text-generation-inference推理框架剖析
今天要介绍的主题是TGI(text-generation-inference), 是huggingface开源可用于生产环境的LLM大模型的推理部署服务。
由Router和Engine构成,Engine包括了InferServer。Router由Rust实现,InferServer由python端实现。Router相当于一个代理,面向业务会启动一个WebServer,包括对业务请求采用合适的策略进行动态Batch调整,实现大的吞吐和低的延迟。 Engine对各种LLM大语言模型进行支持,启动模型推理服务。 Router和Engine之间通过Protobuf定义消息和格式,通过GRPC方式就可以对推理服务进行访问。
介绍可以参考文档text-generation-inference-doc。
TGI优势¶
- 通过Open Telemetry进行分布式追踪和Prometheus监控指标。
- 它支持高级注意力机制,如Flash Attention和Paged Attention,确保推理优化。
- 该框架还允许通过各种配置和更细粒度的按请求配置(如引导解码以生成结构化输出)来调整服务器。
LLM推理的两个重要阶段[译]¶
本小节翻译自,Anatomy of TGI for LLM Inference。
当用户提供一段Prompt,进行tokennized得到一组tokens。输入给模型,模型服务在GPU上进行推理。LLM推理依次分为了Prefill阶段和Decode阶段。Prefill阶段对全部Prompt输入tokens进行推理,产生FirstToken(第一个Token)。然后Decode是一个SelfAttenstion的过程,将新生成的Token加到原始tokens中,然后不断的Decode过程,直到生成EOS结束。将得到的tokens转换成语言表示,就是用户得到的回答。
Prefill¶
在Prefill阶段,用户输入的Prompt经过tokennized得到tokens,这个过程通过分词将句子转换成更小的单元,这个过程可以参考模型和分词器。然后得到的tokens通过一次Forward前向推理,得到FirstToken。 比如,你问大模型,“美国的首都是?”,大模型经过Prefill阶段,返回FirstToken: “华盛顿”。
