std::move(module),std::make_unique<llvm::LLVMContext>()))){fatal_error("Failed to add IR module for JIT compilation: "+llvm::toString(std::move(err)));}autoinstructions=GetInstructions("code.txt");std::unordered_map<std::string,llvm::orc::ExecutorAddr>fn_symbols;for(constauto&instruction:instructions){if(fn_symbols.find(instruction->name)==fn_symbols.end()){fn_symbols[instruction->name]=GetExecutorAddr(*jit->get(),instruction->name);}auto*fn=reinterpret_cast<int64_t(*)(int64_t,int64_t)>(fn_symbols[instruction->name].getValue());int64_tvalue=fn(instruction->val1,instruction->val2);std::cout<<value<<std::endl;}return0;}