��推理全流程
启动流程
v0.4.9
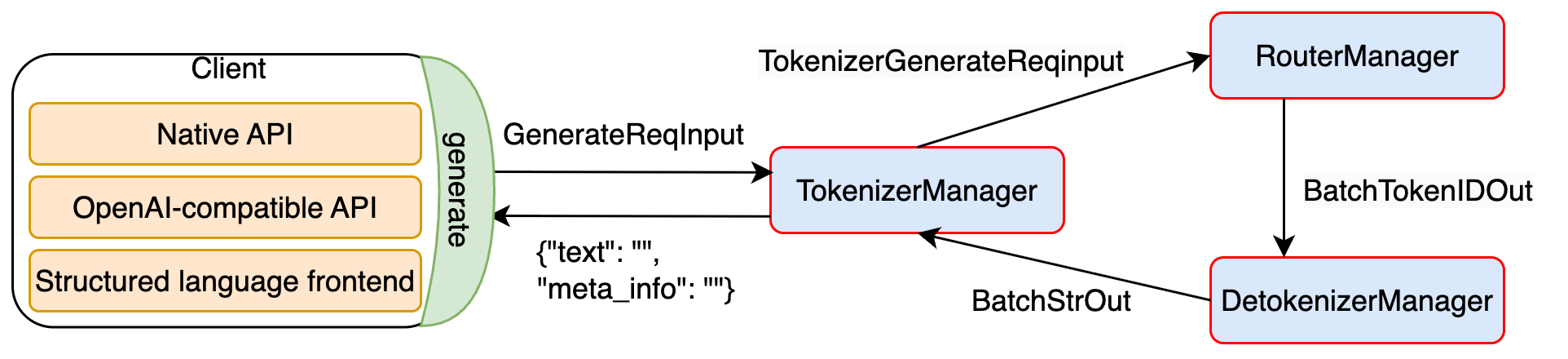
3个核心组件流转信息的数据结构在 io_struct.py 中,包括 GenerateReqInput / TokenizedGenerateReqInput / BatchTokenIDOut / BatchStrOut
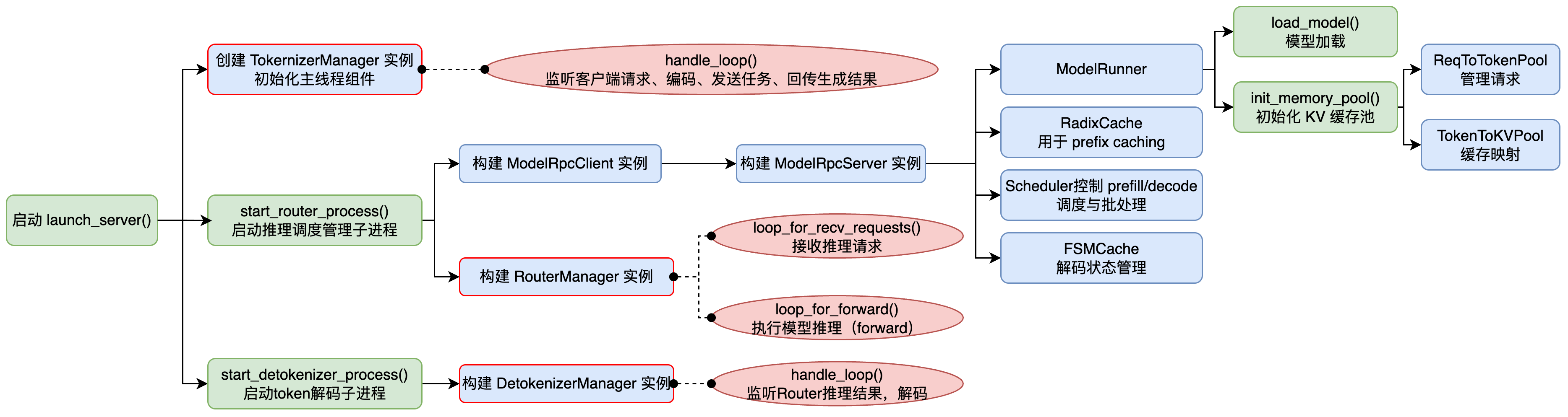
用户启动 Server ,初始化 FastAPI App、TokenizerManager、DetokenizerManager 和 Scheduler,每个组件运行各自的无限事件循环(infinite event loop)
def launch_server(server_args: ServerArgs, ...):
# 初始化三个核心模块(TokenizerManager / Scheduler / DetokenizerManager)
tokenizer_manager, template_manager, scheduler_info = _launch_subprocesses(...)
