MLA
DeepSeek 采用的注意力机制为 MLA,具体实现过程分为Normal(不做矩阵吸收)和 Absorb(做矩阵吸收)两种,具体流程如下:
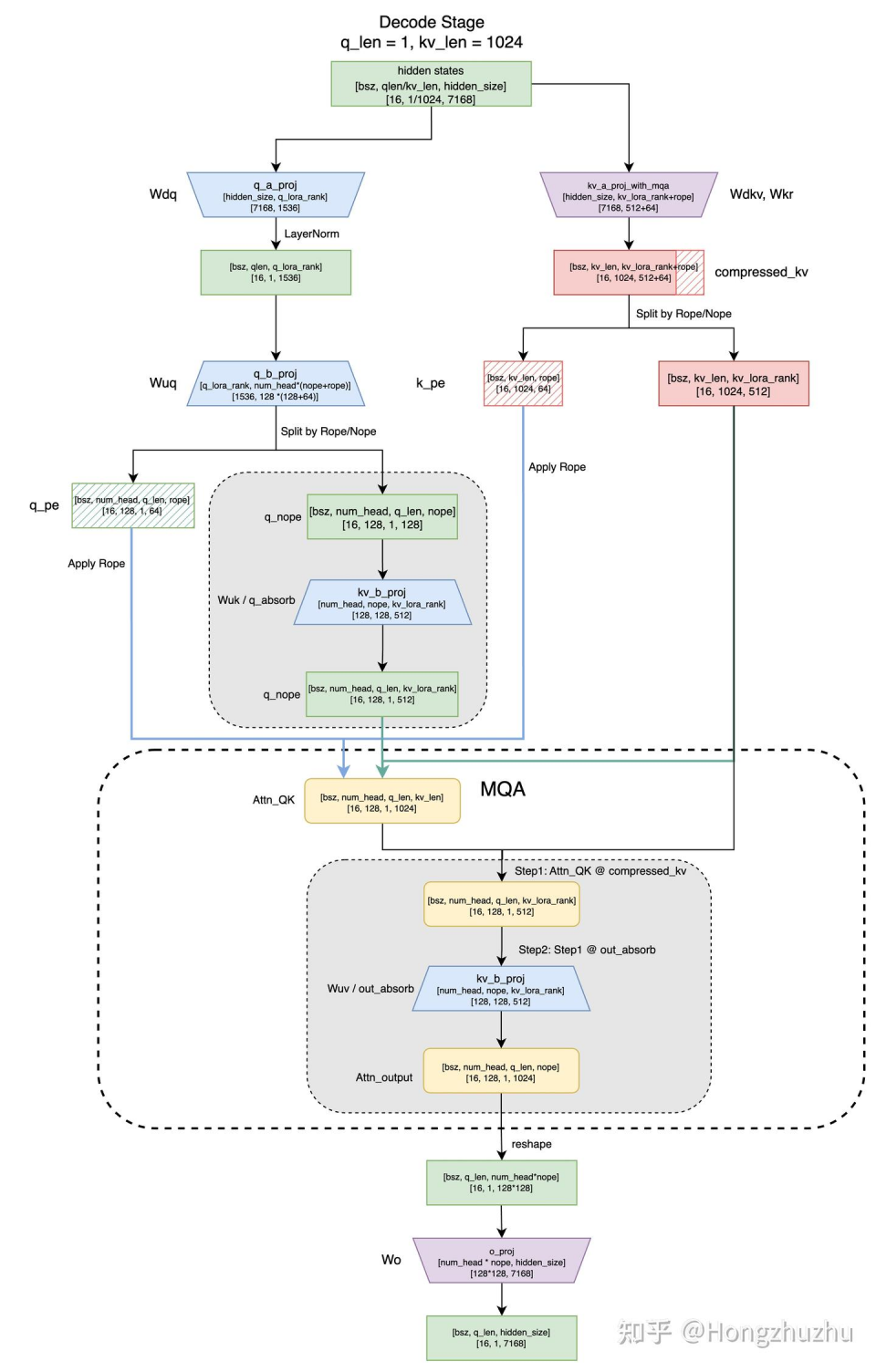
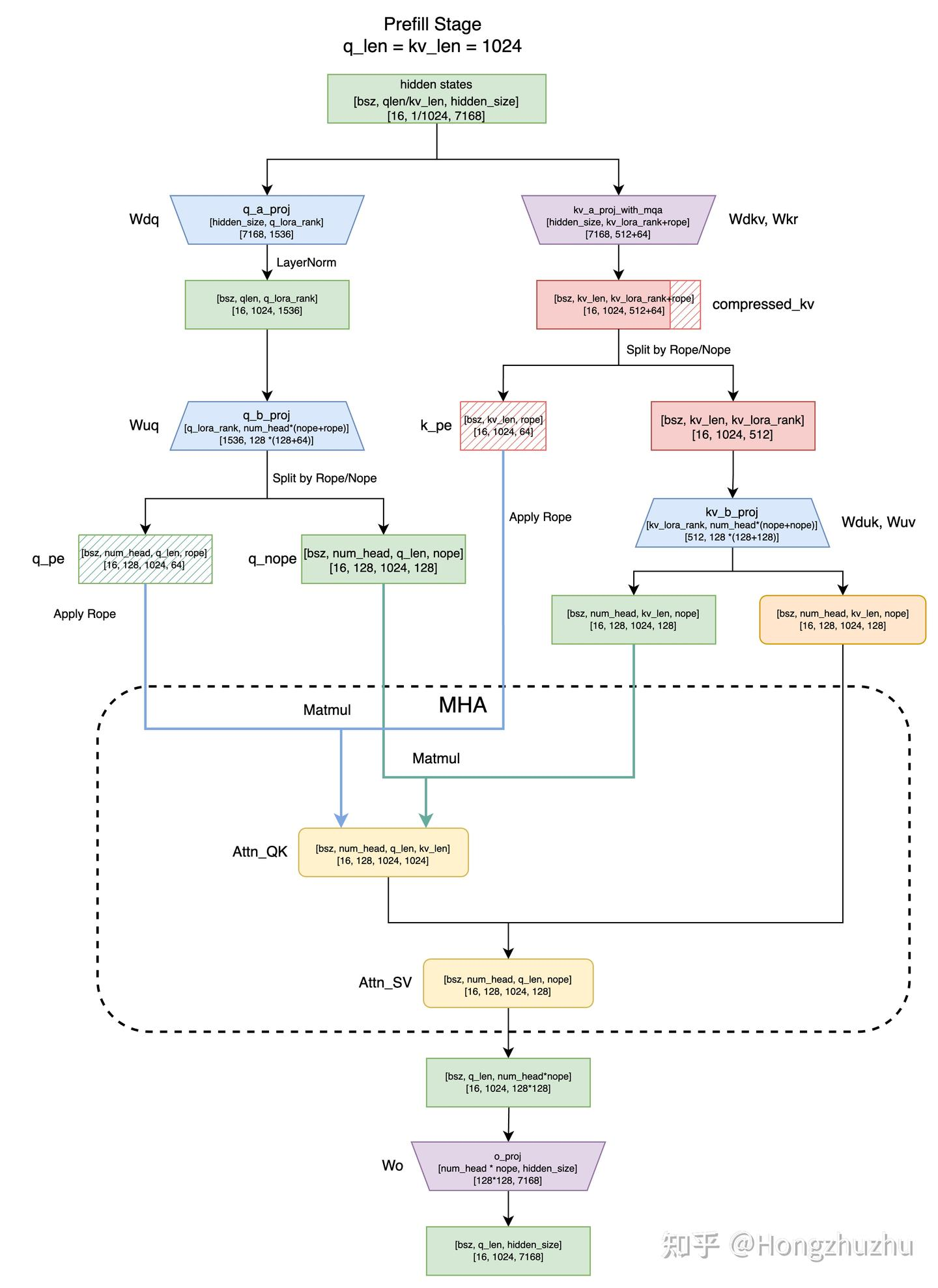
在 sglang 的实现中,根据阶段的不同,在 prefill 阶段和 decode 阶段做了不同的实现。 先不考虑RoPE部分,只考虑从 和 计算 (表示第个 head),具体来讲:prefill 阶段不做权重吸收即采用下面的 Normal 逻辑,而 deocode 阶段做权重吸收即采用下面的 Absorb 逻辑。
prefill 阶段,normal 逻辑的总计算量明显小于 absorb
decode 阶段,normal 逻辑的总计算量明显大于 absorb
FlashMLA
FlashMLA(Flash Multi-Layer Attention) 是由 DeepSeek 提出的一种 基于 Tile 调度与 Triton 加速的高性能注意力机制,目标是替代 FlashAttention 的部分场景,支持 PA64 分页索引、KV Cache + Tile 并行调度,尤其在使用 FP8 精度 时,优化推理阶段速度和显存占用方面更有优势。
PA64是什么?
在 SGLang 框架中,PA64(Page Attention 64) 是 FlashInfer / FlashMLA 注意力机制中使用的一种 tile 化 KV 缓存分页访问结构,它代表每个 KV Cache block 对应 64 个 token,用于在 GPU 上优化 tile-based attention 的执行效率与 memory layout。
在 FlashMLA / FlashInfer 中,将长序列 attention 拆分为 tile,并用每 64 token 为一页的分页方式组织 KV Cache 访问,加速 memory bandwidth 利用,减少 cache miss,支持并行 tile scheduling��。
| 优化目标 | 说明 |
|---|---|
| GPU memory 对齐 | 每 64 个 token 一页,便于使用 32/64-thread warp 并行访问 |
| 提高 cache locality | tile 内 token 顺序连续,减少缓存抖动与 Miss |
| Triton kernel tile scheduling | Triton kernel 以 block 为单位调度,64 token 一组最适合 |
| 支持 streaming attention | 多个请求 KV 混合存储时仍能进行块级定位 |
| Speculative decoding 兼容 | 多步草稿 tile 可直接复用相同索引结构 |
参考: https://zhuanlan.zhihu.com/p/19585986234 https://zhuanlan.zhihu.com/p/25449691772