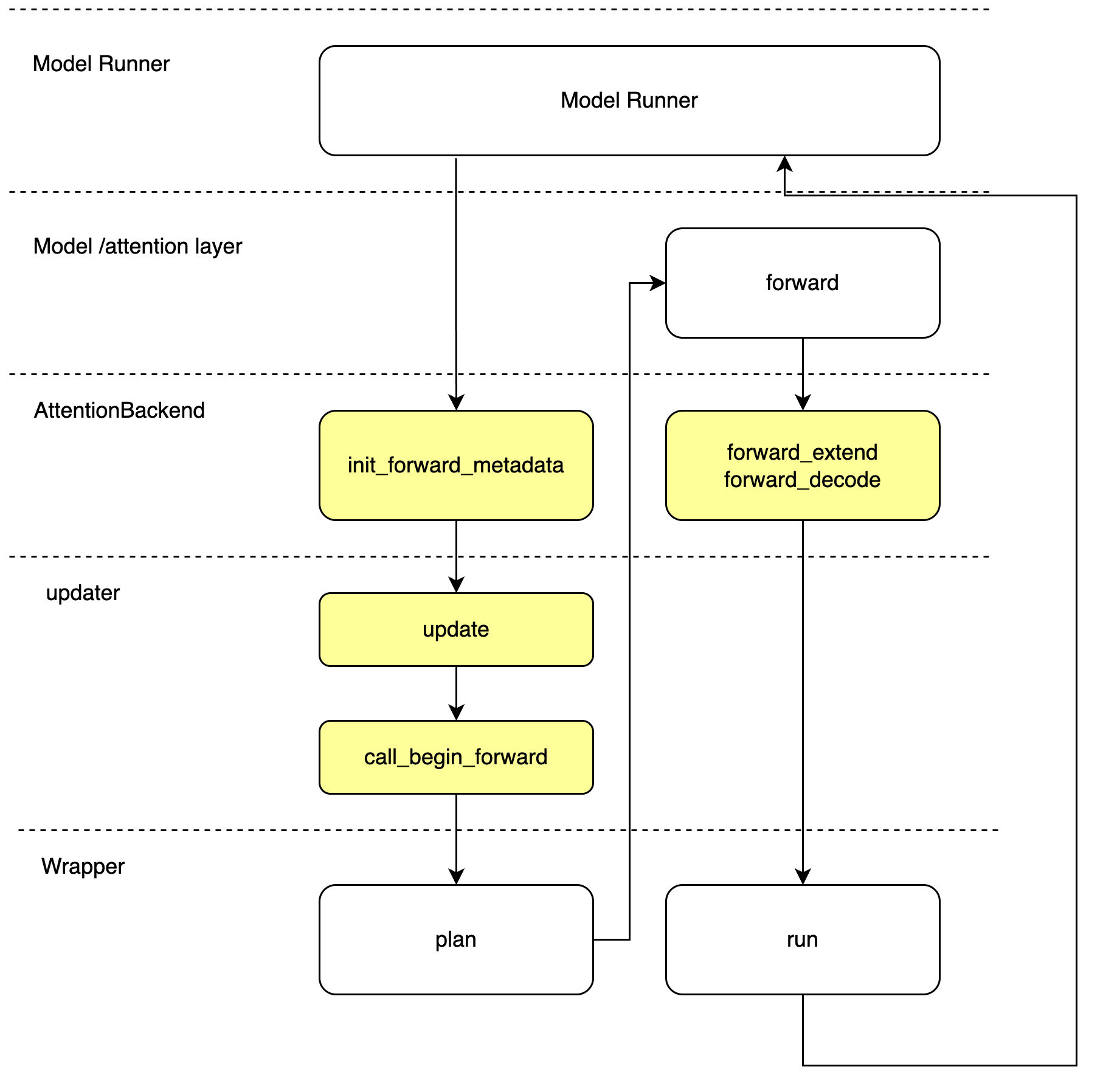
AttentionBackend
sglang-flashinfer-mla-backend
| 阶段 | 主要文件 | 关键实现 |
|---|---|---|
| 启动 | srt/server_args.py | page_size CLI 参数,默认为 1;设为 64 后在全程传递 |
| 页对齐分配 | srt/mem_cache/allocator.py → PagedTokenToKVPoolAllocator | 构造函数 记录 page_size; alloc() 用 page * 64 + offset 生成整页连续索引;alloc_extend() / alloc_decode() 中的 Triton 核心 alloc_extend_kernel / alloc_decode_kernel 负责一次性给一批 request 分页;释放时通过 idx // 64 回收整页; |
| KV Buffer | srt/mem_cache/memory_pool.py | 当 page_size>1 时自动用 PagedTokenToKVPoolAllocator;所有 layer 的 k_buffer / v_buffer 都扩一整页,保证写入时不越界 |
| 页表拼装 | srt/managers/scheduler.py::_build_kv_mapping | page_id = token // 64、offset = token % 64;生成 GPU 端 kv_indices / kv_indptr |
| Attention 后端 | srt/layers/attention/flashinfer_mla_backend.py | init_forward_metadata() 把页表放进 forward_batch.spec_info,然后调用 FlashInfer mla_prefill_paged_plan/mla_decode_paged_plan;不再在 Python 侧 assert 64,由 FlashInfer 内核检查 |
| GPU Kernel | FlashInfer (flashinfer.ai repo) | mla_*_paged 内核硬编码只支持 page_size == 64;如果 CLI 给了别的值会在 plan 阶段抛 flashinfer::CheckPageSize |
SGLang �支持多个 Attention Backends,这些 backends 加速模型的 forward pass 和 key-value cache reuse。以 FlashMLABackend 为例:
# model_runner.py初始化 attn_backend
def init_attention_backend(self):
"""Init attention kernel backend."""