# python/sglang/srt/entrypoints/engine.py
# 核心功能:在主进程中创建 TokenizerManager,在子进程中启动 Scheduler 和 DetokenizerManager,完成多进程推理系统的初始化与通信架构搭建。
# 设置全局状态,供 FastAPI 接口访问
set_global_state(_GlobalState(...))
# 中间件添加:API key验证、Prometheus 监控、函数耗时分析
if server_args.api_key:
add_api_key_middleware(app, server_args.api_key)
if server_args.enable_metrics:
add_prometheus_middleware(app)
enable_func_timer()
# 如有 image token,做初始解码准备
...
# 创建并注册 warmup 线程,用于启动完成后的 warmup 推理
warmup_thread = threading.Thread(target=_wait_and_warmup, ...)
app.warmup_thread = warmup_thread # 挂载到 FastAPI 对象中,生命周期内执行 & app中是创建了 lifespan
try:
# 启动 FastAPI HTTP 服务,监听接口
uvicorn.run(app, host=server_args.host, port=server_args.port, ...)
finally:
warmup_thread.join() # 等待 warmup 线程结束
启动 Scheduler 子进程(核心推理进程)
根据 server_args 参数配置,在主进程中以多进程方式启动 推理调度子进程 Scheduler,支持两种模式:
- dp_size == 1:不使用数据并行,直接在当前节点内部启动多个 Scheduler 子进程(每个用于一组 pp/tp 组合)
- dp_size > 1:使用数据并行,启动一个 DataParallelController 管理多节点/多卡推理
if dp_size == 1:
for pp_rank in pp_rank_range:
for tp_rank in tp_rank_range:
-> 启动一个 run_scheduler_process 子进程
else:
-> 启动一个 run_data_parallel_controller_process 进程
# 若为多节点数据并行,启动一个控制进程
reader, writer = mp.Pipe(duplex=False) # 使用 Python 的 multiprocessing 模块建立一个单向通信管道(duplex=False,表示只能单向传输)
scheduler_pipe_readers = [reader] # 将管道的 reader 保存下来,以便后续主进程接收子进程发回的消息或状态更新
# 使用 multiprocessing.Process 启动一个新进程
proc = mp.Process(
target=run_data_parallel_controller_process,
args=(server_args, port_args, writer),
)
proc.start() # 启动该子进程
scheduler_procs.append(proc) # 将该进程对象加入 scheduler_procs 列表中
非主节点(node_rank ≥ 1)逻辑分支处理
在多机部署中,每台机器都会被赋予一个 node_rank:
- node_rank == 0: 主节点(通常负责 Tokenizer、Detokenizer 和调度)。
- node_rank >= 1: 从节点(只负责模型推理,不负责 Tokenizer/Detokenizer)。
因此,该段代码的逻辑只在 非主节点(从节点) 上执行。 非主节点 不再创建 tokenizer / detokenizer,仅启动 scheduler 参与推理
if server_args.node_rank >= 1:
for reader in scheduler_pipe_readers:
data = reader.recv()
assert data["status"] == "ready"
TokenizerManager
generate_request()函数生成请求
调用 TokenizerManager 的 generate_request() 方法:
- 会对请求进行 tokenization;
- 并以 Python 对象(pyobj)形式将其转发给 Scheduler;
- 同时调用 TokenizerManager 的 _wait_one_response 方法。
async def generate_request(
self,
obj: Union[GenerateReqInput, EmbeddingReqInput],
request: Optional[fastapi.Request] = None,
):
......
