调��度策略
v0.5.5
概览
- Scheduler调度策略
接收请求->处理请求->组建批次->前向推理->结果处理
Req -> Waiting_queue -> ScheduleBatch -> ModelWorkerBatch -> TPWorker -> ModelRunner -> GenerationBatchResult -> BatchTokenIDOutput
- 动态组织Batch
Req -> waiting_queue -> new_batch -> running_batch
- 分配KV Cache资源
Scheduler两级内存池管理策略: ReqToTokenPool 和 TokenToKVPool, 同时采用tree_cache结合两级内存池来增强跨Request的前缀KV Cache复用。
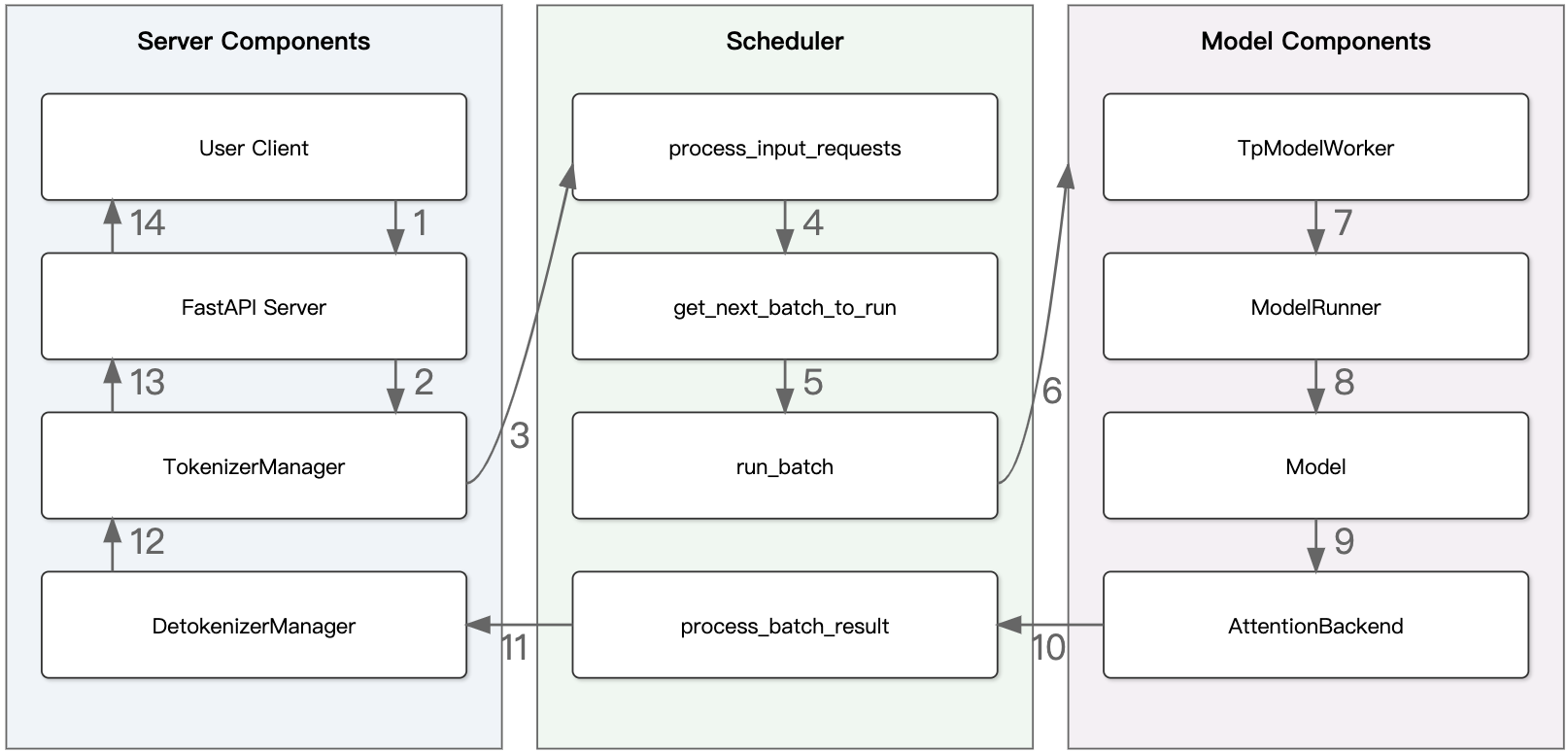
TokenizerManager 和 DetokenizerManager 之间就是Scheduler处理。Scheduler 是 SGLang 的推理调度核心(类似交通系统中的红绿灯),负责在 Prefill 与 Decode 阶段间动态组织批次与分配资源,实现高效并行和低延迟推理。
动态组Batch
Scheduler 通过事件循环函数event_loop_normal / event_loop_overlap实现推理调度策略
- 对于未完成的请求,Scheduler 继续其事件循环��,直到这个请求满足结束条件;
- 对于已完成的请求,则转发到 Scheduler 的 stream_output 将其包装成 BatchTokenIDOut,并发送给 DetokenizerManager。
- 接收请求:通过recv_requests 接收请求,按照DP/TP/PP/Attention-TP 策略广播同步到当前所有计算 Rank 中,生成本轮调度可用的请求列表;
- 处理请求:调用 process_input_requests 处理输入,通过 handle_generate_request 管理生成请求的逻辑,并将 Req 加入 waiting_queue;
- 组建批次:使用get_next_batch_to_run 从waiting_queue取出请求,进而为这些即将处理的请求创建 ScheduleBatch;
- 前向推理:执行 run_batch 函数,将 ScheduleBatch 转换为 ModelWorkerBatch,进而让 TPworker 调用 ModelRunner 完成推理,构造返回结果;
- 结果处理:通过 process_batch_result 处理结果,使用 tree_cache.cache_finished_req(req) 缓存请求,并通过 check_finished 验证完成状态。
