MPI是什么?有哪些集体通信操作以及在TensorRT LLM中应用
MPI介绍¶
MPI(Message Passing Interface,消息传递接口)是一种并行计算的通信标准,主要用于在分布式内存系统中实现多进程间的数据交换和协同计算。它是高性能计算(HPC)领域的核心工具之一,尤其适用于超级计算机和集群环境。MPI是独立于硬件和编程语言的规范,主流实现(如OpenMPI、MPICH)支持C/C++、Fortran等语言,可在Linux、Windows等系统运行。
学习并行编程(parallel programming),或者说分布式编程、并行编程,就需要学习MPI,比如把点对点通信和集体性通信这两个机制合在一起已经可以创造十分复杂的并发程序了。可以通过mpitutorial学习,教程采用了MPICH2实现相关代码。
集体性通信方式¶
点对点通信方式比较好理解,比如采用MPI_Send和MPI_Recv函数,发送方发送数据,接收方接收数据。
广播通信:MPI_Bcast¶
MPI_Scatter¶
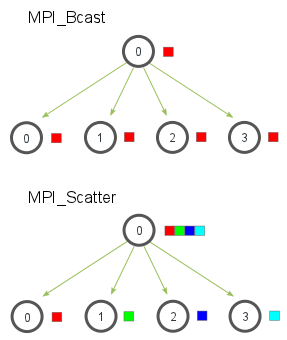
MPI_Bcast 给每个进程发送的是同样的数据,然而 MPI_Scatter 给每个进程发送的是一个数组的一部分数据。
MPI_Gather¶
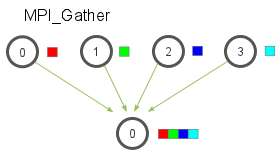
MPI_Gather 跟 MPI_Scatter 是相反的。MPI_Gather 从好多进程里面收集数据到一个进程上面而不是从一个进程分发数据到多个进程。
MPI_Allgather¶
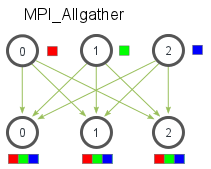
MPI_Allgather会收集所有数据到所有进程上。
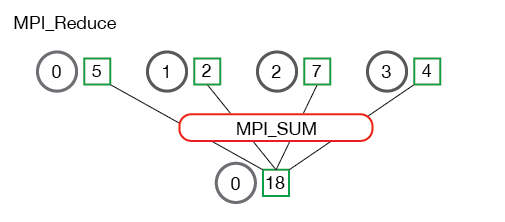
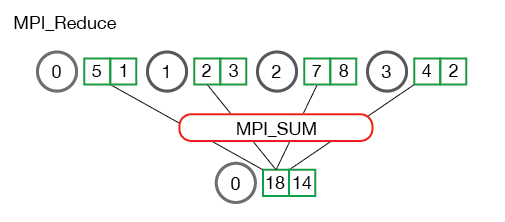
归约: MPI_Reduce¶
与 MPI_Gather 类似,MPI_Reduce 在每个进程上获取一个输入元素数组,并将输出元素数组返回给根进程。
MPI 定义的归约操作包括:
MPI_MAX - 返回最大元素。 MPI_MIN - 返回最小元素。 MPI_SUM - 对元素求和。 MPI_PROD - 将所有元素相乘。 MPI_LAND - 对元素执行逻辑与运算。 MPI_LOR - 对元素执行逻辑或运算。 MPI_BAND - 对元素的各个位按位与执行。 MPI_BOR - 对元素的位执行按位或运算。 MPI_MAXLOC - 返回最大值和所在的进程的秩。 MPI_MINLOC - 返回最小值和所在的进程的秩。
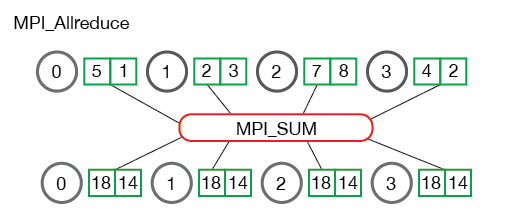
MPI_Allreduce¶
许多并行程序中,需要在所有进程而不是仅仅在根进程中访问归约的结果。 以与 MPI_Gather 相似的补充方式,MPI_Allreduce 将归约值并将结果分配给所有进程。
MPI在模型推理部署中的应用¶
例如,在TRT-LLM框架中多实例支持,TensorRT-LLM 后端依赖 MPI 在多个 GPU 和节点之间协调模型的执行。目前,有两种不同的模式支持在多个 GPU 上运行模型,领导者模式和协调器模式。
Leader Mode¶

在领导模式下,TensorRT-LLM 后端为每个 GPU 生成一个 Triton Server 进程。秩为 0 的进程是领导进程。其他 Triton Server 进程不会从TRITONBACKEND_ModelInstanceInitialize调用中返回,以避免端口冲突并允许其他进程接收请求。
Orchestrator Mode¶

在编排器模式下,TensorRT-LLM 后端会生成一个单一的 Triton Server 进程,该进程充当编排器,并为每个模型所需的每个 GPU 生成一个 Triton Server 进程。此模式主要在使用 TensorRT-LLM 后端为多个模型提供服务时使用。在此模式下,MPI的world size必须为 1,因为 TRT-LLM 后端会根据需要自动创建新的工作进程。
此模式使用了MPI_Comm_spawn,目前此模式仅适用于单节点部署。
部署区别¶
与其他 Triton 后端模型不同,TensorRT-LLM 后端不支持使用instance_group设置来确定模型实例在不同 GPU 上的放置。需要使用领导者模式和编排器模式在不同 GPU 上运行 LLaMa 模型的多个实例。
假设有四个 GPU,CUDA 设备 ID 分别为 0、1、2 和 3。启动两个 LLaMa2-7b 模型的实例,张量并行度为 2。第一个实例在 GPU 0 和 1 上运行,第二个实例在 GPU 2 和 3 上运行。
- Leader Mode
对于领导模式,将启动两个单独的mpirun命令来启动两个单独的 Triton 服务器,每个 GPU 对应一个服务器(总共四个 Triton 服务器实例)。还需要在它们前面使用反向代理(Nginx)来在服务器之间平衡请求负载。
在Leader Mode下,World size = TP * PP 。
- Orchestrator Mode
对于编排器模式,不需要反向代理,可以分成两个独立模型(对应需要client请求不同的模型),也可以使用trion中的load balance。
mpi内容可以查看tensorrt_llm中封装的mpiutils类。