# 模型读锁:确保不与“模型更新”冲突
async with self.model_update_lock.reader_lock:
# 单请求流程(常见于 Chat 或 Completion)
if obj.is_single:
tokenized_obj = await self._tokenize_one_request(obj) # 对请求进行 tokenization:将文本或 prompt 转为 token ids
state = self._send_one_request(obj, tokenized_obj, created_time) # 构造请求体并通过 ZMQ 发送给 Scheduler
async for response in self._wait_one_response(obj, state, request): # 监听 Detokenizer 子进程返回结果,异步 yield 每个 token
yield response
# 批请求流程(支持多个输入并行推理)
else:
# 一样的 展开批量做这些处理而已:
# _handle_batch_request 内部将会循环调用多个 _send_one_request() 和 _wait_one_response(),支持并发 batch 请求
async for response in self._handle_batch_request(
obj, request, created_time
):
yield response
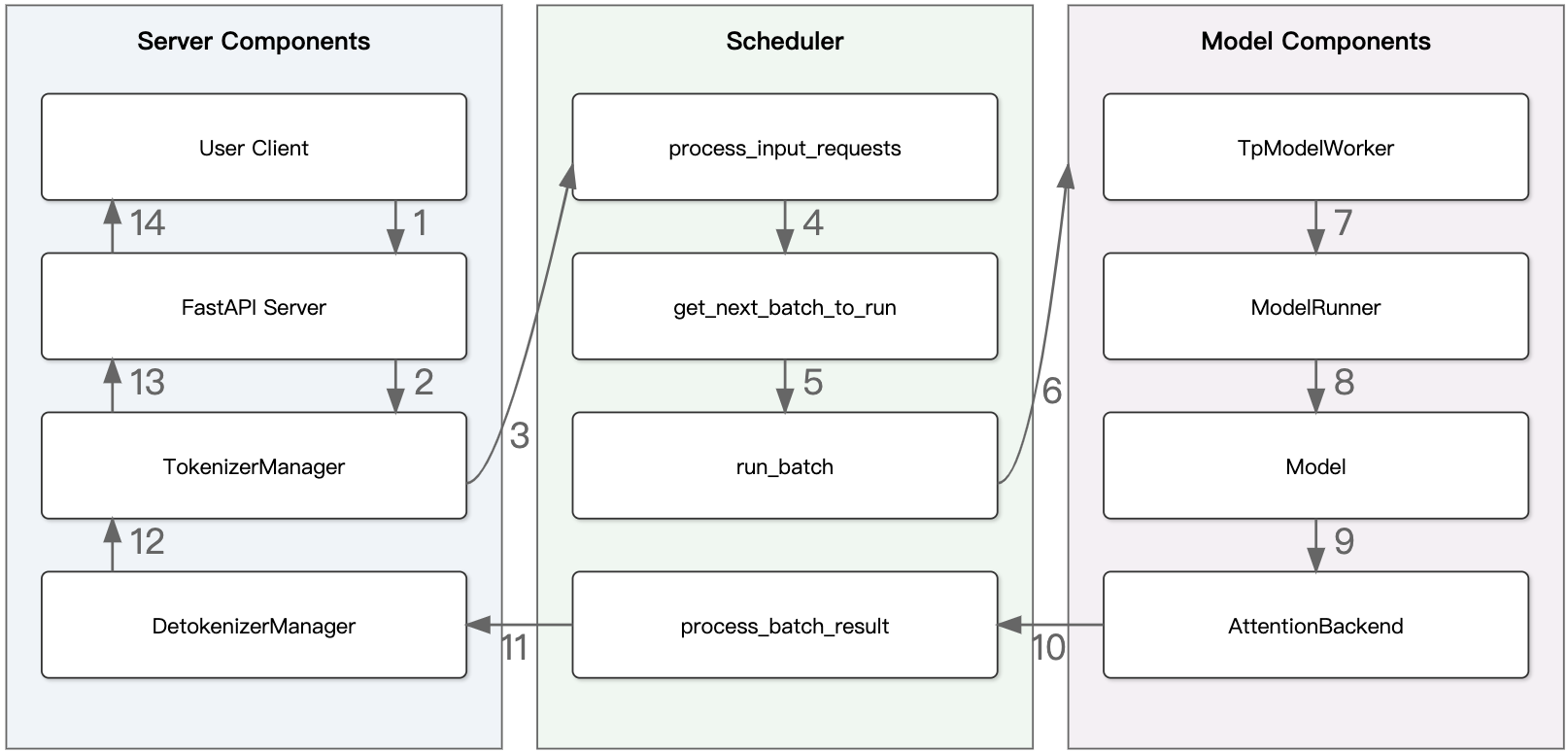
将由 Scheduler 在事件循环 event_loop_normal 中处理请求.