if self.server_args.enable_two_batch_overlap and not self.is_draft_worker:
# 若启用了双 batch 重叠执行(TBO),使用专用的 TboAttnBackend 包装
self.attn_backend = TboAttnBackend.init_new(self._get_attention_backend)
else:
# 否则直接使用普通 attention backend
self.attn_backend = self._get_attention_backend()
表8 支持的 attention backend 类型表
| 配置值 | 后端类 | 特点 |
|---|---|---|
| "flashinfer" | FlashInferAttnBackend or FlashInferMLAAttnBackend | 高速解码,支持 EAGLE 预取流 |
| "aiter" | AiterAttnBackend | 支持异步 Attention,主要用于异构并行 |
| "ascend" | AscendAttnBackend | 华为昇腾芯片专用 |
| "triton" | TritonAttnBackend / DoubleSparseAttnBackend | 高性能内核支持稀疏模式 |
| "torch_native" | TorchNativeAttnBackend | 使用 PyTorch 自带 Attention |
| "flashmla" | FlashMLABackend | 自研 MLA 后端,支持 expert routing 与 fine-tuning |
| "fa3" | FlashAttentionBackend | FlashAttention v3,要求 SM=80/90 |
| "cutlass_mla" | CutlassMLABackend | 使用 Cutlass 实现的 MLA 模块 |
| "intel_amx" | IntelAMXAttnBackend | Intel AMX 向量指令优化(Sapphire Rapids) |
def __init__(
self,
model_runner: ModelRunner, # 模型执行器,封装了模型及其配置
skip_prefill: bool = False, # 是否跳过预填充阶段(decode-only模式)
kv_indptr_buf: Optional[torch.Tensor] = None, # KV缓存索引指针缓冲区(解码时使用)
kv_last_page_len_buf: Optional[torch.Tensor] = None, # KV缓存最后一页的长度(处理分页对齐)
):
super().__init__( # 调用父类 FlashInferMLAAttnBackend 的构造函数
model_runner, skip_prefill, kv_indptr_buf, kv_last_page_len_buf
)
...
