PagedTokenToKVPoolAllocator
按“页对齐”(多槽位为一页)分配,支持 prefill/extend 和 decode 的高效批处理。
在alloc中,alloc_extend() 一次性把输入/前缀做完,再 alloc_decode()每一步。
请求进入 → 批量 Extend(一次写完整输入到 KV) → 进入循环:
步1:Decode(采样出 1 token,alloc_decode 分一个地址并写入 KV)
步2:Decode(再采样 1 token,alloc_decode 再分 1 个地址)
...
直到遇到 EOS/长度上限/stop 字符串
| 变量名 | 具体含义 |
|---|---|
| bs(Batch_Size) | 一次同时处理的多个输入请求组成的集合batch大小(多少条请求) |
| prefix_lens | 这批batch运行前,该请求已经写进 KV 的 token 数。(前缀里已经��缓存好的长度) |
| seq_lens | 这批batch运行结束后,希望该请求在 KV 里拥有的总长度。 |
| last_loc | prefix 的最后 1 个 token 的位置 |
| out_indices | 这些 token 最终写入 KV Cache 时,对应的 index 索引 |
| extend_num_tokens | 当前 batch 所有请求在 extend(补全生成)阶段总共要生成多少个 token |
alloc_extend
# prefill/extend 阶段
def alloc_extend(
self,
prefix_lens: torch.Tensor,
seq_lens: torch.Tensor,
last_loc: torch.Tensor,
extend_num_tokens: int,
):
if self.debug_mode:
assert torch.all(
(last_loc + 1) % self.page_size == prefix_lens % self.page_size # 确保下一个token写入槽位和prefill阶段的页大小64对齐
)
bs = len(prefix_lens) # batch_size大小,例如:prefix_lens = torch.tensor([128, 70, 0])
# 创建一个长度为extend_num_tokens的空张量(Tensor),用于保存KV Cache的索引
out_indices = torch.empty(
(extend_num_tokens,), dtype=torch.int64, device=self.device
)
# CUDA kernel 计算:
alloc_extend_kernel[(bs,)](
prefix_lens, # 每个请求前缀长度
seq_lens, # 本轮forward后希望在KV Cache中的总token长度
last_loc, # 每个请求最后一个token所在KV Cache索引的位置
self.free_pages, # 当前可用空闲页
out_indices, # 每个新增 token 的绝对写入索引(跨页时自动跳到新页起始)
self.ret_values, # 64 位统计值,高 32 位编码“新申请页数”
next_power_of_2(bs), # Triton 优化:对 batch size 上取最近的2次幂,方便线程块调度
self.page_size, # 每页的 token 数(常为 64)
next_power_of_2(extend_num_tokens), # Triton 优化:token 扩展数量取整为2次幂,用于批量并行计算 & mask
)
# 唯一性校验:确保out_indices中没有重复索引,即每个token都写到了不同的KV Cache位置。
if self.debug_mode:
assert len(torch.unique(out_indices)) == len(out_indices)
# 从 ret_values 解出“需要新增的页数”:extend分支使用merged_value高32位携带
merged_value = self.ret_values.item()
num_new_pages = merged_value >> 32
# 空闲页不足则失败
if num_new_pages > len(self.free_pages):
return None
# 更新 free_pages:移除已分配的页
self.free_pages = self.free_pages[num_new_pages:]
return out_indices
@triton.jit
def alloc_extend_kernel(
pre_lens_ptr, # tensor[N],每个请求的 prefill 长度
seq_lens_ptr, # tensor[N],每个请求当前 seq 长度(pre + extend)
last_loc_ptr, # tensor[N],每个请求上一次写入的位置
free_page_ptr, # tensor[可用页],存储可用 page 索引
out_indices, # 输出 tensor[总 extend token 数],写入最终 token 的 KVCache 索引
ret_values, # 输出的 packed int64:高 32 位是新分配页数,低 32 位是总 extend token 数
bs_upper: tl.constexpr, # 线程最大数,通常是 batch_size 的 2 的幂
page_size: tl.constexpr, # 页大小,如 64
max_num_extend_tokens: tl.constexpr, # 所有 extend token 最大总数(做 vector 化)