Scheduler 调度
# 启动 scheduler 子进程
def run_scheduler_process(
server_args: ServerArgs,
port_args: PortArgs,
gpu_id: int,
tp_rank: int,
pp_rank: int,
dp_rank: Optional[int],
pipe_writer,
):
# 【略】初始化 prefix / proctitle / logger / fault handler
......
# 创建 Scheduler 实例并通知主进程
try:
scheduler = Scheduler(server_args, port_args, gpu_id, tp_rank, pp_rank, dp_rank)
pipe_writer.send(
{
"status": "ready",
"max_total_num_tokens": scheduler.max_total_num_tokens,
"max_req_input_len": scheduler.max_req_input_len,
}
)
# 根据模式启动 event_loop
disaggregation_mode: DisaggregationMode = scheduler.disaggregation_mode
if disaggregation_mode == DisaggregationMode.NULL:
if server_args.pp_size > 1:
scheduler.event_loop_pp() # pipeline-parallel 模式
elif scheduler.enable_overlap:
scheduler.event_loop_overlap() # 推理阶段重叠(Overlapping)
else:
scheduler.event_loop_normal() # 标准单线程顺序推理
elif disaggregation_mode == DisaggregationMode.PREFILL:
if scheduler.enable_overlap:
scheduler.event_loop_overlap_disagg_prefill() # 预填充分离+overlap
else:
scheduler.event_loop_normal_disagg_prefill() # 预填充分离+串行
elif disaggregation_mode == DisaggregationMode.DECODE:
if scheduler.enable_overlap:
scheduler.event_loop_overlap_disagg_decode() # 解码分离+overlap
else:
scheduler.event_loop_normal_disagg_decode() # 解码分离+串行
def event_loop_normal(self):
"""A normal scheduler loop."""
while True:
recv_reqs = self.recv_requests() # 通过 recv_requests 接收来自 TokenizerManager 的请求
self.process_input_requests(recv_reqs) # 调用 process_input_requests 处理输入,拆解并注册请求状态
batch = self.get_next_batch_to_run() # Scheduler 调度逻辑构造 batch
self.cur_batch = batch # 记录当前正在运行的 batch
if batch:
result = self.run_batch(batch) # 执行 batch 前向推理
self.process_batch_result(batch, result) # 处理推理输出,更新 token
else:
# When the server is idle, do self-check and re-init some states
self.check_memory() # 内存自检(防爆)
self.check_tree_cache() # Cache 结构健康检查
self.new_token_ratio = self.init_new_token_ratio # 重置新 token 比例
self.maybe_sleep_on_idle() # 若空闲过久,挂起一小段时间
self.last_batch = batch

def handle_generate_request(
self,
recv_req: TokenizedGenerateReqInput,
):
# 判断是否是新会话请求 or 旧会话恢复
# ├─ 是新会话 → 创建 Req 实例 + 赋值 tokenizer
# └─ 是旧会话 → session.create_req()
if (
recv_req.session_params is None
or recv_req.session_params.id is None
or recv_req.session_params.id not in self.sessions
):
......