# 成员变量初始化
init_forward_metadata()函数
根据 ForwardBatch ��中的推理模式(decode / idle / verify),动态生成:
- block 级的 KV 缓存索引
- MLA tile 调度元数据
- 每个请求分裂为的 tile 数量
这些信息存入 self.forward_metadata: FlashMLADecodeMetadata,供后续推理过程如 forward_decode() 或 forward_extend() 调用。
def init_forward_metadata(self, forward_batch: ForwardBatch):
bs = forward_batch.batch_size # 获取当前 batch 的大小
# ========= 分支1:普通推理模式(包括 decode / idle)=========
if forward_batch.forward_mode.is_decode_or_idle():
# 获取当前 batch 中最大序列长度,并向上对齐到 PAGE_SIZE(64)单位
max_seqlen_pad = triton.cdiv(
forward_batch.seq_lens_cpu.max().item(), PAGE_SIZE
)
# 创建 block_kv_indices:用于标识每个 token 在 KV cache 中的块级索引(初始设为 -1)
block_kv_indices = torch.full(
(bs, max_seqlen_pad), # shape: [batch_size, padded_blocks]
-1, # 默认未占用的 block 为 -1
dtype=torch.int32,
device=forward_batch.seq_lens.device,
)
# 调用 Triton kernel:根据请求索引和序列长度映射每个 token 到对应 KV cache 的 block 索引
create_flashmla_kv_indices_triton[(bs,)](
self.req_to_token, # 请求 → token 索引映射表
forward_batch.req_pool_indices, # 请求池索引(对应 batch 中每个样本)
forward_batch.seq_lens, # 每个样本的实际长度
None, # 暂不使用可选参数(如 offsets)
block_kv_indices, # 输出索引结果
self.req_to_token.stride(0), # 索引访问步长
max_seqlen_pad, # KV 缓存块数(对齐后)
)
# 获取 FlashMLA 的 tile 调度元信息和每个请求的 tile 分裂数
mla_metadata, num_splits = get_mla_metadata(
forward_batch.seq_lens.to(torch.int32), # 将序列长度转换为 int32 类型
self.num_q_heads, # 本地注意力头数
1, # num_kv_heads:一般为1(标准注意力)
)
# 保存为 FlashMLADecodeMetadata 对象,供后续推理使用
self.forward_metadata = FlashMLADecodeMetadata(
mla_metadata, # tile 调度信息(Triton kernel使用)
num_splits, # 每个样本被拆分成多少 tile
block_kv_indices, # KV 索引映射(token → block)
)
# ========= 分支2:草稿 token 校验模式(Speculative Decoding)=========
elif forward_batch.forward_mode.is_target_verify():
# 为了校验草稿 token,需要在序列长度上追加草稿长度
seq_lens_cpu = forward_batch.seq_lens_cpu + self.num_draft_tokens
seq_lens = forward_batch.seq_lens + self.num_draft_tokens
# 同样对草稿 token 的总序列长度进行对齐
max_seqlen_pad = triton.cdiv(seq_lens_cpu.max().item(), PAGE_SIZE)
# 分配 block_kv_indices(结构同 decode 模式)
block_kv_indices = torch.full(
(bs, max_seqlen_pad),
-1,
dtype=torch.int32,
device=seq_lens.device,
)
# 调用 Triton kernel 构建 KV 索引(包含草稿 token)
create_flashmla_kv_indices_triton[(bs,)](
self.req_to_token,
forward_batch.req_pool_indices,
seq_lens, # 注意这里使用加上草稿后的序列长度
None,
block_kv_indices,
self.req_to_token.stride(0),
max_seqlen_pad,
)
# 生成 MLA tile 调度元数据,但注意头数需要乘以草稿 token 数
mla_metadata, num_splits = get_mla_metadata(
