zip压缩格式为什么是从后往前开始解析的?
通过对ZIP 文件格式的学习,就有了足够的信息能够逐字节手动读取和写入 ZIP 文件,知道为什么zip压缩格式为什么是从后往前开始解析的。
ZIP 文件结构概述¶
ZIP 文件由多个头部组成,包括本地文件头、中央目录文件头和中央目录结束记录。每个头部由签名和头部数据组成。

标头包括:
-
本地文件头(Local file header):包含单个文件的元数据并后跟文件数据,可独立压缩和加密。
-
中央目录文件头(Central directory file header):包含单个文件的元数据和指向本地文件头的偏移量,多个中央目录文件头形成中央目录,可快速枚举存档中的所有文件。
-
中央目录结束记录(End of central directory record):包含找到第一个中央目录文件头的信息,是 ZIP 文件的入口点。
ZIP 文件的解析的入口点是中央目录结束记录(End of central directory record),始终位于文件的末尾。 比如包含 a.txt 和 b.txt 的 ZIP 文件的可视化效果:
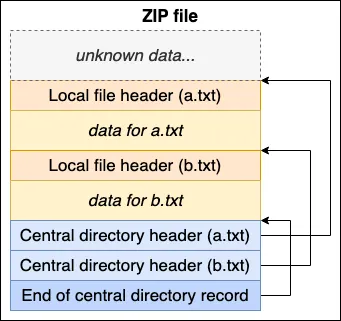
中心目录位于底部,设计上的一个好处是,我们只需附加一个新的中心目录即可覆盖它。如果我们想添加一个文件c.txt,我们可以附加该文件记录并附加一个包含它的新中央目录:
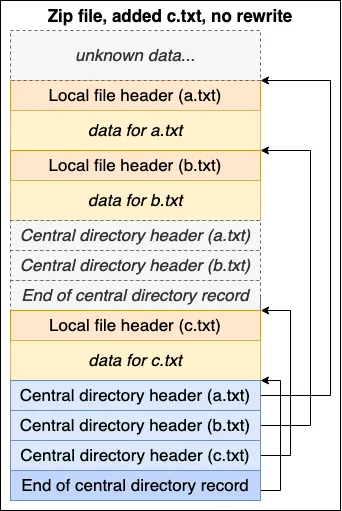
旧目录仍然存在,但不再被引用。这样我们就可以修改存档而无需重写文件。比如在历史上,当使用软盘进行存储时,此行为尤其重要。写入速度很慢,并且 ZIP 存档可能跨越多个磁盘。您不仅可以添加文件而不进行任何重写,还可以通过附加数据来修改和删除存档中的文件。当然,已删除的文件和修改后的文件的先前版本将保留在磁盘上,但兼容的 ZIP 读取工具不会读取它们。
例如:通过仅附加新数据来实现上述 “ZIP 文件” 示例的修改和删除。修改 b.txt 并从 “ZIP 文件” 中删除 a.txt 而无需任何重写。

中央目录的位置及作用¶
中央目录在文件底部,这样可以通过追加新的中央目录来添加文件,而无需重写整个文件。在使用软盘存储时这一特性尤为重要。还可以通过仅追加数据来修改和删除文件,旧版本文件仍在磁盘上但合规的 ZIP 阅读器不会读取。
ZIP 文件的有趣特性¶
-
ZIP 文件可以在开头添加任意内容使其既是有效 PNG 又是有效 ZIP(多语言文件)以隐藏 ZIP;由于 ZIP 文件是从末尾读取的,因此可以将任何内容放在 ZIP 文件的开头。例如,您可以制作一个既是有效 PNG 又是有效 ZIP(多语言文件)的文件,以隐藏外观和工作方式类似于图像的 ZIP 文件。
-
可以将 ZIP 文件附加到 ZIP 提取器二进制文件中使其自解压形成自解压存档文件;该技术Self-extracting_archive实现双击文件时自动解压缩的常用技术。
-
ZIP 格式允许在多个位置添加 “注释” 以使其与更多格式兼容;
-
ZIP 格式允许存档拆分为多个文件以应对文件大小限制。ZIP 格式允许将档案拆分为多个文件。实现此目的是为了能够将大型档案拆分到多个软盘上。今天,它可能仍可用于在上传或通过电子邮件发送更大的档案时规避文件大小限制。规范中提到了称为 “disk number” 等的字段,在处理多部分存档时,您可以将其视为 “file number”。在本文中,我们只处理单个文件存档,因此您始终可以假设这些字段是“磁盘 0”。
读取 ZIP 文件的方法¶
读取 ZIP 文件需先找到中央目录结束记录,该记录在文件末尾且长度动态,需在文件末尾一定区间内反向扫描找到签名。从中央目录结束记录可得知中央目录的偏移量和记录数量,读取中央目录文件头可获取文件的详细信息。再根据中央目录中的偏移量读取本地文件头和文件数据以提取文件。
现在让我们看看如何读取 ZIP 文件的实际字节。所有多字节数字都存储在 little-endian 中。
要读取 ZIP 文件,我们必须首先在文件末尾找到 End of central directory 记录(缩短的 EOCD)。这听起来微不足道,但有点棘手。下面是 EOCD 的定义:
| Bytes | Description |
|---|---|
| 4 | Signature (0x06054b50) |
| 2 | Number of this disk |
| 2 | Disk where central directory starts |
| 2 | Numbers of central directory records on this disk |
| 2 | Total number of central directory records |
| 4 | Size of central directory in bytes |
| 4 | Offset to start of central directory |
| 2 | Comment length (n) |
| n | Comment |
定义中的最后一行Comment使此记录的查找有点复杂, 因为记录具有动态长度。根据注释长度,EOCD 的开头将与文件末尾的偏移量不同。
- 如果 n=0 (空注释),则 EOCD 从末尾开始 22 字节
- 如果 n=0xffff(最大长度注释),则 EOCD 从末尾开始 22 + 0xffff = 65557 字节
可能存在 EOCD 签名(表格中的 Signature (0x06054b50))的间隔介于 65557 和末尾的 18 之间。总共大约 65.5 kb。这在现代计算机上并不多,因此我们可以将整个间隔读入缓冲区,然后向后扫描以查找签名。找到 EOCD 签名后,读取 ZIP 最困难的部分就完成了。其余的只是在特定偏移量处解析预定义的二进制结构。