if (
recv_req.session_params is not None
and recv_req.session_params.id is not None
):
req.set_finish_with_abort(
f"Invalid request: session id {recv_req.session_params.id} does not exist"
)
self._add_request_to_queue(req)
return
else:
# Create a new request from a previous session
session = self.sessions[recv_req.session_params.id]
req = session.create_req(recv_req, self.tokenizer)
if isinstance(req.finished_reason, FINISH_ABORT):
self._add_request_to_queue(req)
return
# 后续步骤中均用到 _add_request_to_queue sauce
# 是否是多模态(image)输入
# ├─ 是 → pad input_ids、扩展 image embedding
# └─ 否 → 正常处理
# 校验输入长度(prompt太长则Abort)
# 设置 logprob_start_len
# 校验 logprob_start_len 合法性
# 限制 max_new_tokens 合法范围(防止越界)
# Init grammar cache for this request
# Grammar Parsing 判断
# ├─ 有 grammar 相关参数 → 从 GrammarBackend 获取缓存或创建新的 Grammar 对象
# └─ 无 grammar 相关参数 → 直接添加到请求队列
def get_next_batch_to_run(self) -> Optional[ScheduleBatch]:
# ==== Step 1: 排除 chunked request,准备 batch 合并 ====
chunked_req_to_exclude = set()
# 如果当前存在 chunked 请求
if self.chunked_req:
chunked_req_to_exclude.add(self.chunked_req) # 将其从 batch 中排除
self.tree_cache.cache_unfinished_req(self.chunked_req) # 将其缓存到 TreeCache,作为可能的 prefix 重用
self.req_to_token_pool.free(self.chunked_req.req_pool_idx) # 释放当前请求使用的 token 分配池索引
# ==== Step 2: 尝试将上一轮 batch 合并进 running_batch ====
if self.last_batch and self.last_batch.forward_mode.is_extend():
# 如果上轮 chunked_req 存在(例如 pipeline 并行残留),也需要排除
if self.last_batch.chunked_req is not None:
chunked_req_to_exclude.add(self.last_batch.chunked_req)
# 从 last_batch 中排除 chunked_req(防止带入重复请求)
last_bs = self.last_batch.batch_size()
self.last_batch.filter_batch(
chunked_req_to_exclude=list(chunked_req_to_exclude)
)
# 如果排除后 batch 变小,标记 running_batch 可继续合并
if self.last_batch.batch_size() < last_bs:
self.running_batch.batch_is_full = False
# 如果还有剩余的 last_batch,可以尝试合并
if not self.last_batch.is_empty():
if self.running_batch.is_empty():
self.running_batch = self.last_batch
else:
self.running_batch.merge_batch(self.last_batch)
# ==== Step 3: 尝试获取新的 prefill batch ====
new_batch = self.get_new_batch_prefill()
# ==== Step 4: 是否需要为 DP-attention 构造预热 batch ====
need_dp_attn_preparation = require_mlp_sync(self.server_args)
# 如果是投机解码模式,且启用了 DP-attn,则需要构造 DP-attn batch
if need_dp_attn_preparation and not self.spec_algorithm.is_none():
new_batch = self.prepare_mlp_sync_batch(new_batch)
need_dp_attn_preparation = new_batch is None # 如果构造失败,记录仍需等待
# ==== Step 5: 返回 batch,优先选择 prefill,否则 decode ====
if new_batch is not None:
# 如果 prefill batch 可用,则优先返回
ret = new_batch
else:
# Run decode
if not self.running_batch.is_empty():
# 否则尝试用 running_batch 继续 decode
self.running_batch = self.update_running_batch(self.running_batch)
ret = self.running_batch if not self.running_batch.is_empty() else None
else:
# 若没有可运行 batch,则返回 None
ret = None
# ==== Step 6: 若仍需 DP-attn batch,则再次 prepare ====
if need_dp_attn_preparation:
ret = self.prepare_mlp_sync_batch(ret)
return ret
def run_batch(
self, batch: ScheduleBatch
) -> Union[GenerationBatchResult, EmbeddingBatchResult]:
.......
# 类型一:模型前向推理逻辑
if self.is_generation:
# 情况一:文本生成模式(self.is_generation=True)
if self.spec_algorithm.is_none(): # 不使用 speculative decoding(标准推理)
# 如果是 pipeline 的最后�一层,输出 logits 和生成 token;否则仅输出隐藏状态
...
self.tp_worker.forward_batch_generation(model_worker_batch)
...
# 情况二:speculative decoding 模式
else:
# 由草稿工作器(draft_worker)执行“推测式生成”,并返回实际接受 token 数
elf.draft_worker.forward_batch_speculative_generation(batch)
...