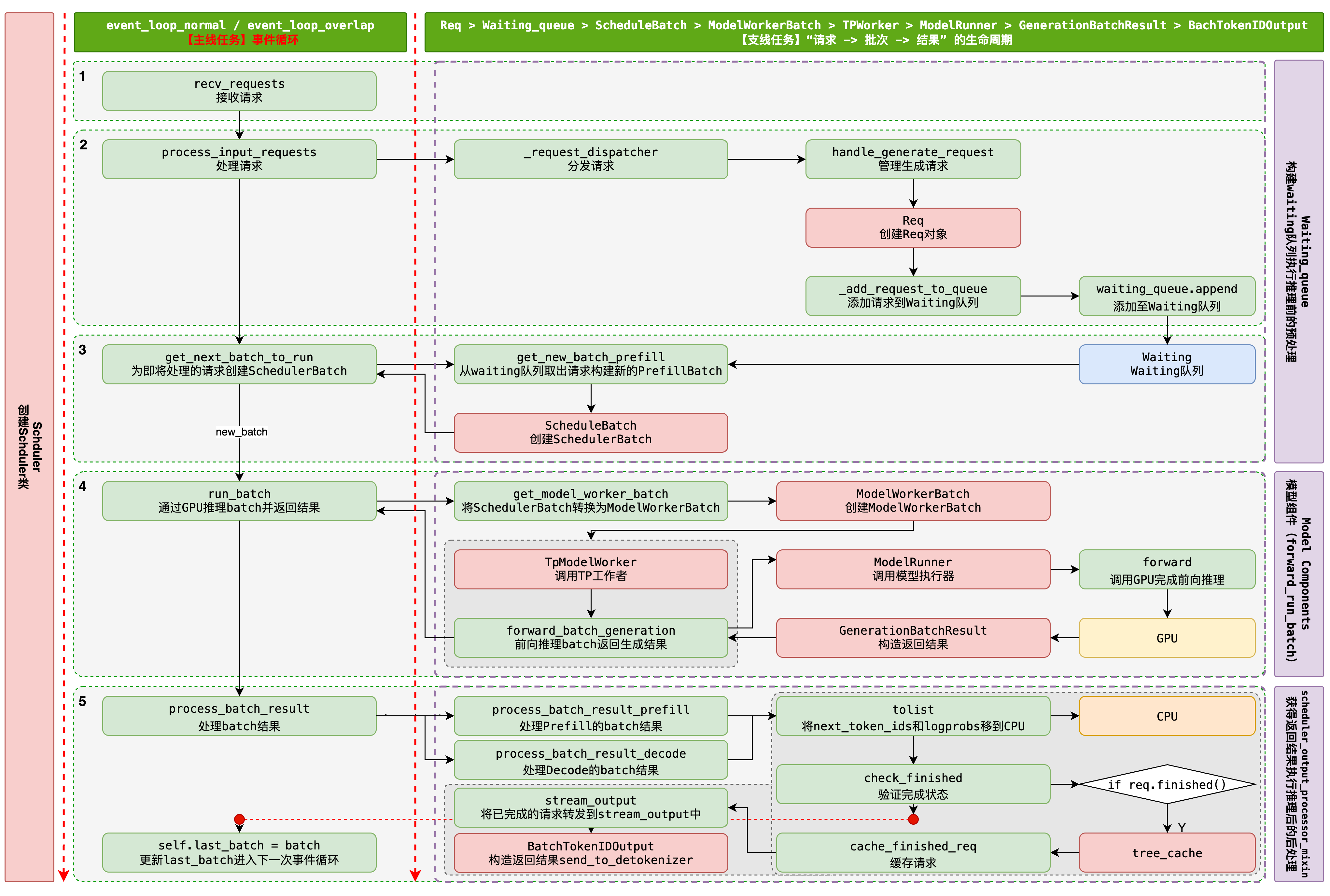
为啥在流程中搞个waiting_queue? 因为要动态组织Batch,就会考虑到请求的优先级,以及请求的等待时间,如何组织成batch。
请求来了push到waiting queue中,loop调度的时候选择合适的请求组成batch。
Retracted:如果decode期间可用内存不足,Scheduler会通过 retract_decode 从 running_batch 中撤回某些Request,将其返回到 waiting_queue 以供后续处理。
请求在给Scheduler调度处理的过程中,主要受到waiting_queue 、 new_batch、running_batch与cur_batch这4个变量的影响。
- 其中waiting_queue 是Python列表,new_batch、running_batch与cur_batch都是ScheduleBatch类的实例。
- Scheduler 将请求从 waiting_queue 过渡到 new_batch(用于prefill/extend阶段),然后进入 running_batch(用于decode阶段)
如果遇到内存不足,Request会被chuncked(prefill/extend)或再retracted(decode),然后重新插入 waiting_queue 以供后续处理。
Req -> waiting_queue -> new_batch -> running_batch生命周期
-
新请求到达:核心函数recv_requests收集新到达请求,并放入waiting_queue
-
合并批次:cur_batch(i-1)合并到running_batch(i)中,并移除上一轮的 being_chunked_request
-
形成新批次:选择时new_batch还是running_batch
- new_batch:从 waiting_queue 中拉取请求并创建一个new_batch,将new_batch用作cur_batch
- running_batch:如果没有new_batch,running_batch将被过滤用作cur_batch。
-
运行批次:一旦确定了 全局批次,调用run_batch执行一次前向传递
-
结果处理:在run_batch之后,调用process_batch_result来确定已完成/继续进行的请求。
-
迭代:循环重复,直到所有请求最终完成。
分配KV Cache资源
IN_BATCH调度策略
在选择新到的 prefill 请求时,根据其前缀匹配的长度进行调度,选择前缀相同的请求越多,GPU 资源利用率就越高。
def get_new_batch_prefill(self) -> Optional[ScheduleBatch]:
# Get priority queue
self.policy.calc_priority(self.waiting_queue)
# Prefill policy
adder = PrefillAdder(
self.page_size,
self.tree_cache,
self.token_to_kv_pool_allocator,
self.running_batch,
self.new_token_ratio,
self.max_prefill_tokens,
self.chunked_prefill_size,
running_bs if self.is_mixed_chunk else 0,
)
in batch 优化:
- 如果一个 req 的在全局的前缀请求很长,那么直接执行绝对很好。
- 如果一个 req全局的前缀没那么长,但是在当前这一个 batch 中,有很多 req 他们之间匹配到了很多前缀,那��么我们可以从当前 batch 有相同前缀的 reqs 中只选一个执行,而其他的都不执行,这么做可以提高缓存命中率。
_compute_prefix_matches函数中实现,有两个核心变量,即上图的CHECK_THRESHOLD和DEPRIORITIZE_THRESHOLD。
_compute_prefix_matches函数会返回一个temporary_deprioritized列表,里面代码了in_batch 优化时,选中的请求,比如2、3请求,就会加入temporary_deprioritized列表。
在calc_priority函数中会对waiting_queue进行重新排序,将temporary_deprioritized列表中的请求降级,让其优先级降低。
temporary_deprioritized = self._compute_prefix_matches(
waiting_queue, policy
)
if policy == CacheAwarePolicy.LPM:
SchedulePolicy._sort_by_longest_prefix(
waiting_queue, temporary_deprioritized
)
在遍历waiting_queue构造prefill请求的时候,会通过排序的时候降级,让这些请求靠后,先不加入到prefill请求中。
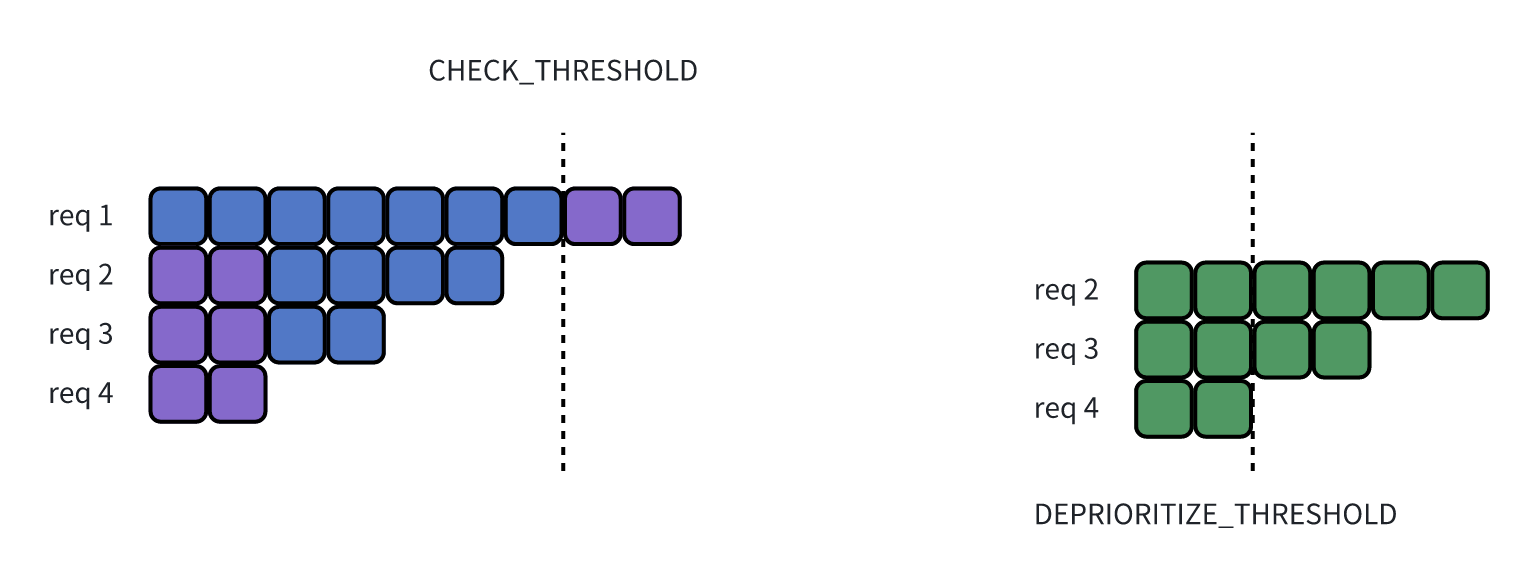
IN_BATCH_PREFIX_CACHING_CHECK_THRESHOLD:如果 req 在全局中的前缀匹配大于这个阈值,直接执行,不做 in batch 优化。如果小于这个阈值,则开启 inbatch 匹配,看 batch 内 部是否有重复前缀。上图中的 req1 即直接执行,req 2、3、4 要做 inbatch 的优化。
