解锁高效大规模模型训练:张量并行(TP)技术
解锁高效大规模模型训练(或推理):张量并行(TP)技术
如今,具有数十亿参数的大型模型通过多台机器上的许多 GPU 并行训练。即使是具有 80GB 显存(目前最大的之一)的单个 H100 GPU 也不足以训练仅有 300 亿参数的模型(即使批量大小为 1 且精度为 16 位)。
训练的内存消耗通常由
- 模型参数
- 层激活(前向传播)
- 梯度(反向传播)
- 优化器状态(例如,Adam 每个参数有两个额外的指数平均数)
- 模型输出和损失
组成。
当这些内存组件的总和超过单个 GPU 的显存时,常规的数据并行训练(DDP)就不能再使用了。为了缓解这一限制,我们需要引入模型并行性。一种有效的模型并行形式称为张量并行性(TP)。它将单个张量跨 GPU 分割,实现计算和内存的细粒度分布。它可以很好地扩展到大量 GPU,但每次操作后需要同步张量切片,这增加了通信开销。TP 对于具有许多线性层的模型(例如大语言模型)最为有效,在内存分布和计算效率之间提供了平衡。
在线性层中利用并行性¶
在张量并行性中,线性层的计算可以跨 GPU 分割。这可以节省内存,因为每个 GPU 只需要保存一部分权重矩阵。线性层可以有两种分割方式:按行分割或按列分割。
张量并行的核心概念¶
张量并行的基本思想是将模型中的张量在多个 GPU 之间进行分割,从而实现计算和内存的分布式处理。想象一下,一个巨大的权重矩阵,在张量并行的框架下,可以按照不同的维度被拆分到多个 GPU 上。例如,常见的有按列并行和按行并行两种方式。
按列并行¶
在按列并行中,权重矩阵沿着列维度被分割,每个 GPU 接收相同的输入数据,并对分配到的列进行矩阵乘法运算,最后将各个 GPU 的输出结果拼接起来,得到完整的输出。
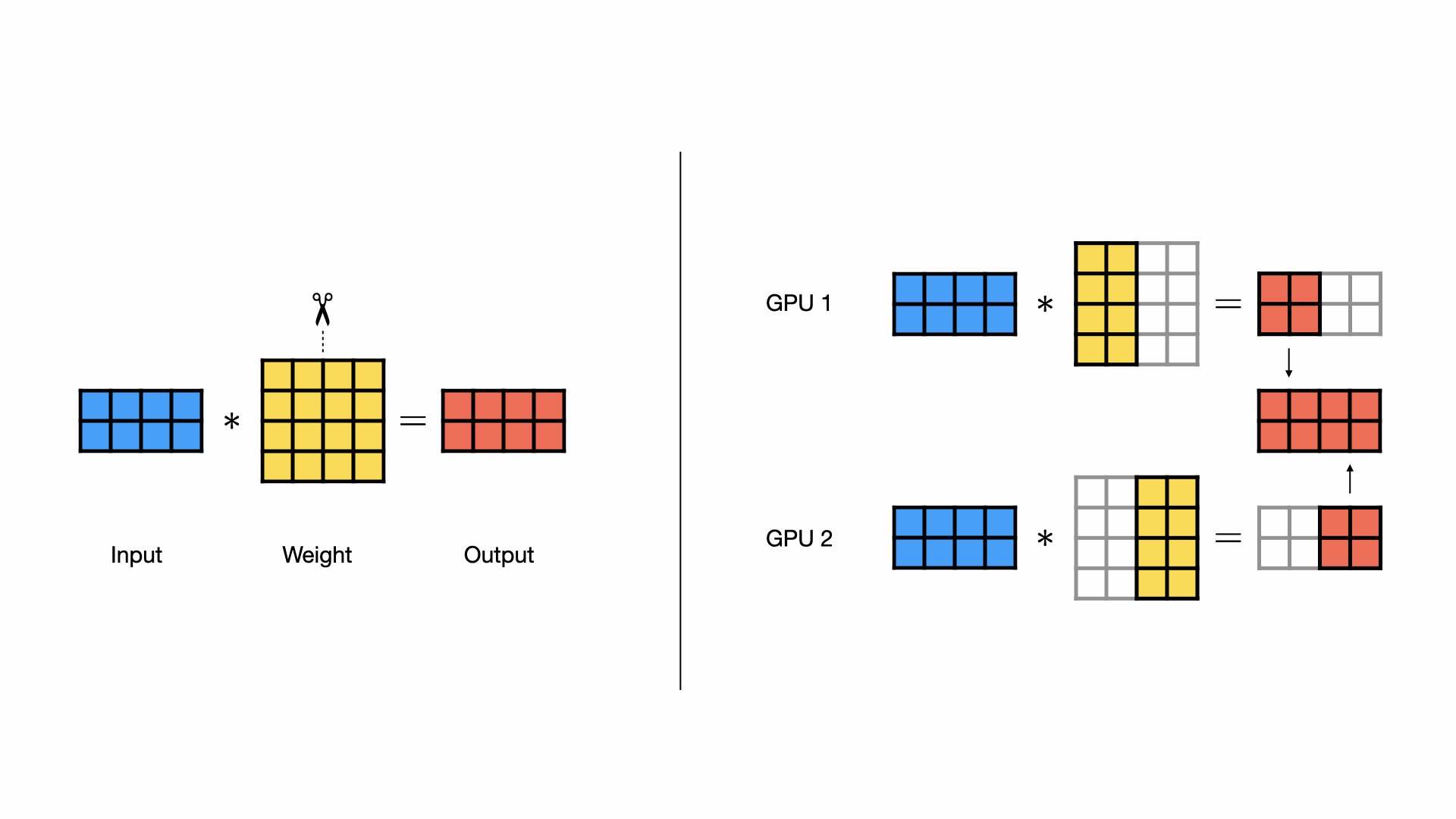
按行并行¶
