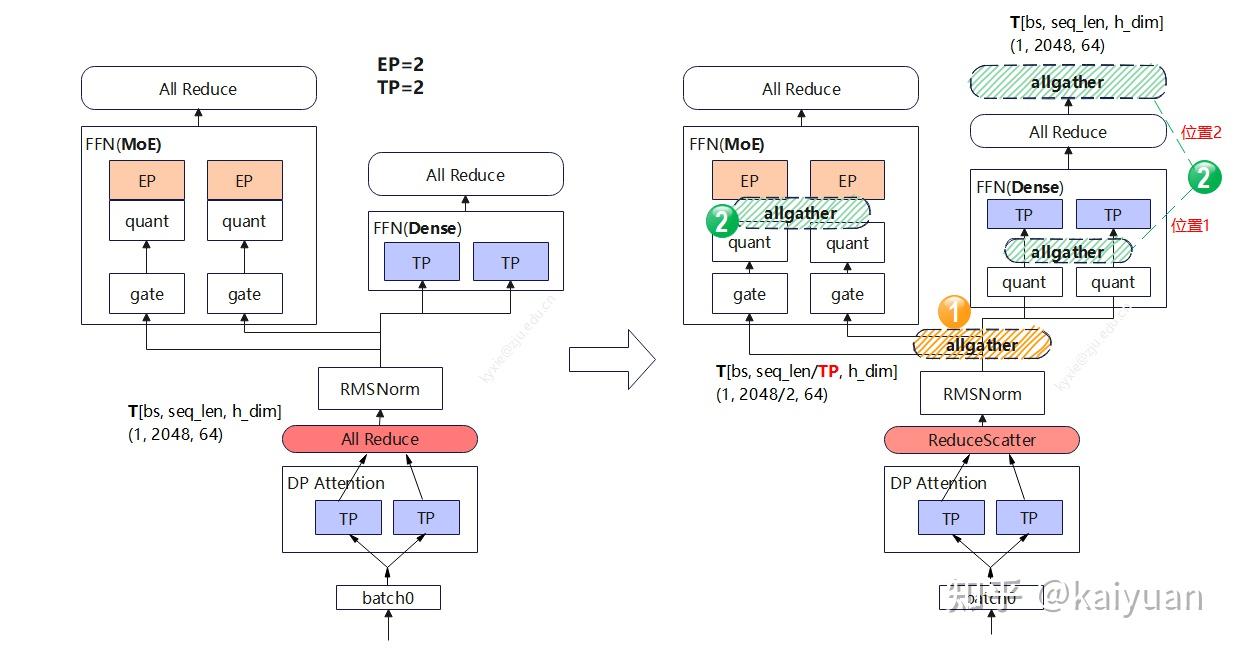
allreduce=reduce_scatter + allgather
"""
验证 PyTorch AllReduce = ReduceScatter + AllGather
AllReduce: 将所有进程的数据进行归约(如求和),然后将结果广播到所有进程
ReduceScatter: 先进行归约,然后将结果分散到各进程(每个进程得到结果的一部分)
AllGather: 将各进程的数据收集起来,每个进程都得到完整数据
数学等价性: AllReduce(X) = AllGather(ReduceScatter(X))
"""
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def run_allreduce_verification(rank: int, world_size: int):
"""在单个进程中运行验证"""
# 初始化进程组
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "29500"
dist.init_process_group(backend="nccl", rank=rank, world_size=world_size)
# 设置当前进程使用的 GPU
torch.cuda.set_device(rank)
device = torch.device(f"cuda:{rank}")
# 每个进程创建独特的输入数据
# 例如: rank0=[0,1,2,3], rank1=[4,5,6,7], rank2=[8,9,10,11], rank3=[12,13,14,15]
tensor_size = world_size * 4 # 确保能被 world_size 整除
input_data = torch.arange(
rank * tensor_size, (rank + 1) * tensor_size, dtype=torch.float32, device=device
)
print(f"[Rank {rank}] 原始数据: {input_data.tolist()}")
# ========== 方法1: 直接使用 AllReduce ==========
allreduce_result = input_data.clone()
dist.all_reduce(allreduce_result, op=dist.ReduceOp.SUM)
# ========== 方法2: ReduceScatter + AllGather ==========
# 准备 reduce_scatter 的输入: 需要一个 tensor 列表
chunk_size = tensor_size // world_size
input_chunks = list(input_data.clone().chunk(world_size))
# ReduceScatter: 归约后分散,每个进程得到结果的一部分
reduce_scatter_output = torch.zeros(chunk_size, dtype=torch.float32, device=device)
dist.reduce_scatter(reduce_scatter_output, input_chunks, op=dist.ReduceOp.SUM)
print(f"[Rank {rank}] ReduceScatter 后得到的分片: {reduce_scatter_output.tolist()}")
# AllGather: 收集所有分片,组成完整结果
allgather_output = [
torch.zeros(chunk_size, dtype=torch.float32, device=device) for _ in range(world_size)
]
dist.all_gather(allgather_output, reduce_scatter_output)
# 拼接成完整张量
combined_result = torch.cat(allgather_output)
# ========== 验证结果 ==========
print(f"[Rank {rank}] AllReduce 结果: {allreduce_result.tolist()}")
print(f"[Rank {rank}] ReduceScatter+AllGather 结果: {combined_result.tolist()}")
is_equal = torch.allclose(allreduce_result, combined_result)
print(f"[Rank {rank}] 两种方法结果是否相等: {is_equal}")
if rank == 0:
print("\n" + "=" * 60)
print("验证总结:")
print("=" * 60)
print(f"World Size: {world_size}")
print(f"每个进程的输入张量大小: {tensor_size}")
print(f"AllReduce = ReduceScatter + AllGather: {is_equal}")
print("=" * 60)
# 清理
dist.destroy_process_group()
def visualize_operations():
"""可视化展示操作过程(不需要分布式环境)"""
print("=" * 60)
print("AllReduce vs ReduceScatter + AllGather 原理图示")
print("=" * 60)
world_size = 4
# 模拟4个进程的数据
data = [