IN_BATCH_PREFIX_CACHING_DEPRIORITIZE_THRESHOLD:如果 inbatch 内的阈值小于这个,那就证明前缀匹配的太短了,我们就没必要做优化。比如英文中常见的"i am","the"这种常见短词。上图中 req2、req3 进行 in batch 优化,但是 req4 太短了,不进行 in batch 优化。
例子:
from typing import List
class Req:
def __init__(self, value):
self.value = value
def __repr__(self):
return f'Req({self.value})'
que = List[Req]
que = [
Req(3),
Req(1),
Req(4),
Req(2),
]
deprioritized = [4] # 降级了,优先级靠后
que.sort(
key = lambda r: (
-r.value
if r.value not in deprioritized
else float('inf')
)
)
print(que)
mlist = [2,1, 3, 4,0]
mlist.sort(
key = lambda r: (
r
)
)
print(mlist)
# [Req(3), Req(2), Req(1), Req(4)]
# [0, 1, 2, 3, 4]
scheuler 接收请求
┌─────────────────────────────────────────────────────────────────┐
│ recv_requests() │
├─────────────────────────────────────────────────────────────────┤
│ 1. PP Rank 0 (第一阶段): │
│ ├── attn_tp_rank == 0: 从 tokenizer/RPC 接收请求 │
│ └── attn_tp_rank != 0: recv_reqs = None │
│ │
│ 2. PP Rank > 0 (其他阶段): │
│ ├── attn_tp_rank == 0: 从上一个 PP rank 接收 │
│ └── attn_tp_rank != 0: recv_reqs = None │
│ │
│ 3. 请求分发 (根据并行策略): │
│ ├── 启用 DP Attention: 分别广播 work_reqs 和 control_reqs │
│ └── 仅启用 TP: 广播所有请求到 tp_group │
└─────────────────────────────────────────────────────────────────┘
多阶段接收:支持流水线并行(PP),不同阶段的 scheduler 接收上一阶段的输出 多源接收:支持从 tokenizer 服务和 RPC 多个来源接收请求 DP Attention 优化:将计算密集型请求(work_reqs)和控制请求分离,分别在不同并行组内广播,减少通信开销
