kv_cache
kv_cache核心数据结构
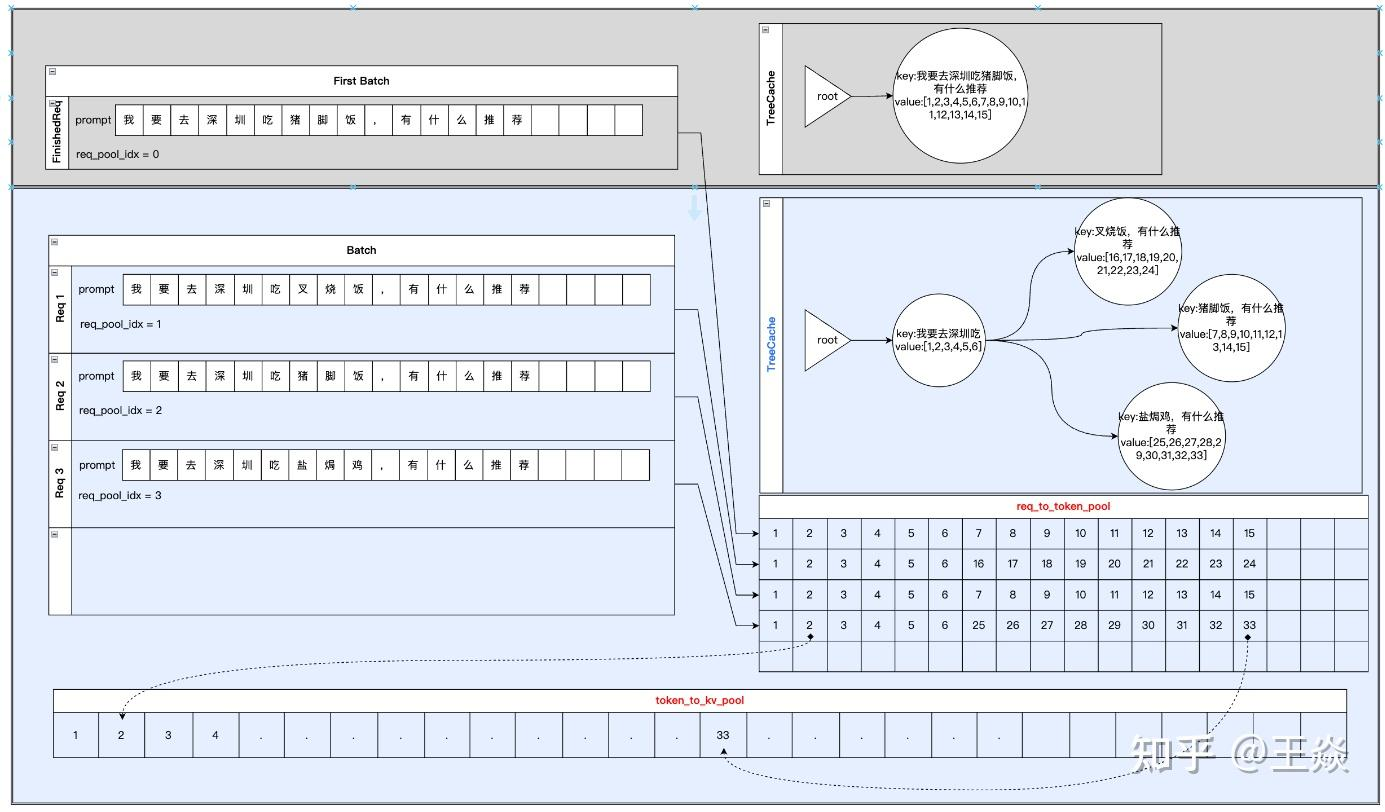 来自:https://zhuanlan.zhihu.com/p/31160183506
来自:https://zhuanlan.zhihu.com/p/31160183506
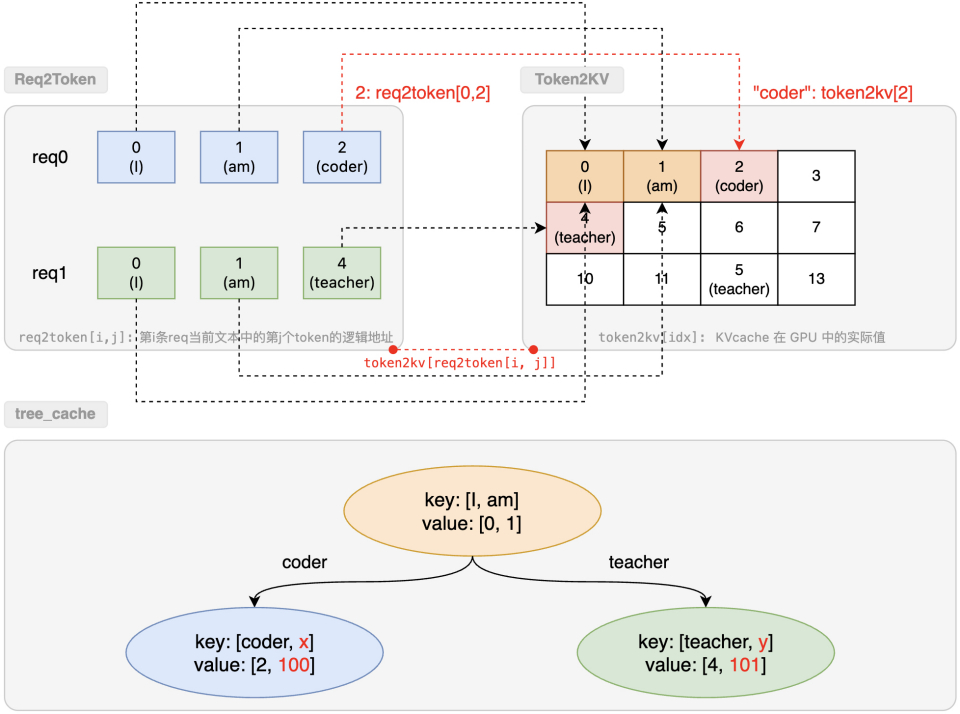
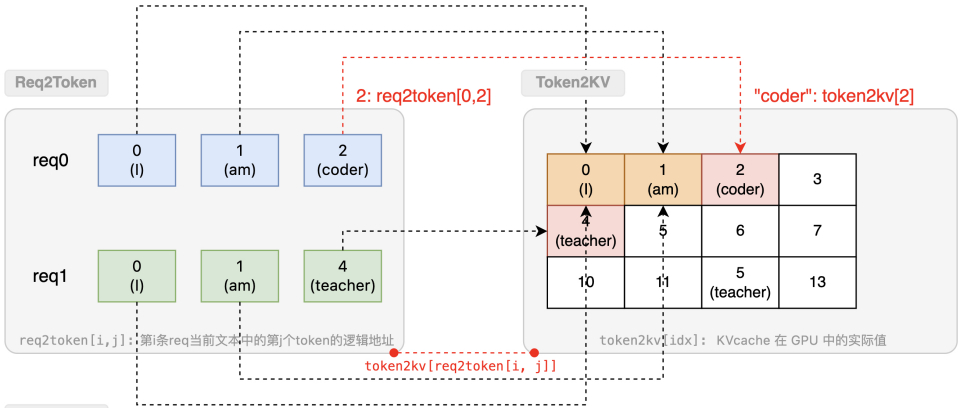
req_to_token_pool
表示 req 到 token 的kv cache 索引的映射关系
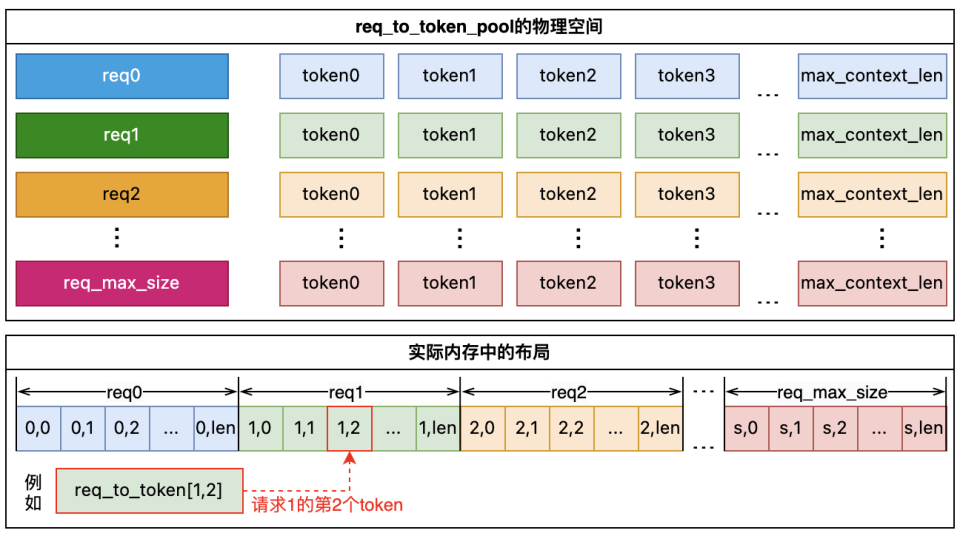
- 形状:最大允许Request数(max-running-requests)* 最大允许 token 数(model_config.context_len)
- 访问方式:out_cache_loc = req_to_token_pool[req1, token0]
- 维度0:req 的索引req_pool_indices
- 维度1:req 中 token 的位置,从 0、1、2 开始
- 返回值:token kv cache 的索引out_cache_loc
计算这个 pool 的大小:req_max_size * max_context_len * sizeof(torch.int32)
- 如果 max_num_reqs = 2048,max_context_len = 128k, 可以算出req_to_token_pool = 2048 * 128k * 4 = 1GB
token_to_kv_pool
将单个token从它的KV cache索引映射到其实际的KV cache数据,管理 token 的逻辑地址到具体 GPU 资源的映射。
- 形状:decoder层数 * 最大允许 token 数 * attention头数 * 每个attention头的维度
- 访问方式:
- cache_k = self.k_buffer[layer][out_cache_loc],
- cache_v = self.v_buffer[layer][out_cache_loc]
- 维度0: 该kv cache对应的模型层数layer_id
- 维度1: token 对应的 kv cache 的索引out_cache_loc(req_to_token_pool的返回值)
- 维度2: 多个注意力头的数量
- 维度3: 每个注意力头的维度
- 返回值:cache_k & cache_v:实际的 KV cache数据
访问第 i 条 req 的第 j 个 token 的 kvcache 的逻辑是:token2kv[req2token[i, j]]。
tree cache
为每个请求在token级别更新req_to_token_pool 和 token_to_kv_pool,以树结构加强跨Request之间的prefix KV cache复用。