):
# 当前线程 ID:每个 thread 处理一个 batch 内的请求
pid = tl.program_id(0) # 当前线程处理第 pid 个请求
# 批处理预先计算:批量加载 batch 中所有样本的 pre_lens / seq_lens 并计算扩展长度
load_offset = tl.arange(0, bs_upper)
seq_lens = tl.load(seq_lens_ptr + load_offset, mask=load_offset <= pid)
pre_lens = tl.load(pre_lens_ptr + load_offset, mask=load_offset <= pid)
extend_lens = seq_lens - pre_lens
# 取出当前线程对应请求的 pre_len, seq_len,并计算其扩展长度
seq_len = tl.load(seq_lens_ptr + pid)
pre_len = tl.load(pre_lens_ptr + pid)
extend_len = seq_len - pre_len
# 当前�请求的 extend 起始位置 = 所有 extend 总和 - 自身 extend_len
sum_extend_lens = tl.sum(extend_lens)
output_start_loc = sum_extend_lens - extend_len
# 页数计算:以 page_size 对 pre / seq 向上取整
num_pages_after = (seq_lens + page_size - 1) // page_size
num_pages_before = (pre_lens + page_size - 1) // page_size
num_new_pages = num_pages_after - num_pages_before # 新增的页数 = 现在需要的页 - 之前已经占用的页
# 计算当前请求的页分配开始偏移(在所有新增页中的起点)
num_page_start_loc_self = (seq_len + page_size - 1) // page_size - (
pre_len + page_size - 1
) // page_size
sum_num_new_pages = tl.sum(num_new_pages)
new_page_start_loc = sum_num_new_pages - num_page_start_loc_self
# 返回总值(最后一个线程执行)
if pid == tl.num_programs(0) - 1:
# 高 32 位保存 sum_num_new_pages:表示此次 extend 需要申请多少个新的 page;
# 低 32 位保存 sum_extend_lens:此次 extend 实际写入了多少个 token(通常等于 seq - pre 总和)
merged_value = (sum_num_new_pages.to(tl.int64)) << 32 | sum_extend_lens.to(
tl.int64
)
tl.store(ret_values, merged_value)
# 写入 KVCache 的索引(三段式)
# Part 1: 填充旧页中剩余空间
last_loc = tl.load(last_loc_ptr + pid)
num_part1 = (
min(seq_len, (pre_len + page_size - 1) // page_size * page_size) - pre_len
)
offset_one_page = tl.arange(0, page_size)
tl.store(
out_indices + output_start_loc + offset_one_page,
last_loc + 1 + offset_one_page,
mask=offset_one_page < num_part1,
)
if pre_len + num_part1 == seq_len: # 若填满了,提前 return
return
# Part 2: 填充新的完整页
num_part2 = (
seq_len // page_size * page_size
- (pre_len + page_size - 1) // page_size * page_size
) # num_part2:当前样本中要新分配的完整页的 token 数
# 可写整页的 token 数
offset_many_page = tl.arange(0, max_num_extend_tokens)
page_start = tl.load(
free_page_ptr + new_page_start_loc + offset_many_page // page_size,
mask=offset_many_page < num_part2,
)
tl.store(
out_indices + output_start_loc + num_part1 + offset_many_page,
page_start * page_size + offset_many_page % page_size,
mask=offset_many_page < num_part2,
) # 将多个整页 token 的 KVCache 索引写入 out_indices
if pre_len + num_part1 + num_part2 == seq_len:
return # 将多个整页 token 的 KVCache 索引写入 out_indices
# Part 3: 填充新尾页的部分 token
num_part3 = seq_len - seq_len // page_size * page_size
start_loc = tl.load(