tokenizer _communicator:
class _Communicator(Generic[T]):
"""Note: The communicator now only run up to 1 in-flight request at any time."""
┌─────────────────────────────────────────────────────────────────┐
│ __call__(obj) - 发送请求 │
├─────────────────────────────────────────────────────────────────┤
│ 1. 检查是否有进行中的请求或排队请求: │
│ if self._result_event is not None or len(self._ready_queue) > 0│
│ └── 加入等待队列,等待被唤醒 │
│ │
│ 2. 发送请求: │
│ if obj: self._sender.send_pyobj(obj) │
│ │
│ 3. 等待响应: │
│ 创建 _result_event,阻塞等待直到收到 fan_out 个响应 │
│ │
│ 4. 返回结果并唤醒下一个等待者: │
│ return result_values │
│ if len(self._ready_queue) > 0: 唤醒队列中的下一个请求 │
└─────────────────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────────────────┐
│ handle_recv(recv_obj) - 接收响应 │
├─────────────────────────────────────────────────────────────────┤
│ 1. 收集响应: │
│ self._result_values.append(recv_obj) │
│ │
│ 2. 判断是否完成: │
│ if len(self._result_values) == self._fan_out: │
│ self._result_event.set() # 唤醒等待中的 __call__ │
└─────────────────────────────────────────────────────────────────┘
流控:限制同时只有 1 个请求进行,避免资源竞争 顺序保证:通过 _ready_queue 确保请求按顺序处理(FIFO) 扇出聚合:等待多个接收者(fan_out)的响应全部到达后,再返回结果 异步非阻塞:使用 asyncio.Event 实现高效的等待/唤醒机制