torch.tensor([1.0, 2.0, 3.0, 4.0]), # Rank 0
torch.tensor([5.0, 6.0, 7.0, 8.0]), # Rank 1
torch.tensor([9.0, 10.0, 11.0, 12.0]), # Rank 2
torch.tensor([13.0, 14.0, 15.0, 16.0]), # Rank 3
]
print("\n初始数据 (每个Rank的数据):")
for i, d in enumerate(data):
print(f" Rank {i}: {d.tolist()}")
# AllReduce: 所有元素对应位置求和
allreduce_result = sum(data)
print(f"\nAllReduce 结果 (所有Rank都得到相同结果):")
print(f" {allreduce_result.tolist()}")
# ReduceScatter: 先求和,然后分散
print("\n--- ReduceScatter + AllGather 拆解 ---")
print("\nStep 1: ReduceScatter (归约 + 分散)")
total = sum(data)
chunks = total.chunk(world_size)
for i, chunk in enumerate(chunks):
print(f" Rank {i} 得到分片: {chunk.tolist()}")
print("\nStep 2: AllGather (收集所有分片)")
gathered = torch.cat(list(chunks))
print(f" 每个Rank都得到完整结果: {gathered.tolist()}")
print("\n验证: AllReduce == ReduceScatter + AllGather")
print(f" 结果相等: {torch.allclose(allreduce_result, gathered)}")
print("=" * 60)
if __name__ == "__main__":
# 先展示原理
visualize_operations()
# 实际分布式验证
print("\n\n")
print("=" * 60)
print("实际分布式验证 (多进程)")
print("=" * 60)
world_size = 4 # 使用4个进程
mp.spawn(run_allreduce_verification, args=(world_size,), nprocs=world_size)
torchrun demo.py
============================================================
AllReduce vs ReduceScatter + AllGather 原理图示
============================================================
初始数据 (每个Rank的数据):
Rank 0: [1.0, 2.0, 3.0, 4.0]
Rank 1: [5.0, 6.0, 7.0, 8.0]
Rank 2: [9.0, 10.0, 11.0, 12.0]
Rank 3: [13.0, 14.0, 15.0, 16.0]
AllReduce 结果 (所有Rank都得到相同结果):
[28.0, 32.0, 36.0, 40.0]
--- ReduceScatter + AllGather 拆解 ---
Step 1: ReduceScatter (归约 + 分散)
Rank 0 得到分片: [28.0]
Rank 1 得到分片: [32.0]
Rank 2 得到分片: [36.0]
Rank 3 得到分片: [40.0]
Step 2: AllGather (收集所有分片)
每个Rank都得到完整结果: [28.0, 32.0, 36.0, 40.0]
验证: AllReduce == ReduceScatter + AllGather
结果相等: True
============================================================
============================================================
实际分布式验证 (多进程)
============================================================
[Rank 3] 原始数据: [48.0, 49.0, 50.0, 51.0, 52.0, 53.0, 54.0, 55.0, 56.0, 57.0, 58.0, 59.0, 60.0, 61.0, 62.0, 63.0]
[Rank 2] 原始数据: [32.0, 33.0, 34.0, 35.0, 36.0, 37.0, 38.0, 39.0, 40.0, 41.0, 42.0, 43.0, 44.0, 45.0, 46.0, 47.0]
[Rank 1] 原始数据: [16.0, 17.0, 18.0, 19.0, 20.0, 21.0, 22.0, 23.0, 24.0, 25.0, 26.0, 27.0, 28.0, 29.0, 30.0, 31.0]
[Rank 0] 原始数据: [0.0, 1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0, 11.0, 12.0, 13.0, 14.0, 15.0]
[Rank 2] ReduceScatter 后得到的分片: [128.0, 132.0, 136.0, 140.0]
[Rank 3] ReduceScatter 后得到的分片: [144.0, 148.0, 152.0, 156.0]