读取中央目录(Central Directory)¶
从 EOCD 中,我们知道中央目录开始的偏移量,以及有多少条记录。所以我们只需要寻找那个偏移量并开始读取中央目录文件头。每个中央目录文件头如下所示:
| Bytes | Description |
|---|---|
| 4 | Signature (0x02014b50) |
| 2 | Version made by |
| 2 | Minimum version needed to extract |
| 2 | Bit flag |
| 2 | Compression method |
| 2 | File last modification time (MS-DOS format) |
| 2 | File last modification date (MS-DOS format) |
| 4 | CRC-32 of uncompressed data |
| 4 | Compressed size |
| 4 | Uncompressed size |
| 2 | File name length (n) |
| 2 | Extra field length (m) |
| 2 | File comment length (k) |
| 2 | Disk number where file starts |
| 2 | Internal file attributes |
| 4 | External file attributes |
| 4 | Offset of local file header (from start of disk) |
| n | File name |
| m | Extra field |
| k | File comment |
这定义了我们需要了解的有关文件的所有信息,包括我们可以在哪里找到本地文件头。由于多部分存档、压缩和加密不在本文的讨论范围之内,我们可以做出以下假设:
- 位标志(Bit flag) = 0
- 压缩方法(Compression method) = 0
- 压缩大小(Compressed size) = 未压缩大小(Uncompressed size)
- 文件开始的磁盘编号(Disk number where file starts) = 0
CRC-32 是用于检测损坏数据的校验和。这在玩具项目中可以忽略,但在实际项目中必须对其进行验证,以避免在提取时创建损坏的文件。 其余字段应该是不言自明的,除了 Extra 字段,我们稍后会回到那个字段。
提取文件¶
从中心目录我们知道所有文件的偏移量。要提取文件,我们首先读取如下所示的本地文件头:
| Bytes | Description |
|---|---|
| 4 | Signature (0x04034b50) |
| 2 | Minimum version needed to extract |
| 2 | Bit flag |
| 2 | Compression method |
| 2 | File last modification time (MS-DOS format) |
| 2 | File last modification date (MS-DOS format) |
| 4 | CRC-32 of uncompressed data |
| 4 | Compressed size |
| 4 | Uncompressed size |
| 2 | File name length (n) |
| 2 | Extra field length (m) |
| n | File name |
| m | Extra field |
本地文件头中的某些数据与中心目录中的条目重复。由于本地文件头还包含提取所需的所有数据,因此我们可以提取中央目录中不存在的文件。后跟本地文件头的是压缩大小字段中指定的长度的实际文件数据。由于我们不使用压缩或加密的数据,因此文件数据将是文件的纯文本内容。我们可以通过读取数据并根据文件名字段将其写入文件来提取该数据。
读到这里,我们成功理解了 ZIP 文件格式。
额外字段的作用¶
额外字段用于使 ZIP 格式可扩展,例如可添加加密或特定压缩算法所需的额外元数据。常见的额外字段有包含 UTC Unix 时间戳的和与 ZIP64 相关的数据的字段,也可以自定义额外字段。
extra 字段包含以下内容的列表,用于填充字段的长度:
| Bytes | Description |
|---|---|
| 2 | Header ID |
| 2 | Data length (n) |
| n | Data |
一个常见的额外字段是报头 ID 0x5455的字段,即 UTC Unix 时间戳。另一个常见的额外字段是 Header ID 0x0001的字段。此字段包含与 ZIP64 相关的数据,以允许大于 32 位的大小和偏移量。
总结¶
ZIP 格式本身简单但可扩展,有一些有趣的特性。找到入口点需扫描特定签名,但该签名可能存在于注释或中央目录结束记录自身的数据中,需验证多个偏移量的签名以确保找到真正的中央目录结束记录签名。
参考¶
https://medium.com/@felixstridsberg/the-zip-file-format-6c8a160d1c34 https://www.iana.org/assignments/media-types/application/zip https://pkware.cachefly.net/webdocs/APPNOTE/APPNOTE-6.3.9.TXT https://en.wikipedia.org/wiki/ZIP_(file_format) https://en.wikipedia.org/wiki/ZIP_(file_format)