而按行并行则是将权重矩阵的行均匀分配到不同的 GPU 上,同时输入数据也按照相同的方式进行分割,每个 GPU 进行计算后,再将输出进行元素求和,以获得最终结果。通过这种方式,模型的计算负载得以分散,内存压力也得到有效缓解。
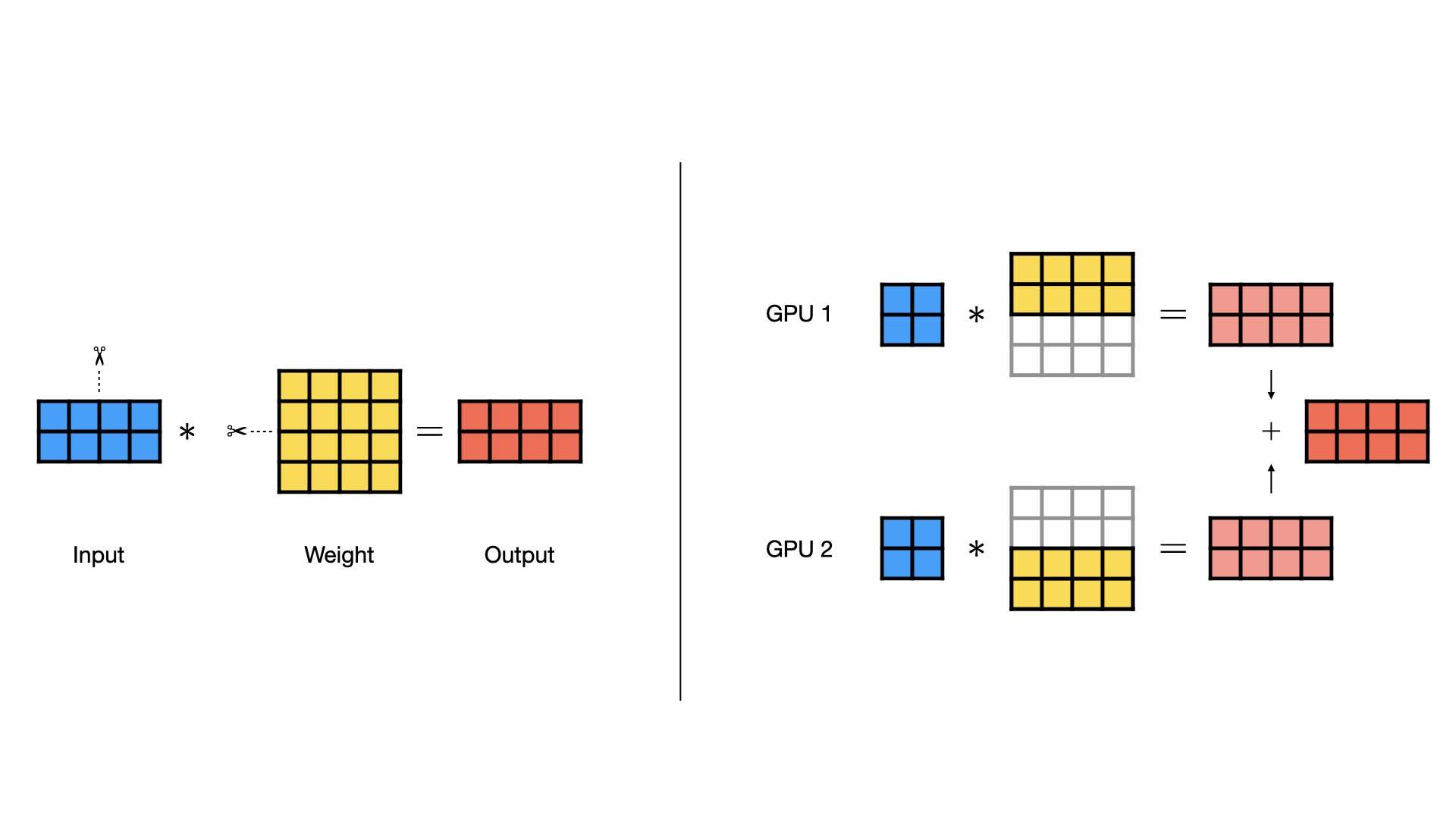
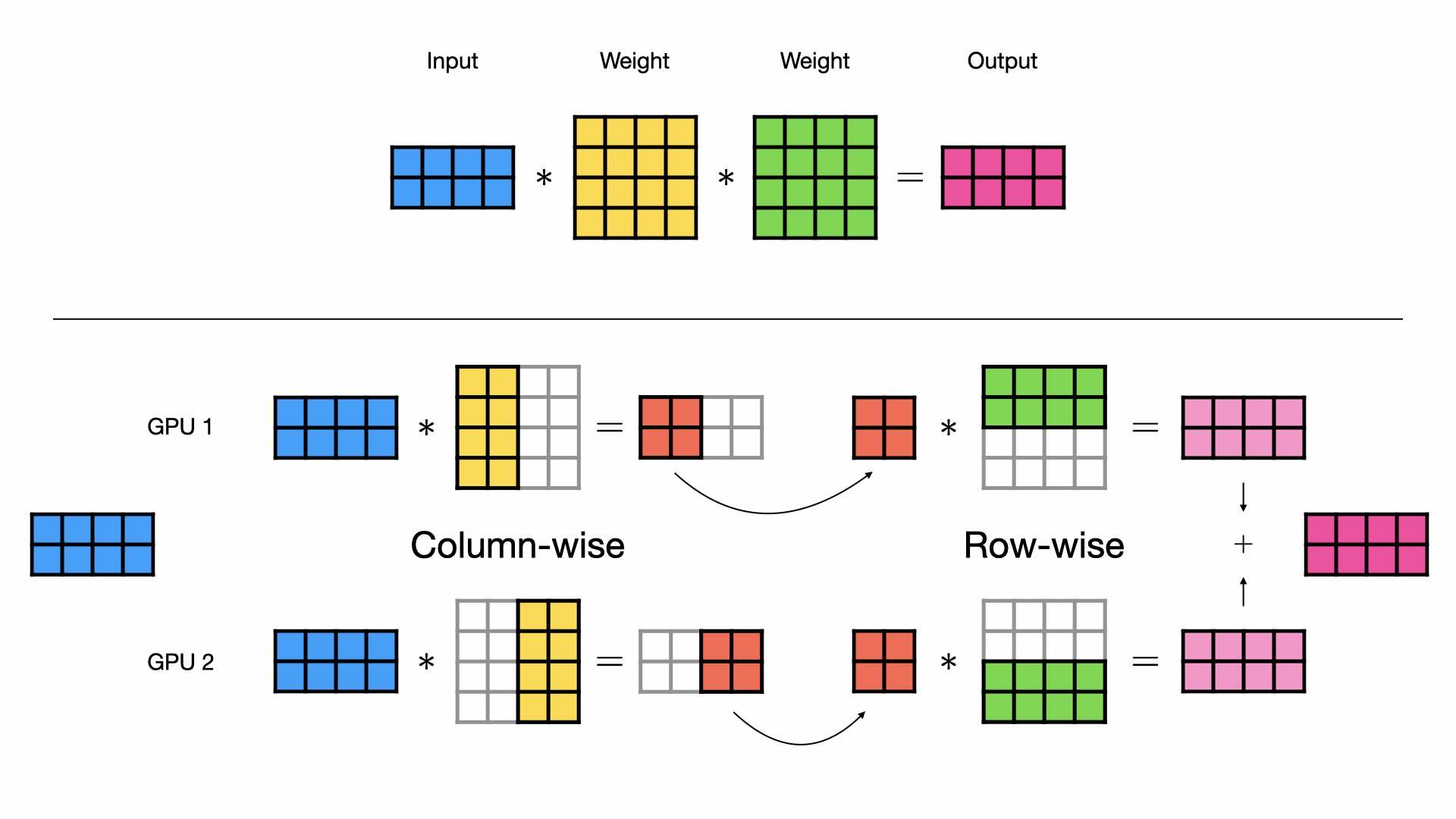
组合并行层¶
当有多个线性层依次排列时,例如在多层感知机(MLP)或Transformer中,列向和行向并行风格可以结合起来以达到最大效果。我们不将列向并行层的输出进行拼接,而是将输出分开,并直接将它们输入到行向并行层。这样,我们避免了在 GPU 之间进行昂贵的数据传输。
翻译自:tensor-parallelism-supercharging-large-model-training-with-pytorch-lightning