[Rank 0] ReduceScatter 后得到的分片: [96.0, 100.0, 104.0, 108.0]
[Rank 1] ReduceScatter 后得到的分片: [112.0, 116.0, 120.0, 124.0]
[Rank 1] AllReduce 结果: [96.0, 100.0, 104.0, 108.0, 112.0, 116.0, 120.0, 124.0, 128.0, 132.0, 136.0, 140.0, 144.0, 148.0, 152.0, 156.0]
[Rank 2] AllReduce 结果: [96.0, 100.0, 104.0, 108.0, 112.0, 116.0, 120.0, 124.0, 128.0, 132.0, 136.0, 140.0, 144.0, 148.0, 152.0, 156.0]
[Rank 0] AllReduce 结果: [96.0, 100.0, 104.0, 108.0, 112.0, 116.0, 120.0, 124.0, 128.0, 132.0, 136.0, 140.0, 144.0, 148.0, 152.0, 156.0]
[Rank 1] ReduceScatter+AllGather 结果: [96.0, 100.0, 104.0, 108.0, 112.0, 116.0, 120.0, 124.0, 128.0, 132.0, 136.0, 140.0, 144.0, 148.0, 152.0, 156.0]
[Rank 3] AllReduce 结果: [96.0, 100.0, 104.0, 108.0, 112.0, 116.0, 120.0, 124.0, 128.0, 132.0, 136.0, 140.0, 144.0, 148.0, 152.0, 156.0]
[Rank 2] ReduceScatter+AllGather 结果: [96.0, 100.0, 104.0, 108.0, 112.0, 116.0, 120.0, 124.0, 128.0, 132.0, 136.0, 140.0, 144.0, 148.0, 152.0, 156.0]
[Rank 0] ReduceScatter+AllGather 结果: [96.0, 100.0, 104.0, 108.0, 112.0, 116.0, 120.0, 124.0, 128.0, 132.0, 136.0, 140.0, 144.0, 148.0, 152.0, 156.0]
[Rank 3] ReduceScatter+AllGather 结果: [96.0, 100.0, 104.0, 108.0, 112.0, 116.0, 120.0, 124.0, 128.0, 132.0, 136.0, 140.0, 144.0, 148.0, 152.0, 156.0]
[Rank 0] 两种方法结果是否相等: True
============================================================
验证总结:
============================================================
World Size: 4
每个进程的输入张量大小: 16
AllReduce = ReduceScatter + AllGather: True
============================================================
[Rank 1] 两种方法结果是否相等: True
[Rank 2] 两种方法结果是否相等: True
[Rank 3] 两种方法结果是否相等: True
将 AllReduce 拆分为 ReduceScatter + AllGather 有以下几个主要好处:
1. 计算与通信重叠(Overlap)
AllReduce 方式:
[-------- AllReduce --------][-- 计算 --]
拆分方式:
[-- ReduceScatter --][-- AllGather --]
[---- 计算 ----] ← 可以提前开始!
ReduceScatter 完成后,每个进程已经拥有归约结果的一部分,可以立即开始计算(如梯度更新),与 AllGather 并行进行。
2. 内存优化(ZeRO 的核心思想)
| 阶段 | 每个进程持有的数据量 |
|---|---|
| ReduceScatter 后 | 1/N(只保留本地分片) |
| 更新参数 | 只更新 1/N 的参数 |
| AllGather 后 | 完整参数 |
这是 DeepSpeed ZeRO Stage 2/3 的核心原理:
- 优化器状态只需维护 1/N
- 梯度只需存储 1/N
- 显著降低显存占用
3. 带宽利用更灵活
虽然总通信量相同(都是 2*(N-1)/N * data_size),但拆分后:
- 可以在不同阶段使用不同的通信策略
- 更容易与其他并行策略(TP/PP)融合
- 支持更细粒度的流水线调度
4. 实际应用场景
典型的大模型训练流程:
1. Forward → 2. Backward → 3. ReduceScatter(梯度)
↓
4. 优化器更新(只更新1/N)
↓
5. AllGather(参数)
这种模式被广泛用于 DeepSpeed、FSDP、Megatron-LM 等分布式训练框架中。
总结
| 优势 | 说明 |
|---|---|
| 延迟隐藏 | 计算可以与 AllGather 重叠 |
| 内存节省 | ��每个进程只存储 1/N 的优化器状态 |
| 可扩展性 | 支持更大模型、更多 GPU |
| 灵活调度 | 便于与其他并行策略组合 |
这就是为什么现代大模型训练框架普遍采用这种拆分策略的原因。