seq_lens.to(torch.int32),
self.num_draft_tokens * self.num_q_heads, # 用于支持多个草稿 token 并行校验
1,
)
# 注意仍然使用 FlashMLADecodeMetadata,保证后续接口统一
self.forward_metadata = FlashMLADecodeMetadata(
mla_metadata,
num_splits,
block_kv_indices,
)
# ========= 分支3:其他前向模式 =========
else:
# 对于非 decode/verify 模式(例如 extend-only),调用父类默认实现
super().init_forward_metadata(forward_batch)
- 模型通过 AttentionBackend 加速生成 logits,返回给 ModelRunner,进而返回给 TpModelWorker。
- TpModelWorker 从 ModelRunner 接收 logits_output,调用 ModelRunner 的 sample 方法生成 next_token_ids,并将其发送回 Scheduler。
SGLang真正的数据存储在二级的 token_to_kv_pool 中,而一级的 req_to_token_pool 则标记了每个 token 的 idx。也就是说,req_to_token_pool 就是FlashMLA需要的 block_table,而 block size 正好是一个token的大小。所以需要 SGLang 的 Pagesize > 1 或者 FlashMLA 支持 Pagesize = 1 的计算。
页表构建
wrapper_paged.plan(...) 并不是 SGLang 自己实现的函数,而是 FlashInfer 的 Python 包(C++/CUDA 扩展)里提供的 MLA 批量 PagedAttention 包装器方法。
SGLang 只是把准备好的 kv_indptr / kv_indices / kv_len_arr和模型维度参数交给这个包装器;真正的“计划(plan)阶段”调度与元数据构建发生在 FlashInfer 里。
kv_indptr 和 kv_indices
Paged Attention 不直接存 token→显存地址 的映射,而是:
- 把 KV 缓存按固定大小的页(page_size,比如 64 token/页)存放;
- 每个序列可能分布在多个页里(页可能不连续,因为显存是复用的);
- 我们只需要告诉内核:
- 每个序列用到了哪些页(kv_indices)
- 每个序列的页起止位置(kv_indptr)
- 避免存每个 token 的绝对位置(节省内存);
- 页复用时,更新索引比复制数据快。
-
KV index ptr(索引指针) 作用:存储前缀和,标记每个序列在 kv_indices 数组里的起始位置。 形状:[batch_size + 1](长度比批次多 1) 类型:int32
-
KV indices(索引列表) 作用:按顺序存储每个序列实际使用的页ID(页号)。 形状:[sum(paged_kernel_lens)](所有序列的页数总和) 类型:int32
kv_indices = [5, 6, 8, 2, 3, 10, 11, 15, 18]
kv_indptr = [0, 3, 5, 9]
* 序列0 用页 5, 6, 8
* 序列1 用页 2, 3
* 序列2 用页 10, 11, 15, 18
与 PAGE_SIZE=64 的关系 kv_indices 里的每个页ID = 一段连续的 page_size token(例如 64 token); 内核计算实际地址时会做:
base_addr = page_id * page_size
token_addr = base_addr + offset_in_page
kv_indptr 不依赖 page_size,它只是页级索引的分界表。
PA64
--page-size 64 ➡️ ServerArgs ➡️ ModelRunner
- --page-size 从 ServerArgs 进入后端(ServerArgs.page_size = 64),并贯穿 memory pool / scheduler / running time;
- 要走 MLA paged 内核,还需 --attention-backend flashinfer --enable-flashinfer-mla。
例子
假设对于 3 个样本,有如下数据:
# 请求索引:每个 sample 对应的请求索引
req_pool_indices = torch.tensor([0, 1, 2]) # torch.tensor:创建一个 1 维的 PyTorch 张量
# 序列长度(seq_lens)表示整个序列需要的 token 数(包括全局缓存的部分与新计算的部分)
seq_lens = torch.tensor([8, 10, 7])
# 前缀长度(prefix_lens)表示每个 sample 缓存中已有的 token 数(cache 命中部分)
prefix_lens = torch.tensor([5, 5, 5])
那么,新生成的 token 数分别为:
样本 0:8 - 5 = 3 个 token
样本 1:10 - 5 = 5 个 token
样本 2:7 - 5 = 2 个 token
在 paged 模式下,更新器在 update() 函数中会将:
paged_kernel_lens = seq_lens
