pd�分离实现
https://docs.google.com/document/d/1rQXJwKd5b9b1aOzLh98mnyMhBMhlxXA5ATZTHoQrwvc/edit?pli=1&tab=t.0
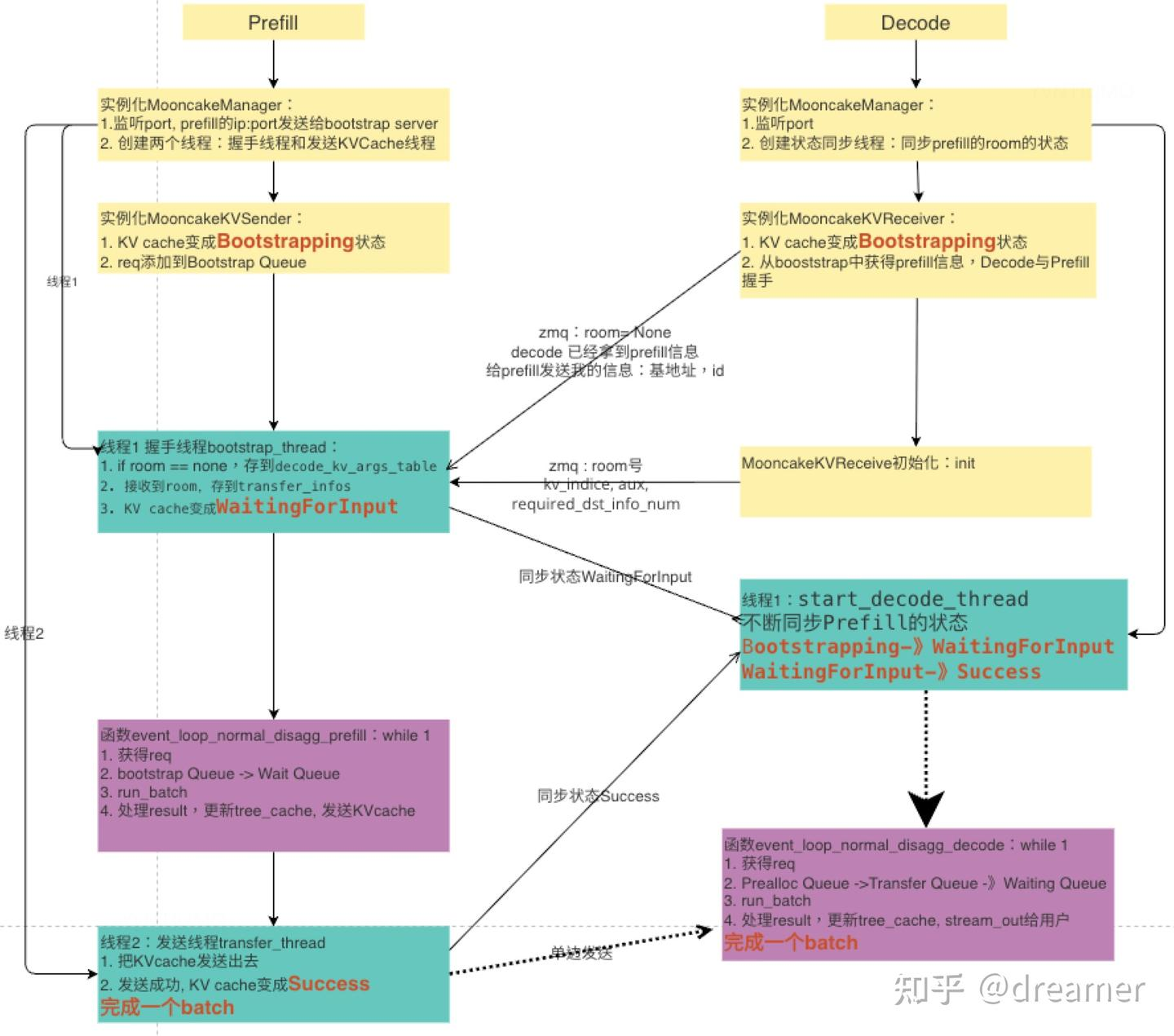
sglang 的核心调度逻辑是在 Scheduler 的事件循环中实现的。额外加入了 非阻塞的发送端(sender)与接收端(receiver)操作。 对于 P 节点,在原先的 waiting_queue 的基础上,又添加了 disagg_prefill_bootstrap_queue 和 disagg_prefill_inflight_queue,队列的作用如下:
-
Bootstrap Queue:存放等待 PD 节点配对的请求
- 为每个请求初始化一个 Sender
- 轮询发送者以检查 Bootstrap 状态
- 一旦 Bootstrap 完成,将请求移至 Waiting Queue
-
Waiting Queue:存放待 forword 的请求
- 使用 PrefillAdder 弹出请求
- 运行 forward
- 将请求添加到 Inflight Queue
-
Inflight Queue:存放正在进行 kv cache 传输的请求
- 对请求的发送者进行非阻塞轮询
- 一旦传输完成,返回该请求
对于 D 节点,添加了 disagg_decode_prealloc_queue,disagg_decode_transfer_queue,作用如下:
-
PreallocQueue:存放等待 PD 节点配对的请求
- 为每个请求初始化一个 receiver
- 请求首先进行握手,一旦有可用的空间,就执行 KV 预分配
- 握手完成后,将请求移至 TransferQueue
-
TransferQueue:正在传输的请求
- 轮询 receiver 以检查传输状态
- 如果传输完成,将请求移至 WaitingQueue
-
WaitingQueue
- 使用队列中的请求构建 PrebuiltExtendBatch
- 跳过 Prefill forward,仅填充元数据
- 将已解析的 PrebuiltExtendBatch 合并到 RunningBatch 中以执行解码
sglang PD 分离需要启用一个 load balancer 负责选择 P D 节点对发送请求。load balancer 收到请求后,将根据选择的 PD 节点在请求中加入 bootstrap_host(选中的P节点的地址),bootstrap_port(P节点的 KVBootstrapServer 的端口),bootstrap_room(一个整数,用于标识 PD 节点对) 三个参数,并将请求分别发往 P,D 节点,然后等待 D 节点返回。P 服务器将返回空响应。所有的 token 由 D 服务器返回。
不同TP per DP的传输策略
MLA通过低秩压缩将KV缓存极度“瘦身”,但其压缩后的核心“潜在向量”(Latent Vector)在TP视角下是一个不可分割的整体,导致每个TP rank都必须存一份才能完成各自的计算
在 MLA Attention 下面,每个 tp 的 kv cache 都是一样的,因此可以实现不同 tp per dp 的 PD 分离传输。分为三种情况: 设P节点TP=n,D节点TP=m
- n = m,直接点到点传输即可
- n > m,则 P 节点只需要选择 m 个 TP 与 D 节点配对,点对点传输即可
- n < m,此时 P 节点一个 TP 需要负责传输多个 TP
SGLang给出了一个标准的PD分离方案实现,prefill得到所有层的kv cache,然后一次性发送给decode,prefill的第一个token不会直接返回给proxy,而是交给decode继续处理。对于KV cache的存储,其实也是交给prefill和decode自己,尚未利用mooncake的store,也就是P2P的KV cache存储方案。