# 扩展处理参数(用于输出)
# 构造返回结果(GenerationBatchResult)
ret = GenerationBatchResult(
logits_output=logits_output if self.pp_group.is_last_rank else None,
pp_hidden_states_proxy_tensors=(
pp_hidden_states_proxy_tensors
if not self.pp_group.is_last_rank
else None
),
next_token_ids=next_token_ids if self.pp_group.is_last_rank else None,
extend_input_len_per_req=extend_input_len_per_req,
extend_logprob_start_len_per_req=extend_logprob_start_len_per_req,
bid=bid,
can_run_cuda_graph=can_run_cuda_graph,
)
# 类型二:向量嵌入模式(self.is_generation=False)
else:
# 获取 embedding 结果,返回 EmbeddingBatchResult
model_worker_batch = batch.get_model_worker_batch()
embeddings = self.tp_worker.forward_batch_embedding(model_worker_batch)
ret = EmbeddingBatchResult(
embeddings=embeddings, bid=model_worker_batch.bid
)
return ret
process_batch_result() 函数会根据当前 batch 的推理模式(forward_mode)来处理其对应的推理结果:
- Decode 模式:处理输出,更新请求状态,处理标记和概率数据,管理内存,并记录统计信息。
- Extend 模式:处理预填充结果,处理输入标记,并为进一步解码或嵌入做准备。
- 已完成的请求通过 cache_finished_req 缓存,并流式传输到 DetokenizerManager。未完成的请求会被��更新,并循环回 get_next_batch_to_run 进行进一步处理,直至完成。
def process_batch_result(
self,
batch: ScheduleBatch,
result: Union[GenerationBatchResult, EmbeddingBatchResult],
launch_done: Optional[threading.Event] = None,
):
if batch.forward_mode.is_decode(): # 解码阶段
self.process_batch_result_decode(batch, result, launch_done)
elif batch.forward_mode.is_extend(): # 预填充阶段
self.process_batch_result_prefill(batch, result, launch_done)
elif batch.forward_mode.is_idle(): # 当前 batch 是空的或只是调度用占位
if self.enable_overlap:
self.tp_worker.resolve_last_batch_result(launch_done)
self.set_next_batch_sampling_info_done(batch)
elif batch.forward_mode.is_dummy_first(): # 是特殊的“假请求”预热阶段
self.set_next_batch_sampling_info_done(batch)
# 健康检查回应逻辑
......
TpModelWorker
TpModelWorker 负责管理 ModelRunner 的 forward pass 和 token sampling 操作,从而完成由 Scheduler 调度的批次请求。 首先初始化 ForwardBatch,再将其转发至 ModelRunner,并等待 logits_output。
def forward_batch_generation(
self,
model_worker_batch: ModelWorkerBatch,
launch_done: Optional[threading.Event] = None,
skip_sample: bool = False,
) -> Tuple[
Union[LogitsProcessorOutput, torch.Tensor], Optional[torch.Tensor], bool
]:
# 创建 ForwardBatch 实例,将 ModelWorkerBatch 包装成可供模型运行的批次数据结构
forward_batch = ForwardBatch.init_new(model_worker_batch, self.model_runner)
# 当前不是 PP pipeline 中的第一个 rank,需要先从前一个 rank 接收中间表示(hidden states),构造出 PPProxyTensors 对象作为 forward 输入
pp_proxy_tensors = None
if not self.pp_group.is_first_rank:
pp_proxy_tensors = PPProxyTensors(
self.pp_group.recv_tensor_dict(
all_gather_group=self.get_attention_tp_group()
)
)
# 如果当前 rank 是 pipeline 的最后一层
if self.pp_group.is_last_rank:
# 执行 forward 推理,得到 logits,返回是否支持 CUDA Graph
logits_output, can_run_cuda_graph = self.model_runner.forward(
forward_batch, pp_proxy_tensors=pp_proxy_tensors
) # ModelRunner 处理获得logits_output
# 如果传入了同步事件信号(多线程用),表示 forward 完成,释放主线程等待
if launch_done is not None:
launch_done.set()
# 根据是否跳过采样,选择是否调用 sample 方法从 logits 中采样 token
if skip_sample:
next_token_ids = None
else:
# 第【9.5 将加速生成的logits参数返回至 Scheduler】章节用到 sample
next_token_ids = self.model_runner.sample(
logits_output, model_worker_batch
)