Decode¶
在Decode阶段,大语言模型通过自回归特性不断生成新的token。在这个阶段,基于Prefill预填充阶段的初始标记,模型一次生成一个标记的文本。每个新生成的标记都被添加到输入序列中,为模型处理创建新的上下文。比如,在生成“华盛顿”作为初始标记后,新的序列变为“美国的首都是哪里?华盛顿”。然后使用这个更新后的序列来生成下一个标记。
模型以迭代的方式继续这个过程,每个新标记影响下一个标记的生成。通过这种自回归方法模型即保持上下文,又生成连贯的回应。Decode解码阶段持续进行,直到生成一个序列结束(EOS)标记,或者达到由max_new_tokens指定的最大序列长度。此时,在CPU上对生成的序列进行去分词处理,将标记转换回可读的文本。
为什么要分为预填充(Prefill)和解码(Decode)阶段?¶
这两个阶段的计算特性不同,预填充阶段只需要一个前向传递,而解码阶段涉及多个传递。每个传递都依赖于之前生成的标记。解码阶段的自回归特性导致处理时间更长,计算开销随着总序列长度的增加而呈二次方增长。因此,预填充和解码阶段的分离是必要的。
为了优化这个过程,减少计算开销的二次方增长,采用了一种称为KV缓存的技术。KV缓存保存在预填充和解码阶段每个标记位置生成的中间状态,称为KV缓存。通过将这些KV缓存存储在GPU内存中,模型避免了重复计算,从而减少了计算开销。这种优化提高了解码阶段的效率。
动态Batch策略(continuous batching算法)¶
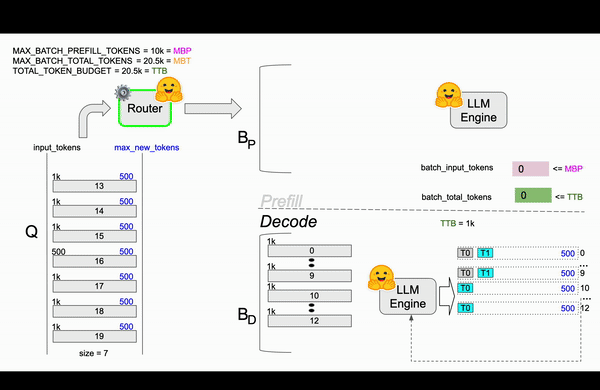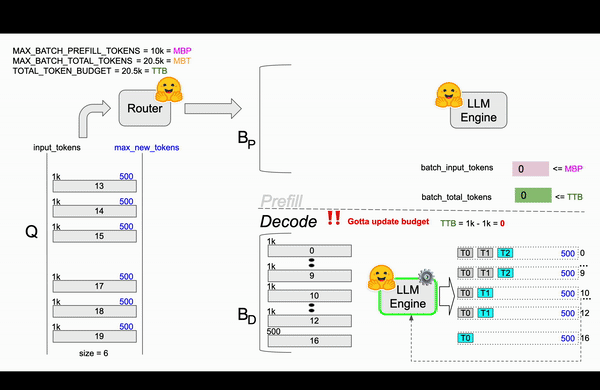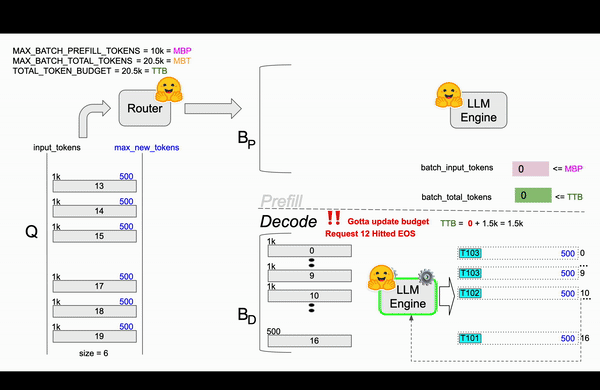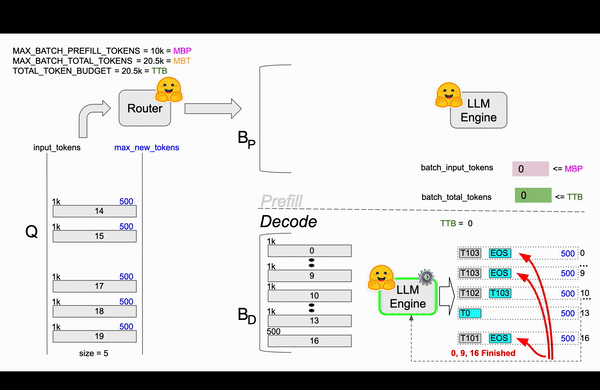
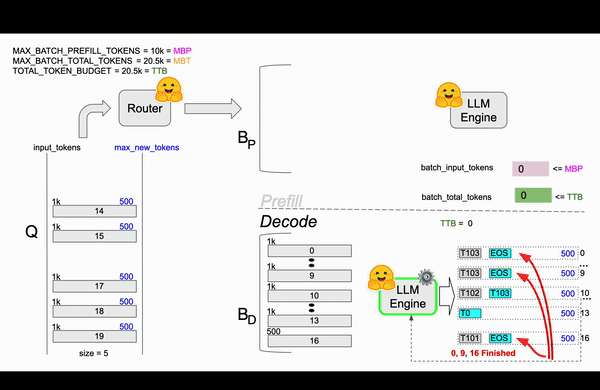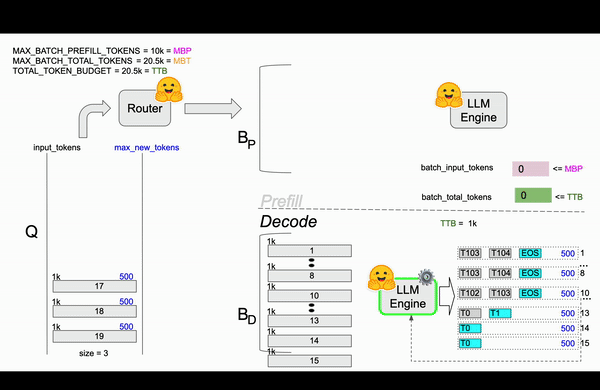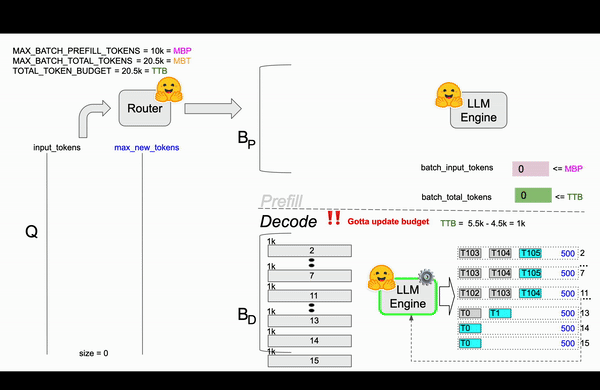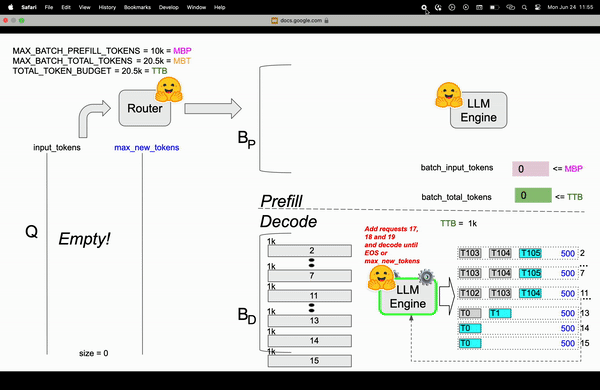