paged_kernel_lens_sum = seq_lens.sum().item() # 8+10+7 = 25
计算 KV 指针(kv_indptr)
bs = len(req_pool_indices) # bs = 3
# 使用 seq_lens 做累加
kv_indptr[1 : bs + 1] = torch.cumsum(paged_kernel_lens, dim=0)
kv_indptr = kv_indptr[: bs + 1]
得到:
kv_indptr[0] = 0
# paged_kernel_lens = [8, 10, 7]
# kv_indptr[1 : bs + 1] = torch.cumsum(paged_kernel_lens, dim=0)
kv_indptr[1] = 8
kv_indptr[2] = 8 + 10 = 18
kv_indptr[3] = 8 + 10 + 7 = 25
即:
kv_indptr = [0, 8, 18, 25]
这表示新生成的 token 在全局 KV 缓存中的理论“位置”范围。但实际全局 KV 缓存中,已存在的缓存(cache 命中部分)往往已经提前存放,比如每个样本可能已经有前 5 个 token,最终全局 KV 的完整索引会通过拼接“旧 token + 新 token”来确定。例如:
样本 0:全局 KV 位置范围为 [0, 5](�旧缓存) 和 [5,8](新生成)
样本 1:旧缓存 [0,5],新 token [5,10]
样本 2:旧缓存 [0,5],新 token [5,7]
生成 KV 索引(kv_indices)
# 张量分配 kv_indices:长度 = 各样本页数之和(稀疏/分段拼接的一维索引)
kv_indices = torch.empty(
paged_kernel_lens_sum, # 25
dtype=torch.int32,
device=req_pool_indices.device,
)
create_flashinfer_kv_indices_triton[(bs,)](
self.req_to_token, # 全局 token 映射表
req_pool_indices, # [0, 1, 2]
paged_kernel_lens, # [8, 10, 7]
kv_indptr, # [0, 8, 18, 25]
None,
kv_indices,
self.req_to_token.shape[1],# token 池宽度(例如总 token 数)
)
该 kernel 根据 req_to_token 的映射将新生成 token 的实际全局存储位置写入到 kv_indices 中,确保新 token 会被追加在全局缓存后面。 例如,假设全局缓存中每个 sample 已存放 5 个 token,那么新 token 的映射索引可能为:
样本 0:新 token 对应索引 [5, 6, 7]
样本 1:新 token对应索引 [5, 6, 7, 8, 9]
样本 2:新 token对应索引 [5, 6]
# 获得
kv_indices = [2, 6, 2, 1, 3, 0, 0, 0,
1, 5, 4, 1, 5, 0, 0, 0, 0, 0,
5, 1, 5, 4, 1, 0, 0]
实际映射取决于全局布局,但逻辑上是把新 token 接在旧 token 后面。
计算 Query/Output 指针(qo_indptr)
qo_indptr[1 : bs + 1] = torch.cumsum(seq_lens - prefix_lens, dim=0)
qo_indptr = qo_indptr[: bs + 1]
seq_lens - prefix_lens = [8-5, 10-5, 7-5] = [3, 5, 2]
qo_indptr[0] = 0
qo_indptr[1] = 3
qo_indptr[2] = 3 + 5 = 8
qo_indptr[3] = 3 + 5 + 2 = 10
得到:
qo_indptr = [0, 3, 8, 10]
调用 Wrapper 规划 Attention
对于 paged 模式,计算每个 sample 新 token 数,用于构造“页”长度:
# kv_len_arr = kv_indptr[1:] - kv_indptr[:-1]
# paged_kernel_lens = [8, 10, 7]
kv_lens = paged_kernel_lens.to(torch.int32) # [8, 10, 7],代表每个 sample kv 的数量
wrapper.plan(
qo_indptr, # [0, 3, 8, 10]
kv_indptr, # [0, 8, 18, 25]
kv_indices, # 新 token 的映射索引
kv_lens, # [8, 10, 7]
self.num_local_heads,
self.kv_lora_rank,
self.qk_rope_head_dim,
1, # page_size 固定为 1
True, # causal 标志(prefill 阶段一般为 True)
sm_scale, # 缩放因子,例如:0.125
self.q_data_type,
self.data_type,
)
在底层,wrapper.plan() 会利用传入的指针和索引信息,将已有的全局 KV 缓存(前缀部分)和本次新生成 token 拼接起来,构造完整的 Key/Value 信息供后续 attention 计算。