# 返回当前 batch 的 logits、采样的 token、以及是否能使用 CUDA Graph
return logits_output, next_token_ids, can_run_cuda_graph
# 若当前不是最后一层 rank,仅需执行前向传播并返回中间表示 proxy tensor
else:
pp_proxy_tensors, can_run_cuda_graph = self.model_runner.forward(
forward_batch,
pp_proxy_tensors=pp_proxy_tensors,
)
# 返回 proxy tensor 给下游 rank,采样由最后一层负责
return pp_proxy_tensors.tensors, None, can_run_cuda_graph
ModelRunner
ModelRunner 初始化 AttentionBackend 并管理加载的模型,以执行 generation 和 embedding 任务的 forward pass。
forward() 对外暴露,供 Scheduler/Detokenizer 等调用
└── 内部调用 _forward_raw()
├── 根据 forward_mode 选择执行路径:
│ ├── is_cuda_graph() → cuda_graph_runner.replay()
│ ├── is_decode() → forward_decode()
│ ├── is_extend() → forward_extend()
│ ├── is_split_prefill() → forward_split_prefill()
│ └── is_idle() → forward_idle()
def forward(
self,
forward_batch: ForwardBatch,
skip_attn_backend_init: bool = False, # 是否跳过注意力后端初始化(可用于缓存或延迟初始化)
pp_proxy_tensors: Optional[PPProxyTensors] = None, # 预处理代理张量(用于管道并行或跨 GPU 推理)
reinit_attn_backend: bool = False, # 是否强制重新初始化 attention backend
split_forward_count: int = 1, # 如果是分段推理,这里定义分段数量
) -> Tuple[Union[LogitsProcessorOutput, PPProxyTensors], bool]: # 返回 (模型输出 or 代理张量, 是否使用 CUDA Graph)
# 标记本次 forward 的 ID(方便分析和调度记录)
self.forward_pass_id += 1
# 记录全局专家分布�(用于调试和性能分析
with get_global_expert_distribution_recorder().with_forward_pass(
self.forward_pass_id,
forward_batch,
):
# 实际执行推理:调用内部方法 _forward_raw
output = self._forward_raw(
forward_batch,
skip_attn_backend_init,
pp_proxy_tensors,
reinit_attn_backend,
split_forward_count,
)
# 若启用了 Expert Parallel Load Balance 管理器,触发结束 hook
if self.eplb_manager is not None:
self.eplb_manager.on_forward_pass_end()
# 返回模型输出,以及是否用了 CUDA Graph
return output
Model 加载权重并执行前向传递 ModelRunner 的 self.model 是 Model class 的一个实例。所有 支持的模型 都可以在 python/sglang/srt/models 中找到。以 Qwen2ForCausalLM 为例。 Qwen2ForCausalLM 的结构如下:
- model:用于前向传递的权重。
- embed_tokens:将 input_ids 转换为 embeddings。
- lm_head:将 hidden states 映射回 vocabulary space。
- logits_processor:处理 logits 以便进一步 sampling 或者 normalization。
- pooler:用于提��取 embeddings 或计算 rewards 的 pooling 机制。
def forward(
self,
input_ids: torch.Tensor, # 输入 token 序列 [B, T]
positions: torch.Tensor, # 每个 token 的位置信息 [B, T]
forward_batch: ForwardBatch, # 包含 kv_cache、mask 等上下文
input_embeds: torch.Tensor = None, # 可选:直接使用 embedding 输入
get_embedding: bool = False, # 是否只获取 embedding(而不是 logits)
pp_proxy_tensors: Optional[PPProxyTensors] = None, # 管道并行的输入缓存
) -> torch.Tensor:
# Step 1:调用主模型结构进行推理,得到隐藏层输出
hidden_states = self.model(
input_ids,
positions,
forward_batch,
input_embeds,
pp_proxy_tensors=pp_proxy_tensors,
)
# Step 2:判断是否为最后一张 GPU(pipeline 并行)
if self.pp_group.is_last_rank:
# Step 3:处理输出(logits 或 embedding)
# 返回 logits(用于下一个 token 的预测)
if not get_embedding:
return self.logits_processor(
input_ids, hidden_states, self.lm_head, forward_batch
)
# 返回 embedding(用于向量化语义检索场景)
else:
return self.pooler(hidden_states, forward_batch)
# Step 4:中间 rank 只做数据转发:
# 如果当前不是最后 rank,说明是 pipeline 中间节点,仅传递 hidden_states
else:
return hidden_states
Qwen2ForCausalLM 中的 forward 函数处理 input IDs,生成用于预测下一个 token 的 logits,或生成用于奖励/嵌入请求的 embeddings:
- 如果 get_embedding 为 True,则通过 pooler 返回 embeddings;
- 否则,使用 logits_processor 计算 并返回。