some function
def group_concurrent_contiguous(
src_indices: npt.NDArray[np.int32], dst_indices: npt.NDArray[np.int32]
) -> Tuple[List[npt.NDArray[np.int32]], List[npt.NDArray[np.int32]]]:
"""Vectorised NumPy implementation."""
if src_indices.size == 0:
return [], []
brk = np.where((np.diff(src_indices) != 1) | (np.diff(dst_indices) != 1))[0] + 1
src_groups = np.split(src_indices, brk)
dst_groups = np.split(dst_indices, brk)
src_groups = [g.tolist() for g in src_groups]
dst_groups = [g.tolist() for g in dst_groups]
return src_groups, dst_groups
这个函数的作用是将连续递增的索引对分组。
src_indices: 源索引数组dst_indices: 目标索引数组
brk = np.where((np.diff(src_indices) != 1) | (np.diff(dst_indices) != 1))[0] + 1
这行代码找出"断点"位置——即 src_indices 或 dst_indices 不再连续递增的位置。
执行过程示例
假设输入:
src_indices = [0, 1, 2, 10, 11, 20]
dst_indices = [5, 6, 7, 15, 16, 25]
np.diff(src_indices)→[1, 1, 8, 1, 9]np.diff(dst_indices)→[1, 1, 8, 1, 9]- 断点条件:差值不等于1的位置 → 索引2和索引4处
brk→[3, 5]- 分组结果:
src_groups:[[0,1,2], [10,11], [20]]dst_groups:[[5,6,7], [15,16], [25]]
这个函数通常用于 KV Cache 的内存拷贝优化。当需要从源位置复制到目标位置时,将连续的索引合并成组,可以:
- 减少内存拷贝操作次数
- 提高批量传输效率 例如在 disaggregation(分离式推理)场景中,将 KV Cache 从一个节点的连续位置迁移到另一个节点的连续位置时,可以按组进行批量传输。
在sglang的send_kvcache函数中调用。
if self.is_mla_backend or (
local_tp_size == target_rank_registration_info.dst_tp_size
):
ret = self.send_kvcache(
...
)
else:
ret = self.send_kvcache_slice(
...
)
send_kvcache 是 TP 对齐时的高效整页传输路径;send_kvcache_slice 是 TP 不对齐时的通用路径,需要在 head 维度上精确切片,以正确地将 KV cache 从一种 TP 分布映射到另一种。
refer
https://zhuanlan.zhihu.com/p/1912106909617624371 https://zhuanlan.zhihu.com/p/1924856844867867827