TGI在Router中实现了continuous batching算法,目的是为了避免Engine OOM(Out Of Memory)错误。 在Router中通过参数对Resquest如何组成Batch进行了限制,比较关键的参数MAX_BATCH_TOTAL_TOKENS(一个Batch最多处理多少Token)、MAX_BATCH_PREFILL_TOKENS(一个Batch的Prefill阶段最多支持多少Token)。和静态批处理不同,静态批处理需要等待前一批请求完成后才能处理下一批请求,连续批处理允许动态地向正在运行的批次中添加请求,比如在1-10请求后,先从队列中拿出13请求处理凑成Batch进行处理。
“如果没有连续批处理,延迟会非常好,但吞吐量(即在给定时间框架内允许的总请求数)会非常差(因为它基本上是1)。使用静态批处理,你或许可以达到最大吞吐量(通过使用适用于你硬件的最大总批次大小),但延迟会非常差,因为为了达到最大吞吐量,你需要等待请求进来后再进行处理。使用连续批处理,你可以找到一个最佳的平衡点。一般来说,延迟是用户最关心的最重要参数。但是,为了在同一硬件上支持10倍的用户量,延迟增加2倍是一个可以接受的权衡。” “With no continuous batching at all, latency is going to be super good, but throughput (meaning the total number of requests allowed in a given timeframe) is going to be super bad (since it’s essentially 1). With static batching, you can probably reach the maximum throughput (by using the maximum total batch size applicable to your hardware), but the latency is super