free_page_ptr + new_page_start_loc + num_page_start_loc_self - 1
)
tl.store(
out_indices + output_start_loc + num_part1 + num_part2 + offset_one_page,
start_loc * page_size + offset_one_page,
mask=offset_one_page < num_part3,
)
pre 和 seq 到底是什么?
对分配器(PagedTokenToKVPoolAllocator)以及ScheduleBatch.prepare_for_extend/prepare_for_decode:
-
pre(= pre_len / prefix_lens[i])
- 这批运行之前,该请求已经写进 KV 的 token 数。
- 也就是“前缀里已经缓存好的长度”。
-
seq(= seq_lens[i])
- 这批运行结束后,希望该请求在 KV 里拥有的总长度。
- 所以这批需要新写入的数量 =extend_len = seq - pre(在 extend 阶段);
- 在 decode 阶段,seq = pre + 1(每步只长 1)。
-
last_loc
- pre 阶段传入的last_loc[i]是第 pre 个 token 的物理位置 - 1(也就是“上一个 token”的位置)。
- 代码里有断言:(last_loc + 1) % page_size == pre % page_size,确保“下一写入槽位”和 pre 的模 64 对齐。 😲😲😲😲😲
计算例子
Prefill阶段
假设有两个请求A和B,当前批要做 extend:
-
请求A:pre = 70,seq = 190
- pre%64 = 6,说明“第 70 个 token”落在“某一页”的第 6 个偏移(从 0 算)。
- A 本批要写seq-pre = 120个新 token。
-
请求B:pre = 128,seq = 260
- pre%64 = 0,恰好落在页边界。
- B 本批要写132个新 token。
公式回忆:ceil()向上取整,floor()向下取整
- Part1(补齐旧页尾):num_part1 = min(seq, ceil(pre/64)*64) - pre
- Part2(中间整页):num_part2 = floor(seq/64)*64 - ceil(pre/64)*64
- Part3(末尾半页):num_part3 = seq - floor(seq/64)*64
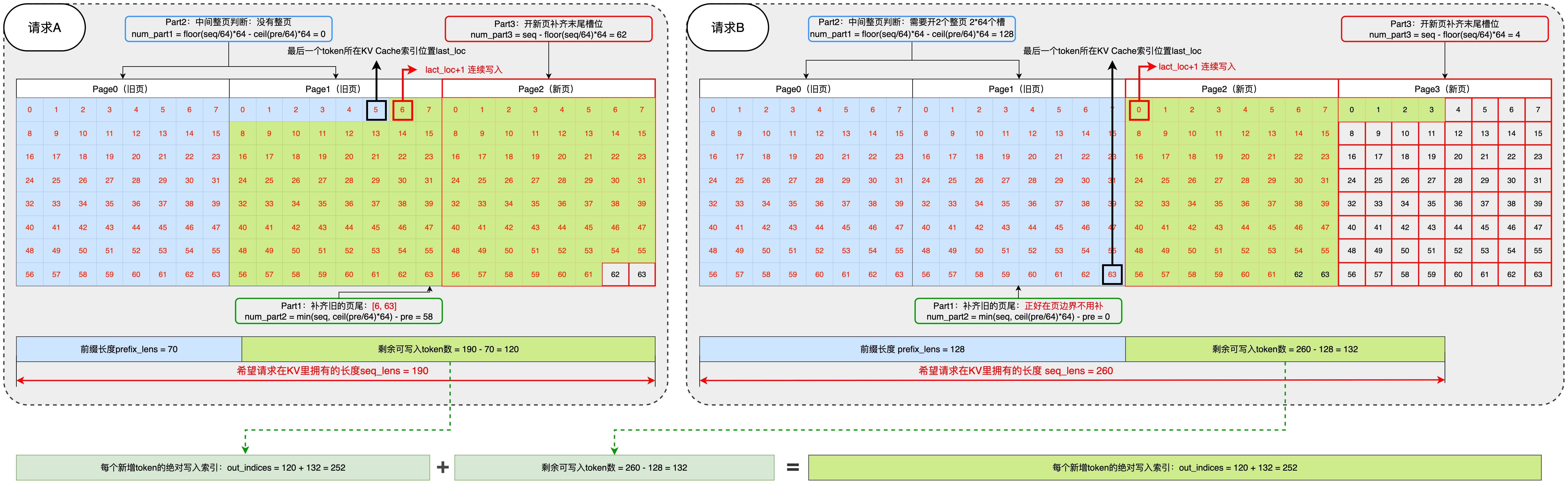
请求A 的分配过程(alloc_extend里的 3 段)
对A(pre=70, seq=190):
-
ceil(pre/64)*64 = ceil(70/64)*64 = 128
-
floor(seq/64)*64 = floor(190/64)*64 = 128
-
Part1:min(190, 128) - 70 = 58
- 含义:把 **pre=70 所在的“旧页”**剩下的 58 个槽位写满(直到 127)。
- 不占用新页,直接用last_loc+1 ..连续写。
-
Part2:128 - 128 = 0(中间没有整页)
-
Part3:190 - 128 = 62
- 需要新开 1 页,写 62 个槽(从该新页的偏移 0..61)。
A 小结:
- 不拿新页就写掉 58 个(把旧页补满至 127);
- 再拿 1 个新页,写 62 个(偏移 0..61)。
请求B 的分配过程(alloc_extend里的 3 段)
对B(pre=128, seq=260):
-
ceil(pre/64)*64 = 128
-
floor(seq/64)*64 = 256
-
Part1:min(260, 128) - 128 = 0(因为 pre 正好在页边界,不用补半页)
-
Part2:256 - 128 = 128
- 需要新开 2 页整页,每页 64 个,共 128 个槽。
-
Part3:260 - 256 = 4
- 再新开 1 页,写前 4 个槽(偏移 0..3)。
B 小结:
- 先拿 2 个整页(写满 128 个);
- 再拿 1 个新页,写 4 个。
- alloc_extend会把A 的 58 + 62和B 的 128 + 4按样本顺序拼成一条一维 out_indices:[A 的 58 槽(旧页连续) | A 的 62 槽(新页前 62) | B 的 128 槽(两页整) | B 的 4 槽(新页前 4)]
- 分配器内部还会一次性从free_pages里“扣掉”A 的新页 1 个+B 的新页 3 个。
上层随后会把这个out_indices写进req_to_token_pool(把“第 t 个 token 在 KV 里的物理位置”登记好),然后注意力后端(FlashMLA 等)用这些位置把K/V真正写入 KV Cache。
代码路径
- Extend 路径:
ScheduleBatch.prepare_for_extend()→alloc_paged_token_slots_extend(...)→TokenToKVPoolAllocator.alloc_extend(...)(页式)→alloc_extend_kernel(Triton 内核里按 3 段生成 out_indices)
- Decode 路径:
ScheduleBatch.prepare_for_decode()(先把seq_lens += 1)→alloc_paged_token_slots_decode(...)→TokenToKVPoolAllocator.alloc_decode(...)(页式)→alloc_decode_kernel(Triton 内核里判定是否跨页,返回每条 1 个地址)