bad since in order to have maximum throughput you need to wait for requests to come in before processing. With continuous batching you can find a sweet spot. In general latency is the most critical parameter users care about. But a 2x latency slowdown for 10x more users on the same hardware is an acceptable trade off”
动态批处理的处理逻辑¶
通过下面的伪代码看一下动态批处理的主要逻辑线,当然Rust实现的逻辑更加复杂、判断条件更多,后面再进行分析。
用一个例子说明算法过程[译]¶
| 变量名 | 值 | 缩写 | 含义 |
|---|---|---|---|
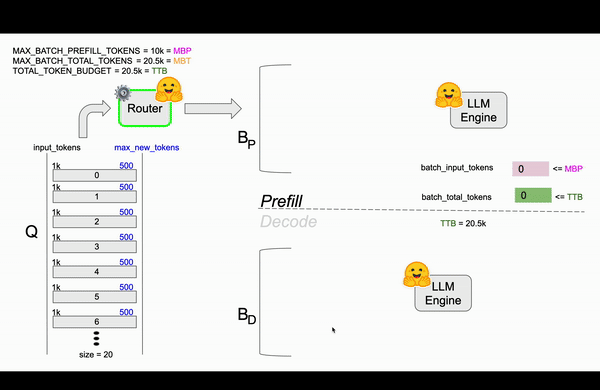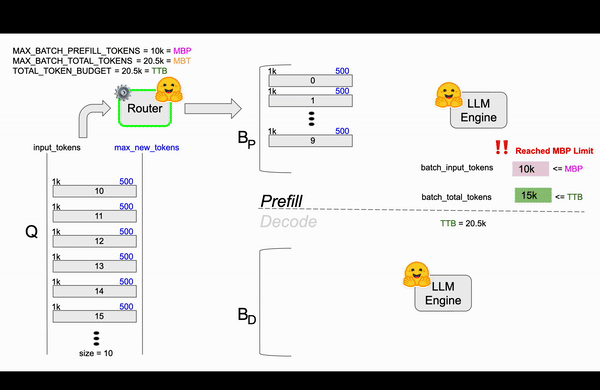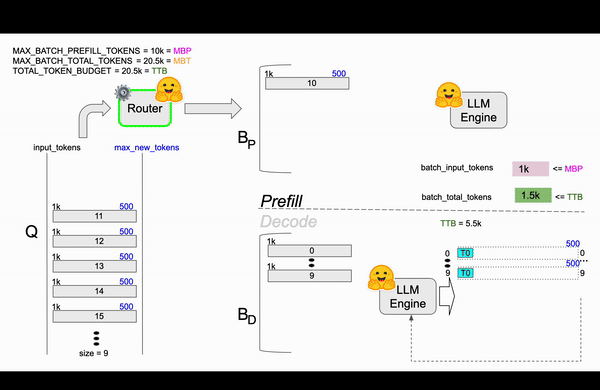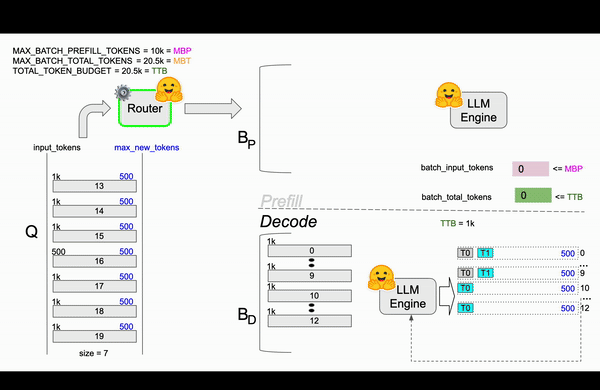
| MAX_BATCH_TOTAL_TOKENS | 20.5k | MBT | 一个Batch最多处理多少Token |
| MAX_BATCH_PREFILL_TOKENS | 10k | MBP | 一个Batch的Prefill阶段最多支持多少Token |
| TOTAL_TOKEN_BUDGET | 20.5k | TTB | 当前时刻的总的token预算,初始值和MBT一样 |
| QUEUE | 20 requests | Router实现中队列,最多支持20个请求 |
接下来开始逐帧分析这个过程,haha!!
第一帧¶
第二帧¶
第三帧¶
未完…
参考¶
Anatomy of TGI for LLM Inference
什么是 GPT?Transformer 工作原理的动画展示(2024)